In October of 2024, I was invited by Dr Lydia C. and Dr Peng C to give two presentations as a guest lecturer at La Trobe University (Melbourne) to the students enrolled with CSE5DMI Data Mining and CSE5ML Machine Learning.
The lectures are focused on data mining and machine learning applications and practice in industry and digital retail; and how students should prepare themselves for their future. Attendees are postgraduate students currently enrolled in CSE5ML or CSE5DMI in 2024 Semester 2, approximately 150 students for each subject (CSE5ML or CSE5DMI) who are pursuing one of the following degrees:
This repository is intended for educational purposes only. The content, including presentations and case studies, is provided “as is” without any warranties or guarantees of any kind. The authors and contributors are not responsible for any errors or omissions, or for any outcomes related to the use of this material. Use the information at your own risk. All trademarks, service marks, and company names are the property of their respective owners. The inclusion of any company or product names does not imply endorsement by the authors or contributors.
This is public repository aiming to share the lecture for the public. The *.excalidraw files can be download and open on https://excalidraw.com/)
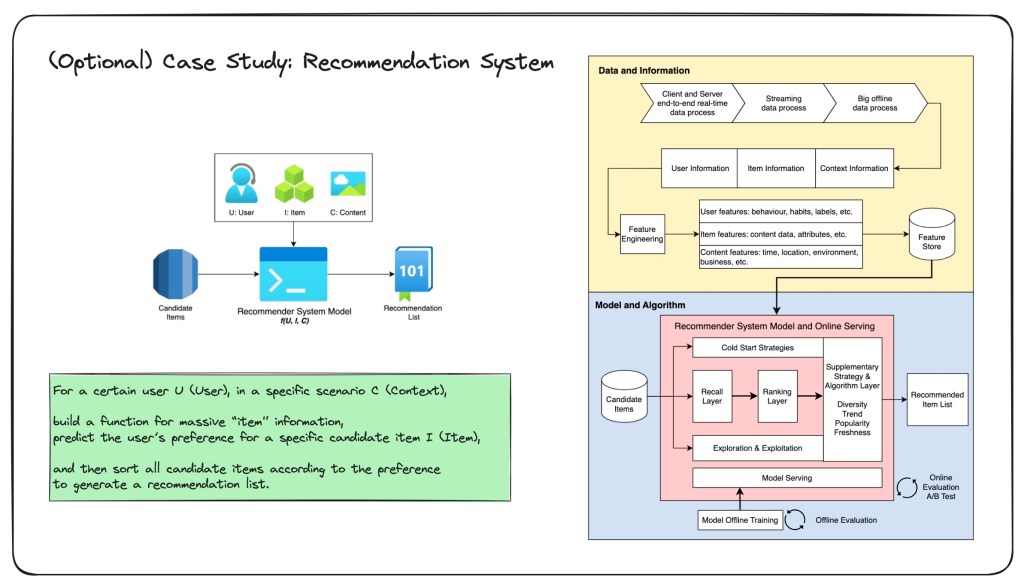
A recommendation system is an artificial intelligence or AI algorithm, usually associated with machine learning, that uses Big Data to suggest or recommend additional products to consumers. These can be based on various criteria, including past purchases, search history, demographic information, and other factors.
This presentation is developed for students of CSE5ML LaTrobe University, Melbourne and used in the guest lecture on 2024 October 14.
Entity matching – the task of clustering duplicated database records to underlying entities.”Given a large collection of records, cluster these records so that the records in each cluster all refer to the same underlying entity.”
This presentation is developed for students of CSE5DMI LaTrobe University, Melbourne and used in the guest lecture on 2024 October 15.
Contribution to the Company and Society
This journey is also align to the Company’s strategy.
Being invited to be a guest lecturer for students with related knowledge backgrounds in 2024 aligns closely with EDG’s core values of “weʼre real, weʼre inclusive, weʼre responsible”.
By participating in a guest lecture and discussion on data analytics and AI/ML practice beyond theories, we demonstrate our commitment to sharing knowledge and expertise, embodying our responsibility to contribute positively to the academic community and bridge the gap between theory builders and problem solvers.
This event allows us to inspire and educate students in the same domains at La Trobe University, showcasing our passion and enthusiasm for the business. Through this engagement, we aim to positively impact attendees, providing suggestions for their career paths, and fostering a spirit of collaboration and continuous learning.
Showing our purpose, values, and ways of working will impress future graduates who may want to come and work for us, want to stay and thrive with us. It also helps us deliver on our purpose to create a more sociable future, together.
Moreover, I am grateful for all the support and encouragement I have received from my university friends and teammates throughout this journey. Additionally, the teaching resources and environment in the West Lecture Theatres at La Trobe University are outstanding!
AI technology is increasingly being utilized in industry and retail sectors to enhance efficiency, productivity, and customer experiences. In this post, we firstly revisit the relationship between the industry and retail sections, then provide some common AI technologies and applications used in these domains.
Industry and Retail Relationship
The key difference between industry and retail lies in their primary functions and the nature of their operations:
Industry:
Industry, often referred to as manufacturing or production, involves the creation, extraction, or processing of raw materials and the transformation of these materials into finished goods or products.
Industrial businesses are typically involved in activities like manufacturing, mining, construction, or agriculture.
The primary focus of the industry is to produce goods on a large scale, which are then sold to other businesses, wholesalers, or retailers. These goods are often used as inputs for other industries or for further processing.
Industries may have complex production processes, rely on machinery and technology, and require substantial capital investment.
Retail:
Retail, on the other hand, involves the sale of finished products or goods directly to the end consumers for personal use. Retailers act as intermediaries between manufacturers or wholesalers and the end customers.
Retailers can take various forms, including physical stores, e-commerce websites, supermarkets, boutiques, and more.
Retailers may carry a wide range of products, including those manufactured by various industries. They focus on providing a convenient and accessible point of purchase for consumers.
Retail operations are primarily concerned with merchandising, marketing, customer service, inventory management, and creating a satisfying shopping experience for consumers.
AI in Industry
AI, or artificial intelligence, is revolutionizing industry sectors by powering various applications and technologies that enhance efficiency, productivity, and customer experiences. Here are some common AI technologies and applications used in these domains:
1. Robotics and Automation: AI-driven robots and automation systems are used in manufacturing to perform repetitive, high-precision tasks, such as assembly, welding, and quality control. Machine learning algorithms enable these robots to adapt and improve their performance over time.
2. Predictive Maintenance: AI is used to predict when industrial equipment, such as machinery or vehicles, is likely to fail. This allows companies to schedule maintenance proactively, reducing downtime and maintenance costs.
3. Quality Control: Computer vision and machine learning algorithms are employed for quality control processes. They can quickly identify defects or irregularities in products, reducing the number of faulty items reaching the market.
4. Supply Chain Optimization: AI helps in optimizing the supply chain by predicting demand, managing inventory, and optimizing routes for logistics and transportation.
5. Process Optimization: AI can optimize manufacturing processes by adjusting parameters in real time to increase efficiency and reduce energy consumption.
6. Safety and Compliance: AI-driven systems can monitor and enhance workplace safety, ensuring that industrial facilities comply with regulations and safety standards.
AI in Retail
AI technology is revolutionizing the retail sector too, introducing innovative solutions and transforming the way businesses engage with customers. Here are some key AI technologies and applications used in retail:
1. Personalized Marketing: AI is used to analyze customer data and behaviours to provide personalized product recommendations, targeted marketing campaigns, and customized shopping experiences.
2. Chatbots and Virtual Assistants: Retailers employ AI-powered chatbots and virtual assistants to provide customer support, answer queries, and assist with online shopping.
3. Inventory Management: AI can optimize inventory levels and replenishment by analyzing sales data and demand patterns, reducing stockouts and overstock situations.
4. Price Optimization: Retailers use AI to dynamically adjust prices based on various factors, such as demand, competition, and customer behaviour, to maximize revenue and profits.
5. Visual Search and Image Recognition: AI enables visual search in e-commerce, allowing customers to find products by uploading images or using images they find online.
6. Supply Chain and Logistics: AI helps optimize supply chain operations, route planning, and warehouse management, improving efficiency and reducing costs.
7. In-Store Analytics: AI-powered systems can analyze in-store customer behaviour, enabling retailers to improve store layouts, planogram designs, and customer engagement strategies.
8. Fraud Detection: AI is used to detect and prevent fraudulent activities, such as credit card fraud and return fraud, to protect both retailers and customers.
