
This blog is mainly based on the book and lecture notes by Professor Yaser S. Abu-Mostafa from Caltech on Learning from data; you could benefit greatly from the lecture and videos.
Learning Problem:
“In God we trust, and others bring data”.
If you show a picture to a three-year-old and ask if there is a tree, you will likely get the correct answer. But if you ask a thirty-year-old what the definition of a tree is, you will likely get an inconclusive answer.
We didn’t learn what a tree is by studying the mathematical definition of a tree. We knew it by looking at the trees. In other words, we learn from ‘Data’.
Learning from data is used when we don’t have an analytic solution but we do have data that we can use to construct an empirical solution. This premise covers many territories, and learning from data is one of the most widely used techniques in science, engineering, and economics.
Let’s draw a figure to show the basic setup of the learning problem:
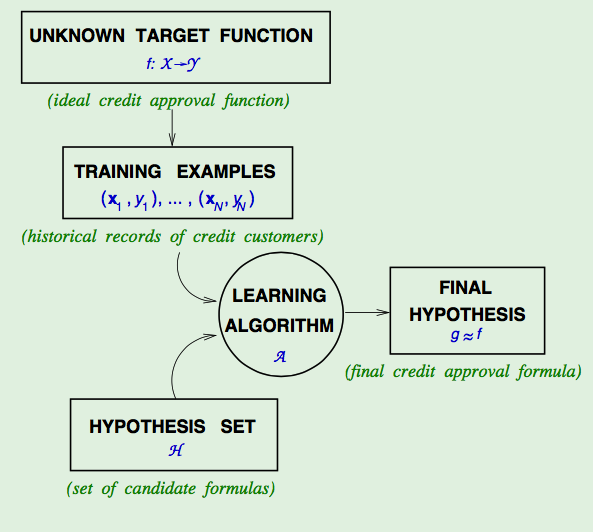
OK, if we have the data and fully understand the problem, which tool should we use?
Program and ML Toolbox
Here are some tools (programming languages) which I strongly suggest:
- Python (Top one, Good for Academia and Industry)
If you do not have access to free Matlab and do not tend to spend a few dollars on it. Python is the best choice for you. The Scikit-Learn is a simple and efficient tool for data mining and data analysis, but you have to spend some time learning Python. Then you can dance with all the advanced packages like TensorFlow, PyTorch, etc.
- Matlab (Research mainly; Do you know you can use python for free)
If you are in a university as a student or academic, you could probably use the software free in the Lab and install the academic version on your own computer. Its version is 2023a, updated with more exciting features, including most machine learning methods and deep learning toolboxes.
Even if you are not a very good programmer, you can learn Matlab with its detailed demos in a few hours.
- R (Research Only, Do not Argue with Me, if you are thinking about jobs)
R is a free software environment for statistical computing and graphics. It compiles and runs on various UNIX platforms, Windows and MacOS. However, you could find a lot of applicable packages for your particular needs, but the price is you need to spend more time learning R programming.
Note: the only issue for R is that the job market prefers Python. In other words, Life is short, use Python! Python can do more and more in industry.
Learning Principles
Learning from Data has three principles. Put them simple as:
- Occam’s Razor
Although it is not an exact quote of Einstein’s, it is often attributed to him that “ An explanation of the data should be made as simple as possible, but no simpler“.
A similar principle, Occam’s razor, dates from the 14th century and is attributed to William of Occam, where the ‘razor’ is meant to trim down the explanation to the bare minimum that is consistent with the data. The simplest model that fits the data is also the most plausible.
- Sampling Bias
It is not uncommon for someone to throw away training examples they do not like in industry or academia!
If the data is sampled in a biased way, learning will produce a similarly biased outcome.
- Data Snooping
Data snooping is the most common trap for practitioners in learning from the data. The principle involved is simple enough.
If a data set has affected any step in the learning process, its ability to assess the outcome has been compromised.
As the saying goes, if you torture the data long enough, it will confess.



Leave a comment