Summary
AI’s potential to transform industry and retail is huge and its future applications are very promising. As AI technologies advance, we can expect increased levels of automation, personalization, and optimization in industry and retail operations.
AI technologies in these sectors often rely on machine learning (ML), deep learning (DL), natural language processing (NLP), and computer vision (CV), and now Generative Large Language Models (LLM) to analyze and gain insights from data. These AI applications are continuously evolving and are changing the way businesses in these sectors operate, leading to improved processes and customer experiences.
AI will drive high levels of efficiency, innovation, and customer satisfaction in these sectors, ultimately revolutionizing the way businesses operate and interact with consumers.
Prompt engineering is like adjusting audio without opening the equipment.
Introduction
Prompt Engineering, also known as In-Context Prompting, refers to methods for communicating with a Large Language Model (LLM) like GPT (Generative Pre-trained Transformer) to manipulate/steer its behaviour for expected outcomes without updating, retraining or fine-tuning the model weights.
Researchers, developers, or users may engage in prompt engineering to instruct a model for specific tasks, improve the model’s performance, or adapt it to better understand and respond to particular inputs. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.
This post only focuses on prompt engineering for autoregressive language models, so nothing with image generation or multimodality models.
Basic Prompting
Zero-shot and few-shot learning are the two most basic approaches for prompting the model, pioneered by many LLM papers and commonly used for benchmarking LLM performance. That is to say, Zero-shot and few-shot testing are scenarios used to evaluate the performance of large language models (LLMs) in handling tasks with little or no training data. Here are examples for both:
Zero-shot
Zero-shot learning simply feeds the task text to the model and asks for results.
Scenario: Text Completion (Please try the following input in ChatGPT or Google Bard)
Input:
Task: Complete the following sentence:
Input: The capital of France is ____________.
Output (ChatGPT / Bard):
Output: The capital of France is Paris.
Few-shot
Few-shot learning presents a set of high-quality demonstrations, each consisting of both input and desired output, on the target task. As the model first sees good examples, it can better understand human intention and criteria for what kinds of answers are wanted. Therefore, few-shot learning often leads to better performance than zero-shot. However, it comes at the cost of more token consumption and may hit the context length limit when the input and output text are long.
Scenario: Text Classification
Input:
Task: Classify movie reviews as positive or negative.
Examples: Review 1: This movie was amazing! The acting was superb. Sentiment: Positive Review 2: I couldn't stand this film. The plot was confusing. Sentiment: Negative
Question: Review: I'll bet the video game is a lot more fun than the film. Sentiment:____
Output
Sentiment: Negative
Many studies have explored the construction of in-context examples to maximize performance. They observed that the choice of prompt format, training examples, and the order of the examples can significantly impact performance, ranging from near-random guesses to near-state-of-the-art performance.
Hallucination
In the context of Large Language Models (LLMs), hallucination refers to a situation where the model generates outputs that are incorrect or not grounded in reality. A hallucination occurs when the model produces information that seems plausible or coherent but is actually not accurate or supported by the input data.
For example, in a language generation task, if a model is asked to provide information about a topic and it generates details that are not factually correct or have no basis in the training data, it can be considered as hallucination. This phenomenon is a concern in natural language processing because it can lead to the generation of misleading or false information.
Addressing hallucination in LLMs is a challenging task, and researchers are actively working on developing methods to improve the models’ accuracy and reliability. Techniques such as fine-tuning, prompt engineering, and designing more specific evaluation metrics are among the approaches used to mitigate hallucination in language models.
Perfect Prompt Formula for ChatBots
For personal daily documenting work such as text generation, there are six key components making up the perfect formula for ChatGPT and Google Bard:
Task, Context, Exemplars, Persona, Format, and Tone.
Prompt Formula for ChatBots
The Task sentence needs to articulate the end goal and start with an action verb.
Use three guiding questions to help structure relevant and sufficient Context.
Exemplars can drastically improve the quality of the output by giving specific examples for the AI to reference.
For Persona, think of who you would ideally want the AI to be in the given task situation.
Visualizing your desired end result will let you know what format to use in your prompt.
And you can actually use ChatGPT to generate a list of Tone keywords for you to use!
If you are ever curious about what the heck are those techies talking about with the above words? Please continues …
OK, so here’s the deal. We’re diving into the world of academia, talking about machine learning and large language models in the computer science and engineering domains. I’ll try to explain it in a simple way, but you can always dig deeper into these topics elsewhere.
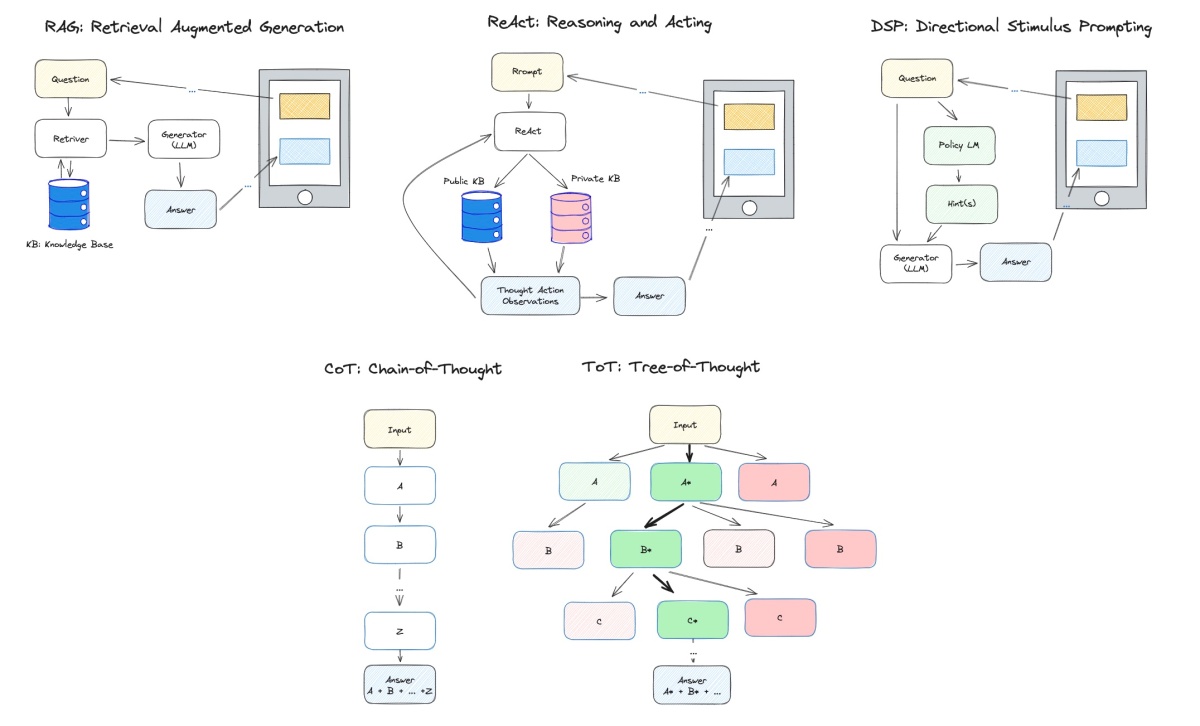
RAG: Retrieval-Augmented Generation
RAG (Retrieval-Augmented Generation): RAG typically refers to a model that combines both retrieval and generation approaches. It might use a retrieval mechanism to retrieve relevant information from a database or knowledge base and then generate a response based on that retrieved information. In real applications, the users’ input and the model’s output will be pre/post-processed to follow certain rules and obey laws and regulations.
RAG: Retrieval-Augmented Generation
Here is a simplified example of using a Retrieval-Augmented Generation (RAG) model for a question-answering task. In this example, we’ll use a system that retrieves relevant passages from a knowledge base and generates an answer based on that retrieved information.
Input:
User Query: What are the symptoms of COVID-19?
Knowledge Base:
1. Title: Symptoms of COVID-19 Content: COVID-19 symptoms include fever, cough, shortness of breath, fatigue, body aches, loss of taste or smell, sore throat, etc.
2. Title: Prevention measures for COVID-19 Content: To prevent the spread of COVID-19, it's important to wash hands regularly, wear masks, practice social distancing, and get vaccinated.
3. Title: COVID-19 Treatment Content: COVID-19 treatment involves rest, hydration, and in severe cases, hospitalization may be required.
RAG Model Output:
Generated Answer:
The symptoms of COVID-19 include fever, cough, shortness of breath, fatigue, body aches, etc.
Remark: ChatGPT 3.5 will give basic results like the above. But, Google Bard will provide extra resources like CDC links and other sources it gets from the Search Engines. We could guess Google used a different framework to OpenAI.
CoT: Chain-of-Thought
Chain-of-thought (CoT) prompting (Wei et al. 2022) generates a sequence of short sentences to describe reasoning logics step by step, known as reasoning chains or rationales, to eventually lead to the final answer.
The benefit of CoT is more pronounced for complicated reasoning tasks while using large models (e.g. with more than 50B parameters). Simple tasks only benefit slightly from CoT prompting.
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, essentially creating a tree structure. The search process can be BFS or DFS while each state is evaluated by a classifier (via a prompt) or majority vote.
CoT : Chain-of-Thought and ToT: Tree-of-Thought
Self-Ask + Search Engine
Self-Ask (Press et al. 2022) is a method to repeatedly prompt the model to ask follow-up questions to construct the thought process iteratively. Follow-up questions can be answered by search engine results.
Self-Ask+Search Engine Example
ReAct: Reasoning and Acting
ReAct (Reason + Act; Yao et al. 2023) combines iterative CoT prompting with queries to Wikipedia APIs to search for relevant entities and content and then add it back into the context.
In each trajectory consists of multiple thought-action-observation steps (i.e. dense thought), where free-form thoughts are used for various purposes.
Specifically, from the paper, the authors use a combination of thoughts that decompose questions (“I need to search x, find y, then find z”), extract information from Wikipedia observations (“x was started in 1844”, “The paragraph does not tell x”), perform commonsense (“x is not y, so z must instead be…”) or arithmetic reasoning (“1844 < 1989”), guide search reformulation (“maybe I can search/lookup x instead”), and synthesize the final answer (“…so the answer is x”).
DSP: Directional Stimulus Prompting
Directional Stimulus Prompting (DSP, Z. Li 2023), is a novel framework for guiding black-box large language models (LLMs) toward specific desired outputs. Instead of directly adjusting LLMs, this method employs a small tunable policy model to generate an auxiliary directional stimulus (hints) prompt for each input instance.
DSP: Directional Stimulus Prompting
Summary and Conclusion
Prompt engineering involves carefully crafting these prompts to achieve desired results. It can include experimenting with different phrasings, structures, and strategies to elicit the desired information or responses from the model. This process is crucial because the performance of language models can be sensitive to how prompts are formulated.
I believe a lot of researchers will agree with me. Some prompt engineering papers don’t need to be 8 pages long. They could explain the important points in just a few lines and use the rest for benchmarking.
As researchers and developers delve further into the realms of prompt engineering, they continue to push the boundaries of what these sophisticated models can achieve.
To achieve this, it’s important to create a user-friendly LLM benchmarking system that many people will use. Developing better methods for creating prompts will help advance language models and improve how we use LLMs. These efforts will have a big impact on natural language processing and related fields.
TL;DR: This blog explores the profound influence of ChatGPT, awakening various sectors – the general public, academia, and industry – to the developmental philosophy of Large Language Models (LLMs). It delves into OpenAI’s prominent role and analyzes the transformative effect of LLMs on Natural Language Processing (NLP) research paradigms. Additionally, it contemplates future prospects for the ideal LLM.
This blog discusses the impact of ChatGPT and the awakening it brought to the understanding of Large Language Models (LLM). It emphasizes the importance of the development philosophy behind LLM and notes OpenAI’s leading position, followed by Google, with DeepMind and Meta catching up. The article highlights OpenAI’s contributions to LLM technology and the global hierarchy in this domain.
What is Gen-AI’s superpower?
The blog is divided into two main sections: the NLP research paradigm transformation and the ideal Large Language Model (LLM).
In the NLP research paradigm transformation section, there are two significant paradigm shifts discussed. The first shift, from deep learning to two-stage pre-trained models, marked the introduction of models like Bert and GPT. This shift led to the decline of intermediate tasks in NLP and the standardization of technical approaches across different NLP subfields.
The second paradigm shift focuses on the move from pre-trained models to General Artificial Intelligence (AGI). The blog highlights the impact of ChatGPT in bridging the gap between humans and LLMs, allowing LLMs to adapt to human commands and preferences. It also suggests that many independently existing NLP research fields will be incorporated into the LLM technology system, while other fields outside of NLP will also be included. The ultimate goal is to achieve an ideal LLM that is a domain-independent general artificial intelligence model.
In the section on the ideal Large Language Model (LLM), the blog discusses the characteristics and capabilities of an ideal LLM. It emphasizes the self-learning capabilities of LLMs, the ability to tackle problems across different subfields, and the importance of adapting LLMs to user-friendly interfaces. It also mentions the impact of ChatGPT in integrating human preferences into LLMs and the future potential for LLMs to expand into other fields such as image processing and multimodal tasks.
Overall, the blog provides insights into the impact of ChatGPT, the hierarchy in LLM development, and the future directions for LLM technology.
Introduction
Since the emergence of OpenAI ChatGPT, many people and companies have been both surprised and awakened in academia and industry. I was pleasantly surprised because I did not expect a Large Language Model (LLM) to be as effective at this level, and I was also shocked because most of our academic & industrial understanding of LLM and its development philosophy is far from the world’s most advanced ideas. This blog series covers my reviews, reflections, and thoughts about LLM.
From GPT 3.0, LLM is not merely a specific technology; it actually embodies a developmental concept that outlines where LLM should be heading. From a technical standpoint, I personally believe that the main gap exists in the different understanding of LLM and its development philosophy for the future regardless of the financial resources to build LLM.
While many AI-related companies are currently in a “critical stage of survival,” I don’t believe it is as dire as it may seem. OpenAI is the only organization with a forward-thinking vision in the world. ChatGPT has demonstrated exceptional performance that has left everyone trailing behind, even super companies like Google lag behind in their understanding of the LLM development concept and version of their products.
In the field of LLM (Language Model), there is a clear hierarchy. OpenAI is leading internationally, being about six months to a year ahead of Google and DeepMind, and approximately two years ahead of China. Google holds the second position, with technologies like PaLM 1/2, Pathways and Generative AI on GCP Vertex AI, which aligns with their technical vision. These were launched between February and April of 2022, around the same time as OpenAI’s InstructGPT 3.5. This highlights the difference between Google and OpenAI.
DeepMind has mainly focused on reinforcement learning for games and AI in science. They started paying attention to LLM in 2021, and they are currently catching up. Meta AI, previously known as Facebook AI, hasn’t prioritized LLM in the past, but they are now trying to catch up with recently open-sourced Llama 2. These institutions are currently among the best in the field.
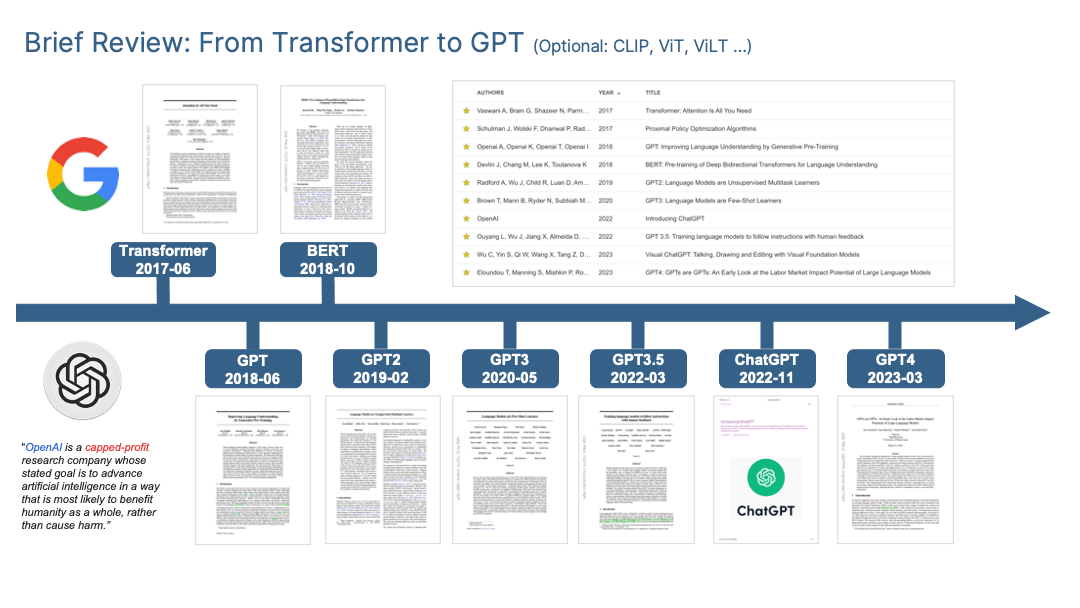
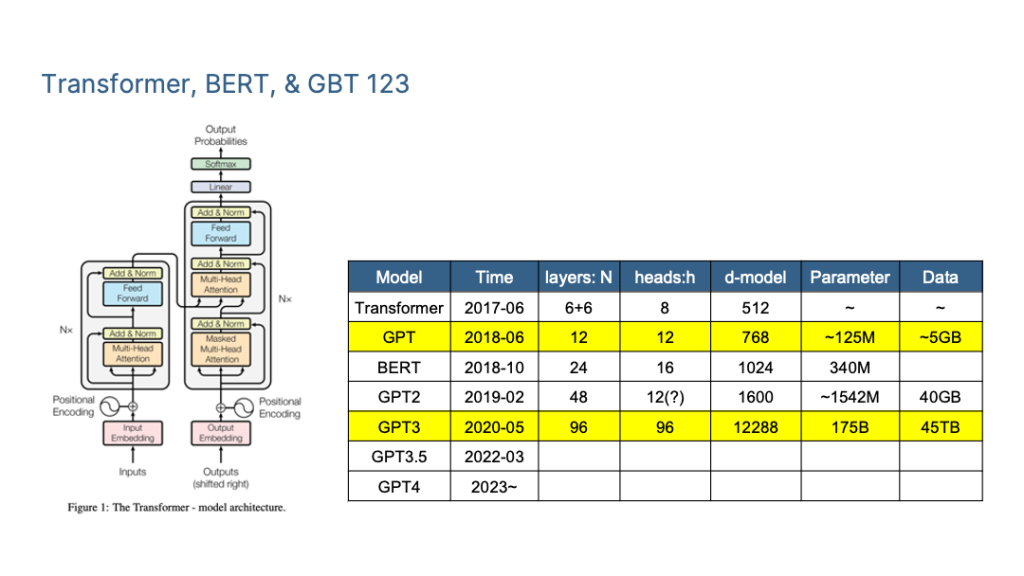
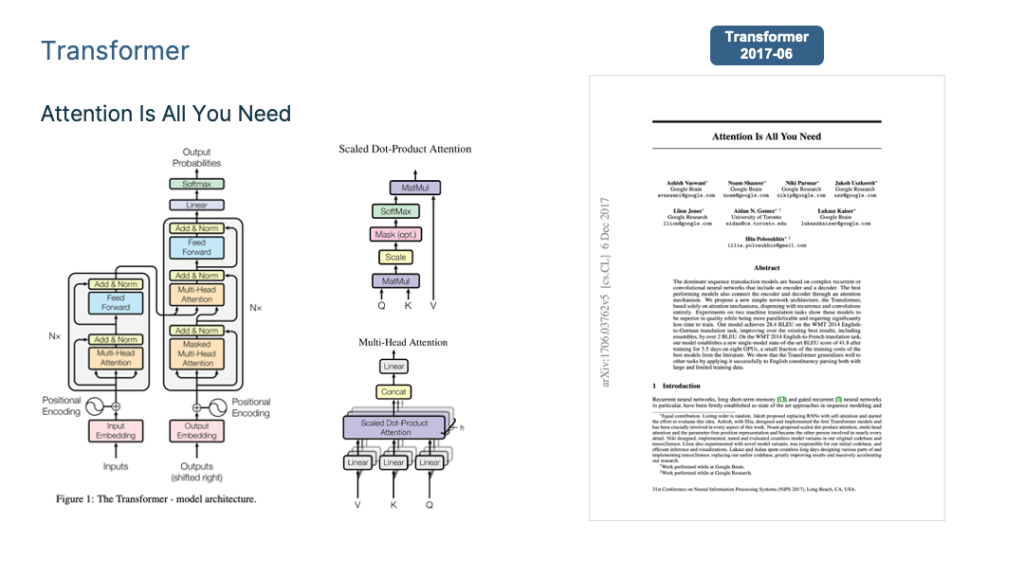
To summarize the mainstream LLM technology I mainly focus on the Transformer, BERT, GPT and ChatGPT <=4.0.
NLP Research Paradigm Transformation
Taking a look back at the early days of deep learning in Natural Language Processing (NLP), we can see significant milestones over the past two decades. There have been two major shifts in the technology of NLP.
Paradigm Shift 1.0 (2013): From Deep Learning to Two-Stage Pre-trained Models
The period of this paradigm shift encompasses roughly the time frame from the introduction of deep learning into the field of NLP, around 2013, up until just before the emergence of GPT 3.0, which occurred around May 2020.
Prior to the rise of models like BERT and GPT, the prevailing technology in the NLP field was deep learning. It was primarily reliant on two core technologies:
A plethora of enhanced LSTM models and a smaller number of improved ConvNet models served as typical Feature Extractors.
A prevalent technical framework for various specific tasks was based on Sequence-to-Sequence (or Encoder-Decoder) Architectures coupled with Attention mechanisms.
With these foundational technologies in place, the primary research focus in deep learning for NLP revolved around how to effectively increase model depth and parameter capacity. This involved the continual addition of deeper LSTM or CNN layers to encoders and decoders with the aim of enhancing layer depth and model capacity. Despite these efforts successfully deepening the models, their overall effectiveness in solving specific tasks was somewhat limited. In other words, the advantages gained compared to non-deep learning methods were not particularly significant.
The difficulties that have held back the success of deep learning in NLP can be attributed to two main issues:
Scarcity of Training Data: One significant challenge is the lack of enough training data for specific tasks. As the model becomes more complex, it requires more data to work effectively. This used to be a major problem in NLP research before the introduction of pre-trained models.
Limited Ability of LSTM/CNN Feature Extractors: Another issue is that the feature extractors using LSTM/CNN are not versatile enough. This means that, no matter how much data you have, the model struggles to make good use of it because it can’t effectively capture and utilize the information within the data.
These two factors seem to be the primary obstacles that have prevented deep learning from making significant advancements in the field of NLP.
The advent of two pre-training models, Bert and GPT, marks a significant technological advancement in the field of NLP.
About a year after the introduction of Bert, the technological landscape had essentially consolidated into these two core models.
This development has had a profound impact on both academic research and industrial applications, leading to a complete transformation of the research paradigm in the field. The impact of this paradigm shift can be observed in two key areas:
firstly, a decline and, in some cases, the gradual obsolescence of certain NLP research subfields;
secondly, the growing standardization of technical methods and frameworks across different NLP subfields.
Impact 1: The Decline of Intermediate Tasks
In the field of NLP, tasks can be categorized into two major groups: “intermediate tasks” and “final tasks.”
Intermediate tasks, such as word segmentation, part-of-speech tagging, and syntactic analysis, don’t directly address real-world needs but rather serve as preparatory stages for solving actual tasks. For example, the user doesn’t require a syntactic analysis tree; they just want an accurate translation.
In contrast, “final tasks,” like text classification and machine translation, directly fulfil user needs.
Intermediate tasks initially arose due to the limited capabilities of early NLP technology. Researchers segmented complex problems like Machine Translation into simpler intermediate stages because tackling them all at once was challenging. However, the emergence of Bert/GPT has made many of these intermediate tasks obsolete. These models, through extensive pre-training on data, have incorporated these intermediate tasks as linguistic features within their parameters. As a result, we can now address final tasks directly, without modelling these intermediary processes.
Even Chinese word segmentation, a potentially controversial example, follows the same principle. We no longer need to determine which words should constitute a phrase; instead, we let Large Language Models (LLM) learn this as a feature. As long as it contributes to task-solving, LLM will naturally grasp it. This may not align with conventional human word segmentation rules.
In light of these developments, it’s evident that with the advent of Bert/GPT, NLP intermediate tasks are gradually becoming obsolete.
Impact 2: Standardization of Technical Approaches Across All Areas
Within the realm of “final tasks,” there are essentially two categories: natural language understanding tasks and natural language generation tasks.
Natural language understanding tasks, such as text classification and sentiment analysis, involve categorizing input text.
In contrast, natural language generation tasks encompass areas like chatbots, machine translation, and text summarization, where the model generates output text based on input.
Since the introduction of the Bert/GPT models, a clear trend towards technical standardization has emerged.
Firstly, feature extractors across various NLP subfields have shifted from LSTM/CNN to Transformer. The writing was on the wall shortly after Bert’s debut, and this transition became an inevitable trend.
Currently, Transformer not only unifies NLP but is also gradually supplanting other models like CNN in various image processing tasks. Multi-modal models have similarly adopted the Transformer framework. This Transformer journey, starting in NLP, is expanding into various AI domains, kickstarted by the Vision Transformer (ViT) in late 2020. This expansion shows no signs of slowing down and is likely to accelerate further.
Secondly, most NLP subfields have adopted a two-stage model: model pre-training followed by application fine-tuning or Zero/Few Shot Prompt application.
To be more specific, various NLP tasks have converged into two pre-training model frameworks:
For natural language understanding tasks, the “bidirectional language model pre-training + application fine-tuning” model represented by Bert has become the standard.
For natural language generation tasks, the “autoregressive language model (i.e., one-way language model from left to right) + Zero/Few Shot Prompt” model represented by GPT 2.0 is now the norm.
Though these models may appear similar, they are rooted in distinct development philosophies, leading to divergent future directions. Regrettably, many of us initially underestimated the potential of GPT’s development route, instead placing more focus on Bert’s model.
Paradigm Shift 2.0 (2020): Moving from Pre-Trained Models to General Artificial Intelligence (AGI)
This paradigm shift began around the time GPT 3.0 emerged, approximately in June 2020, and we are currently undergoing this transition.
ChatGPT served as a pivotal point in initiating this paradigm shift. However, before the appearance of InstructGPT, Large Language Models (LLM) were in a transitional phase.
Transition Period: Dominance of the “Autoregressive Language Model + Prompting” Model as Seen in GPT 3.0
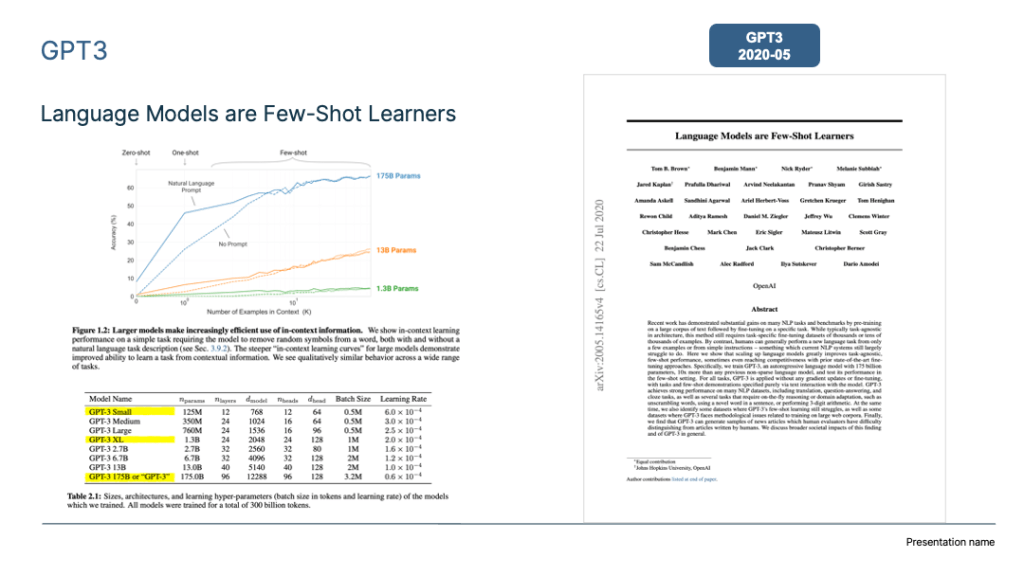
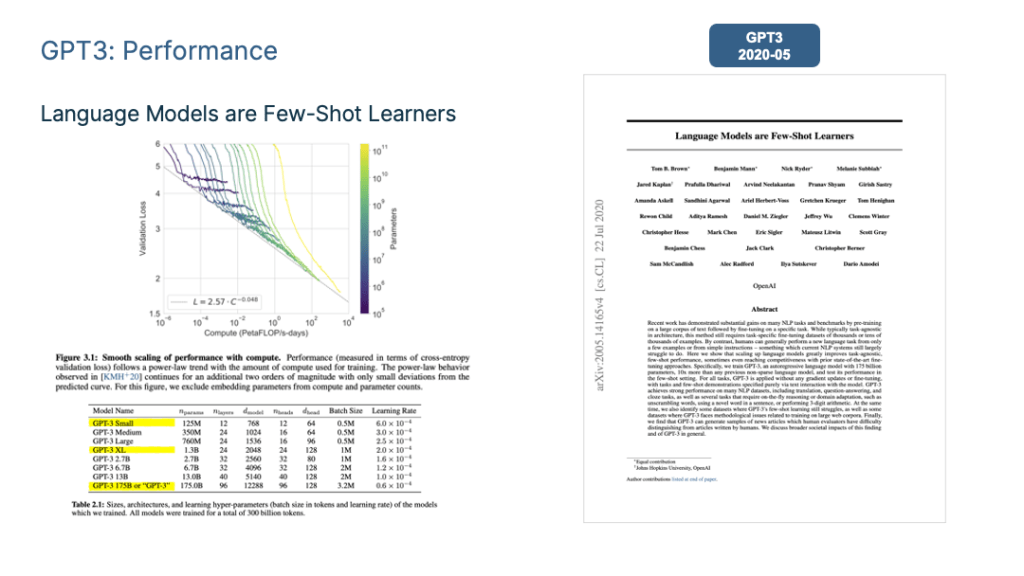
As mentioned earlier, during the early stages of pre-training model development, the technical landscape primarily converged into two distinct paradigms: the Bert mode and the GPT mode. Bert was the favoured path, with several technical improvements aligning with that direction. However, as technology progressed, we observed that the largest LLM models currently in use are predominantly based on the “autoregressive language model + Prompting” model, similar to GPT 3.0. Models like GPT 3, PaLM, GLaM, Gopher, Chinchilla, MT-NLG, LaMDA, and more all adhere to this model, without exceptions.
Why has this become the prevailing trend? There are likely two key reasons driving this shift, and I believe they are at the forefront of this transition.
Firstly, Google’s T5 model plays a crucial role in formally uniting the external expressions of both natural language understanding and natural language generation tasks. In the T5 model, tasks that involve natural language understanding, like text classification and determining sentence similarity (marked in red and yellow in the figure above), align with generation tasks in terms of input and output format.
This means that classification tasks can be transformed within the LLM model to generate corresponding category strings, achieving a seamless integration of understanding and generation tasks. This compatibility allows natural language generation tasks to harmonize with natural language understanding tasks, a feat that would be more challenging to accomplish the other way around.
The second reason is that if you aim to excel at zero-shot prompting or few-shot prompting, the GPT mode is essential.
Now, recent studies, as referenced in “On the Role of Bidirectionality in Language Model Pre-Training,” demonstrate that when downstream tasks are resolved during fine-tuning, the Bert mode outperforms the GPT mode. Conversely, if you employ zero-shot or few-shot prompting to tackle downstream tasks, the GPT mode surpasses the Bert mode.
But this leads to an important question: Why do we strive to use zero-shot or few-shot prompting for task completion? To answer this question, we first need to address another: What type of Large Language Model (LLM) is the most ideal for our needs?
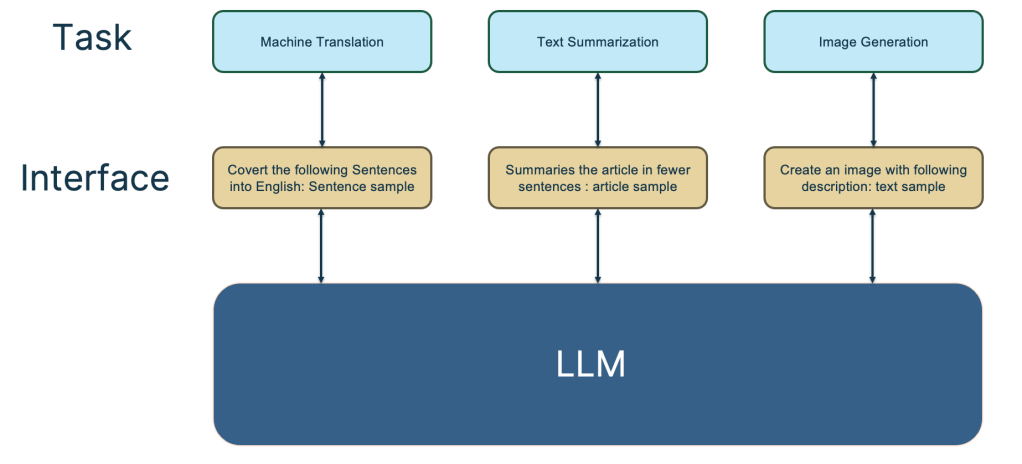
The Ideal Large Language Model (LLM)
The image above illustrates the characteristics of an ideal Large Language Model (LLM). Firstly, the LLM should possess robust self-learning capabilities. When fed with various types of data such as text and images from the world, it should autonomously acquire the knowledge contained within. This learning process should require no human intervention, and the LLM should be adept at flexibly applying this knowledge to address real-world challenges. Given the vastness of the data, this model will naturally be substantial in size, a true giant model.
Secondly, the LLM should be capable of tackling problems across any subfield of Natural Language Processing (NLP) and extend its capabilities to domains beyond NLP. Ideally, it should proficiently address queries from any discipline.
Moreover, when we utilize the LLM to resolve issues in a particular field, the LLM should understand human commands and use expressions that align with human conventions. In essence, it should adapt to humans, rather than requiring humans to adapt to the LLM model.
A common example of people adapting to LLM is the need to brainstorm and experiment with various prompts in order to find the best prompts for a specific problem. In this context, the figure above provides several examples at the interface level where humans interact with the LLM, illustrating the ideal interface design for users to effectively utilize the LLM model.
Now, let’s revisit the question: Why should we pursue zero-shot/few-shot prompting to complete tasks? There are two key reasons:
The Enormous Scale of LLM Models: Building and modifying LLM models of this scale requires immense resources and expertise, and very few institutions can undertake this. However, there are numerous small and medium-sized organizations and even individuals who require the services of such models. Even if these models are open-sourced, many lack the means to deploy and fine-tune them. Therefore, an approach that allows task requesters to complete tasks without tweaking the model parameters is essential. In this context, prompt-based methods offer a solution to fulfil tasks without relying on fine-tuning (note that soft prompting deviates from this trend). LLM model creators aim to make LLM a public utility, operating it as a service. To accommodate the evolving needs of users, model producers must strive to enable LLM to perform a wide range of tasks. This objective is a byproduct and a practical reason why large models inevitably move toward achieving General Artificial Intelligence (AGI).
The Evolution of Prompting Methods: Whether it’s zero-shot prompting, few-shot prompting, or the more advanced Chain of Thought (CoT) prompting that enhances LLM’s reasoning abilities, these methods align with the technology found in the interface layer illustrated earlier. The original aim of zero-shot prompting was to create the ideal interface between humans and LLM, using the task expressions that humans are familiar with. However, it was found that LLM struggled to understand and perform well with this approach. Subsequent research revealed that when a few examples were provided to represent the task description, LLM’s performance improved, leading to the exploration of better few-shot prompting technologies. In essence, our initial hope was for LLM to understand and execute tasks using natural, human-friendly commands. However, given the current technological limitations, these alternative methods have been adopted to express human task requirements.
Understanding this logic, it becomes evident that few-shot prompting, also known as In Context Learning, is a transitional technology. When we can describe a task more naturally and LLM can comprehend it, we will undoubtedly abandon these transitional methods. The reason is clear: using these approaches to articulate task requirements does not align with human habits and usage patterns.
This is also why I classify GPT 3.0+Prompting as a transitional technology. The arrival of ChatGPT has disrupted this existing state of affairs by introducing Instruct instead of Prompting. This change marks a new technological paradigm shift and has subsequently led to several significant consequences.
Impact 1: LLM Adapting Humans NEEDS with Natural Interfaces
In the context of an ideal LLM, let’s focus on ChatGPT to grasp its technical significance. ChatGPT stands out as one of the technologies that align most closely with the ideal LLM, characterized by its remarkable attributes: “Powerful and considerate.”
This “powerful capability” can be primarily attributed to the foundation provided by the underlying LLM, GPT 3.5, on which ChatGPT relies. While ChatGPT includes some manually annotated data, the scale is relatively small, amounting to tens of thousands of examples. In contrast, GPT 3.5 was trained on hundreds of billions of token-level data, making this additional data negligible in terms of its contribution to the vast wealth of world knowledge and common sense already embedded in GPT 3.5. Hence, ChatGPT’s power primarily derives from the GPT 3.5 model, which sets the benchmark for the ideal LLM models.
But does ChatGPT infuse new knowledge into the GPT 3.5 model? Yes, it does, but this knowledge isn’t about facts or world knowledge; it’s about human preferences. “Human preference” encompasses a few key aspects:
First and foremost, it involves how humans naturally express tasks. For instance, humans typically say, “Translate the following sentence from Chinese to English” to convey the need for “machine translation.” But LLMs aren’t humans, so understanding such commands is a challenge. To bridge this gap, ChatGPT introduces this knowledge into GPT 3.5 through manual data annotation, making it easier for the LLM to comprehend human commands. This is what empowers ChatGPT with “empathy.”
Secondly, humans have their own standards for what constitutes a good or bad answer. For example, a detailed response is deemed good, while an answer containing discriminatory content is considered bad. The feedback data that people provide to LLM through the Reward Model embodies this quality preference. In essence, ChatGPT imparts human preference knowledge to GPT 3.5, resulting in an LLM that comprehends human language and is more polite.
The most significant contribution of ChatGPT is its achievement of the interface layer of the ideal LLM. It allows the LLM to adapt to how people naturally express commands, rather than requiring people to adapt to the LLM’s capabilities and devise intricate command interfaces. This shift enhances the usability and user experience of LLM.
It was InstructGPT/ChatGPT that initially recognized this challenge and offered a viable solution. This is also their most noteworthy technical contribution. In comparison to prior few-shot prompting methods, it is a human-computer interface technology that aligns better with human communication habits for interacting with LLM.
This achievement is expected to inspire subsequent LLM models and encourage further efforts in creating user-friendly human-computer interfaces, ultimately making LLM more responsive to human needs.
Impact 2: Many NLP subfields no longer have independent research value
In the realm of NLP, this paradigm shift signifies that many independently existing NLP research fields will be incorporated into the LLM technology framework, gradually losing their independent status and fading away. Following the initial paradigm shift, while numerous “intermediate tasks” in NLP are no longer required as independent research areas, most of the “final tasks” remain and have transitioned to a “pre-training + fine-tuning” framework, sparking various improvement initiatives to tackle specific domain challenges.
Current research demonstrates that for many NLP tasks, as the scale of LLM models increases, their performance significantly improves. From this, one can infer that many of the so-called “unique” challenges in a given field likely stem from a lack of domain knowledge. With sufficient domain knowledge, these seemingly field-specific issues can be effectively resolved. Thus, there’s often no need to focus intensely on field-specific problems and devise specialized solutions. The path to achieving AGI might be surprisingly straightforward: provide more data in a given field to the LLM and let it autonomously accumulate knowledge.
In this context, ChatGPT proves that we can now directly pursue the ideal LLM model. Therefore, the future technological trend should involve the pursuit of ever-larger LLM models by expanding the diversity of pre-training data, allowing LLMs to independently acquire domain-specific knowledge through pre-training. As the model scale continues to grow, numerous problems will be addressed, and the research focus will shift to constructing this ideal LLM model rather than solving field-specific problems. Consequently, more NLP subfields will be integrated into the LLM technology system and gradually phase out.
In my view, the criteria for determining whether independent research in a specific field should cease can be one of the following two methods:
First, assess whether the LLM’s research performance surpasses human performance for a particular task. For fields where LLM outperforms humans, there is no need for independent research. For instance, for many tasks within the GLUE and SuperGLUE test sets, LLMs currently outperform humans, rendering independently existing research fields closely associated with these datasets unnecessary.
Second, compare task performance between the two modes. The first mode involves fine-tuning with extensive domain-specific data, while the second mode employs few-shot prompting or instruct-based techniques. If the second mode matches or surpasses the performance of the first, it indicates that the field no longer needs to exist independently. By this standard, many research fields currently favour fine-tuning (due to the abundance of training data), seemingly justifying their independent existence. However, as models grow in size, the effectiveness of few-shot prompting continues to rise, and it’s likely that this turning point will be reached in the near future.
If these speculations hold true, it presents the following challenging realities:
For many NLP researchers, they must decide which path to pursue. Should they persist in addressing field-specific challenges?
Or should they abandon what may seem like a less promising route and instead focus on constructing a superior LLM?
If the choice is to invest in LLM development, which institutions possess the ability and resources to undertake this endeavour?
What’s your response to this question?
Impact 3: More research fields other than NLP will be included in the LLM technology system
From the perspective of AGI, referring to the ideal LLM model described previously, the tasks it can complete should not be limited to the NLP field or one or two subject areas. The ideal LLM should be a domain-independent general artificial intelligence model. , it is now doing well in one or two fields, but it does not mean that it can only do these tasks.
The emergence of ChatGPT proves that it is feasible for us to pursue AGI in this period, and now is the time to put aside the shackles of “field discipline” thinking.
In addition to demonstrating its ability to solve various NLP tasks in a smooth conversational format, ChatGPT also has powerful coding capabilities. Naturally, more and more other research fields will be gradually included in the LLM system and become part of general artificial intelligence.
LLM expands its field from NLP to the outside world. A natural choice is image processing and multi-modal related tasks. There are already some efforts to integrate multimodality and make LLM a universal human-computer interface that supports multimodal input and output. Typical examples include DeepMind’s Flamingo and Microsoft’s “Language Models are General-Purpose Interfaces”, as shown above. The conceptual structure of this approach is demonstrated.
My judgment is that whether it is images or multi-modality, the future integration into LLM to become useful functions may be slower than we think.
The main reason is that although the image field has been imitating Bert’s pre-training approach in the past two years, it is trying to introduce self-supervised learning to release the model’s ability to independently learn knowledge from image data. Typical technologies are “contrastive learning” and MAE. These are two different technical routes.
However, judging from the current results, despite great technological progress, it seems that this road has not yet been completed. This is reflected in the application of pre-trained models in the image field to downstream tasks, which brings far fewer benefits than Bert or GPT. The application is significant in NLP downstream tasks.
Therefore, image preprocessing models still need to be explored in depth to unleash the potential of image data, which will delay their unification into large LLM models. Of course, if this road is opened one day, there is a high probability that the current situation in the field of NLP will be repeated, that is, various research subfields of image processing may gradually disappear and be integrated into large-scale LLM to directly complete terminal tasks.
In addition to images and multi-modality, it is obvious that other fields will gradually be included in the ideal LLM. This direction is in the ascendant and is a high-value research topic.
The above are my personal thoughts on paradigm shift. Next, let’s sort out the mainstream technological progress of the LLM model after GPT 3.0.
As shown in the ideal LLM model, related technologies can actually be divided into two major categories;
One category is about how the LLM model absorbs knowledge from data and also includes the impact of model size growth on LLM’s ability to absorb knowledge;
The second category is about human-computer interfaces about how people use the inherent capabilities of LLM to solve tasks, including In Context Learning and Instruct modes. Chain of Thought (CoT) prompting, an LLM reasoning technology, essentially belongs to In Context Learning. Because they are more important, I will talk about them separately.
2. Openai, A. R., Openai, K. N., Openai, T. S. & Openai, I. S. GPT: Improving Language Understanding by Generative Pre-Training. (2018).
3. Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. (2018).
4. Radford, A. et al. GPT2: Language Models are Unsupervised Multitask Learners. (2019).
5. Brown, T. B. et al. GPT3: Language Models are Few-Shot Learners. (2020).
6. Ouyang, L. et al. GPT 3.5: Training language models to follow instructions with human feedback. (2022).
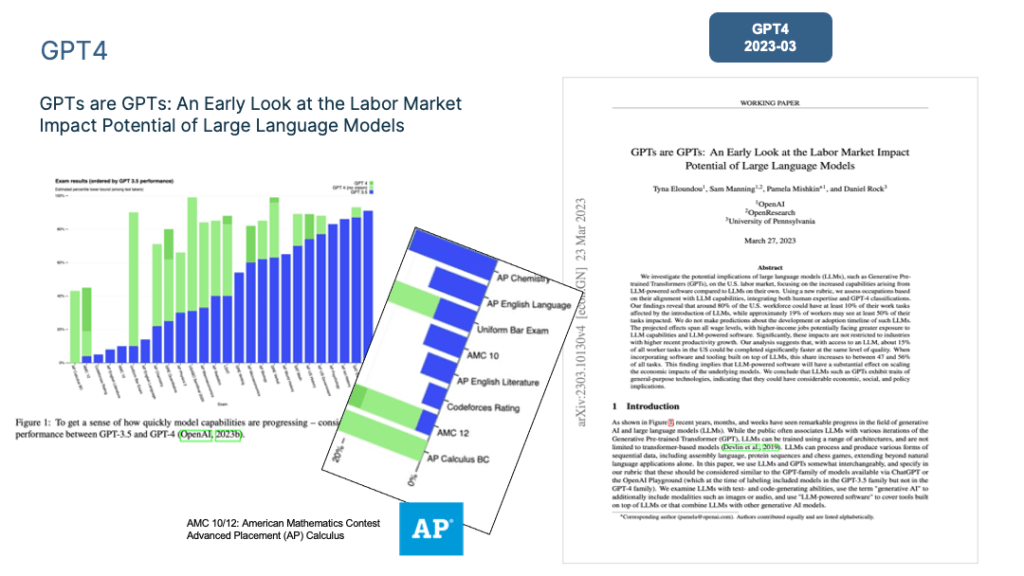
7. Eloundou, T., Manning, S., Mishkin, P. & Rock, D. GPT4: GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models. (2023).
Content created by the author and reviewed by GPT.
Obtaining the Google Cloud Professional Machine Learning Engineer (MLE) certification is a remarkable achievement for those interested in a machine learning career. As someone who recently passed the exam, I’m here to share helpful tips and insights about the journey. Whether you’re considering taking the exam or currently preparing for it, I hope this guide will help you with valuable information based on my experience.
Before diving into your exam preparation, start by carefully reading the official Exam Guide provided by Google. This document is the roadmap for us to understand the key topics and expectations for the certification.
It’s essential to have a clear grasp of what the exam covers before we begin our study journey. Revisit the ML basics via Google’s Crash Course to clarify the details.
Machine learning is a dynamic field with various approaches and techniques. Google provides best practices for implementing ML solutions on their platform, and this practical knowledge is invaluable. Learning these best practices will not only help us in the exam but also equip us with the skills necessary for real-world ML projects.
Official Google documents, which include keywords such as best practice, machine learning solution, and data pipeline, are all worth reading.
The ExamTopic website is a valuable resource for exam preparation. However, it’s essential to use it strategically. This resource is not a “cheat sheet” or a “shortcut” to the exam, so save it for later, like after we’ve refreshed our knowledge through reading the official documentation and best practices.
While ExamTopic can provide insights into potential exam questions, remember that there are no official answers. The answers offered on the web and those voted ones by users may not be correct.
Get Ready for Exam and Study Tips
Exam Online or Onsite
There are two ways to take the exam: Online and Onsite. If you choose the online option, make sure your home WIFI is stable and your system is checked (webcam, microphone, Secure Browser).
You will be asked to adjust your device’s security settings, such as turning off the Firewall or enabling screen sharing. If you’re not comfortable making these changes, consider booking an Onsite Exam.
If any issues arise during the exam, don’t panic! Just contact Kryterion support team through Live Chat. They can help with things like reopening the launch button for you or adjusting the time.
The key is to stay calm and reach out for help if needed to ensure a smooth exam experience!
Reading vs. Watching
In the age of abundant online resources, it’s tempting to jump straight into video tutorials and courses. However, for the best retention of knowledge, start by actively reading Google’s documentation.
Passive learning through watching videos may lead to omitted details. Reading engages your mind and helps you absorb information effectively.
Understand Trade-offs
Machine learning involves making critical decisions, such as balancing speed and accuracy. Take the time to understand the trade-offs involved in various ML solutions. This understanding will prove invaluable not only in the exam but also in real-world ML projects.
Reading Comprehension
During the exam, we will encounter questions that provide background information on a problem, stakeholder expectations, and resource limitations. Treat these questions like reading comprehension exercises, as key details hidden within can guide us to the correct answer. Pay close attention to keywords that may hold the solution.
Time Management
The exam requires answering 60 questions within a limited timeframe like 2 hours, which may vary in the future. Manage our time wisely by marking questions we’re unsure about for review later.
Prioritize the questions we can confidently answer first and revisit the marked ones before submitting our exam in the end.
Stress Management
Even if you tell yourself not to stress, it’s natural to feel some pressure during the exam.
Consider conducting simulated practice exams to strengthen your nerves, especially in the case that you haven’t taken any exam for a long time. This practice can help improve your mental preparedness for the actual exam.
In the end, I wish you the best of luck in your journey towards achieving the Google Cloud Professional Machine Learning Engineer certification. Remember that diligent preparation, careful reading, and a strategic approach to resources can significantly enhance your chances of success.
Stay confident, stay focused, and may you pass the exam as soon as possible!
-END-
Encourage the Author to create more useful and interesting articles.
All the money will be donated to the Standford Rural Area Education Program (https://sccei.fsi.stanford.edu/reap) at the end of each Financial Year + my personal donation.
In this paper, the authors propose a taxonomy of efficient Transformer models, characterizing them by the technical innovation and primary use case.
Transformer model architectures have garnered immense interest lately due to their effectiveness across a range of domains like language, vision and reinforcement learning. In the field of natural language processing for example, Transformers have become an indispensable staple in the modern deep learning stack. Recently, a dizzying number of “X-former” models have been proposed – Reformer, Linformer, Performer, Longformer, to name a few – which improve upon the original Transformer architecture, many of which make improvements around computational and memory efficiency. With the aim of helping the avid researcher navigate this flurry, this paper characterizes a large and thoughtful selection of recent efficiency-flavored “X-former” models, providing an organized and comprehensive overview of existing work and models across multiple domains.
In this paper, the authors propose a taxonomy of efficient Transformer models, characterizing them by the technical innovation and primary use case. Specifically, they review Transformer models that have applications in both language and vision domains, attempting to consolidate the literature across the spectrum. They also provide a detailed walk-through of many of these models and draw connections between them.
In the section 2, authors reviewed the background of the well-established Transformer architecture. Transformers are multi-layered architectures formed by stacking Transformer blocks on top of one another.
I really like the 2.4 section, when the authors summarised the the differences in the mode of usage of the Transformer block. Transformers can primarily be used in three ways, namely:
Encoder-only (e.g., for classification)
Decoder-only (e.g., for language modelling, GPT2/3)
Encoder-decoder (e.g., for machine translation)
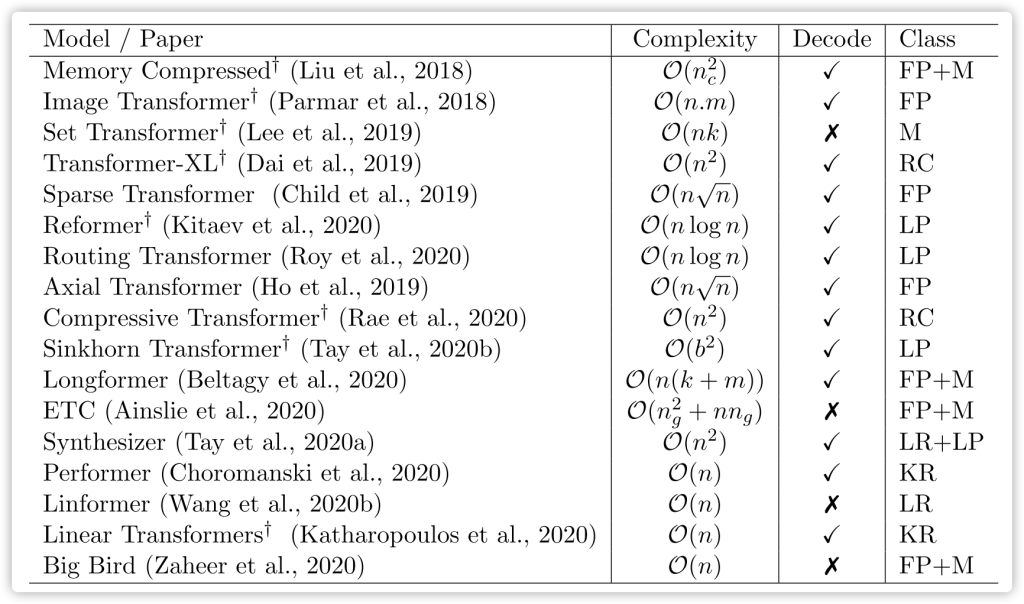
In section 3, they provide a high-level overview of efficient Transformer models and present a characterization of the different models in the taxonomy with respect to core techniques and primary use case. This is the core part of this paper covering 17 different papers’ technical details.
Summary of Efficient Transformer Models presented in chronological order of their first public disclosure.
In the last section, authors address the state of research pertaining to this class of efficient models on model evaluation, design trends, and more discussion on orthogonal efficiency effort, such as Weight Sharing, Quantization / Mixed precision, Knowledge Distillation, Neural Architecture Search (NAS) and Task Adapters.
In sum, this is a really good paper summarised all the important work around the Transformer model. It is also a good reference for researcher and engineering to be inspired and try these techniques for different models in their own projects.
FYI, here is my early post The Annotated Transformer: English-to-Chinese Translator with source code on GitHub, which is an “annotated” version of the 2017 Transformer paper in the form of a line-by-line implementation to build an English-to-Chinese translator via PyTorch ML framework.
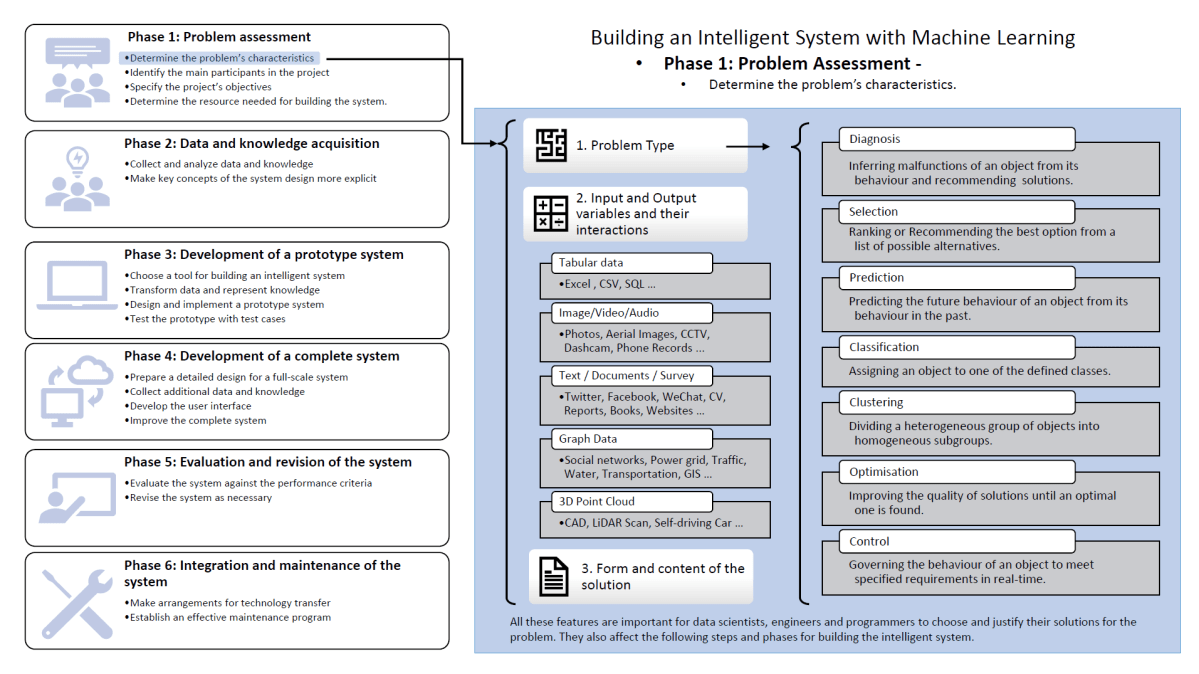
This post is following upgrade with respect to the early post How to Build an Artificial Intelligent System (I) The last one is focused on introducing the six phases of the building an intelligent system, and explaining the details of the Problem Assesment phase.
Phase 1: Problem assessment – Determine the problem’s characteristics.
What is an intelligent system?
The process of building Intelligent knowledge-based system has been called knowledge engineering since the 80s. It usually contains six phases: 1. Problem assessment; 2. Data and knowledge acquisition; 3. Development of a prototype system; 4. Development of a complete system; 5. Evaluation and revision of the system; 6. Integration and maintenance of the system [1].