- AI Assistant Summary
- Introduction
- Unveiling the Depth of LLM Knowledge
- The Repository of Knowledge: How LLM Stores and Retrieves Information
- Knowledge Correction in LLM: Adapting to Evolving Information
- Methods for Modifying Knowledge in LLM
- What’s Next
Previous: Technical Review 01: Large Language Model (LLM) and NLP Research Paradigm Transformation
AI Assistant Summary
This blog explores the depth of knowledge acquired by Large Language Models (LLMs), such as the Transformer. The knowledge obtained can be categorized into linguistic knowledge and factual knowledge. Linguistic knowledge includes understanding language structure and rules, while factual knowledge encompasses real-world events and common-sense notions.

The blog explains that LLMs acquire linguistic knowledge at various levels, with more fundamental language elements residing in lower and mid-level structures, and abstract language knowledge distributed across mid-level and high-level structures. In terms of factual knowledge, LLMs absorb a significant amount of it, mainly in the mid and high levels of the Transformer model.
The blog also addresses how LLMs store and retrieve knowledge. It suggests that the feedforward neural network (FFN) layers in the Transformer serve as a Key-Value memory system, housing specific knowledge. The FFN layers detect knowledge patterns through the Key layer and retrieve corresponding values from the Value layer to generate output.
Furthermore, the blog discusses the feasibility of correcting erroneous or outdated knowledge within LLMs. It introduces three methods for modifying knowledge in LLMs:
- Correcting knowledge at the source by identifying and adjusting training data;
- Fine-tuning the model with new training data containing desired corrections;
- Directly Modifying model parameters associated with specific knowledge.
These methods aim to enhance the reliability and relevance of LLMs in providing up-to-date and accurate information. The blog emphasizes the importance of adapting and correcting knowledge in LLMs to keep pace with evolving information in real-world scenarios.
In conclusion, this blog sheds light on the depth of knowledge acquired by LLMs, how it is stored and retrieved, and strategies for correcting and adapting knowledge within these models. Understanding these aspects contributes to harnessing the full potential of LLMs in various applications.
Introduction
Judging from the current Large Language Model (LLM) research results, the Transformer is a sufficiently powerful feature extractor and does not require special improvements.
So what did Transformer learn through the pre-training process?
How is knowledge accessed?
How do we correct incorrect knowledge?
This blog discusses the research progress in this area.
Unveiling the Depth of LLM Knowledge
Large Language Models (LLM) acquire a wealth of knowledge from extensive collections of free text. This knowledge can be broadly categorized into two realms: linguistic knowledge and Factual knowledge.
Linguistic Knowledge
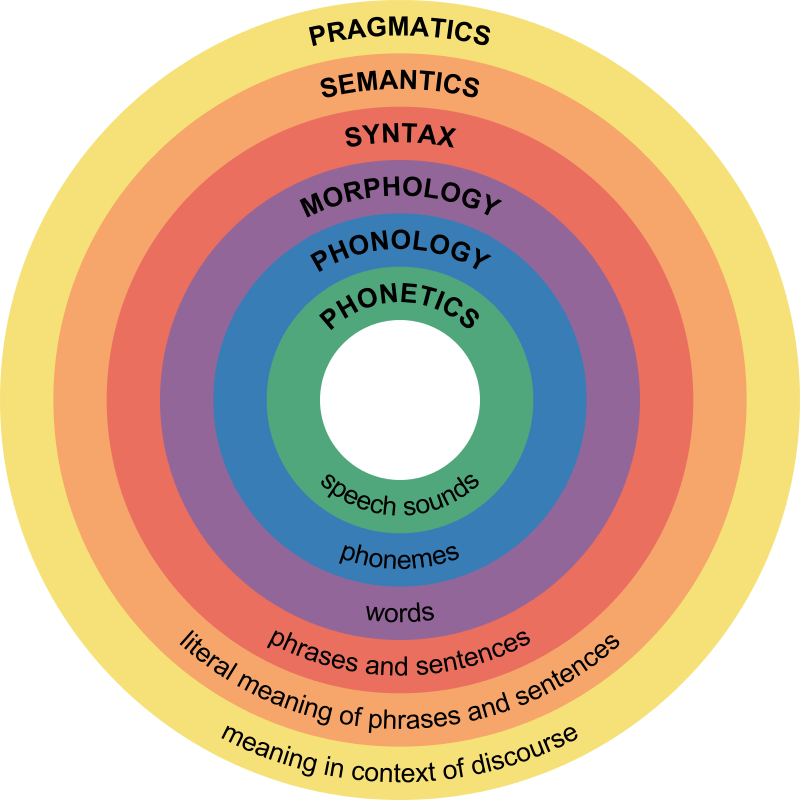
- This encompasses understanding the structure and rules of language, including morphology, parts of speech, syntax, and semantics. Extensive research has affirmed the capacity of LLM to grasp various levels of linguistic knowledge.
- Since the emergence of models like Bert, numerous experiments have validated this capability. The acquisition of such linguistic knowledge is pivotal, as it substantially enhances LLM’s performance in various natural language understanding tasks following pre-training.
- Additionally, investigations have shown that more fundamental language elements like morphology, parts of speech, and syntax reside in the lower and mid-level structures of the Transformer, while abstract language knowledge, such as semantics, is distributed across the mid-level and high-level structures.
Factual Knowledge

- This category encompasses both factual knowledge, relating to real-world events, and common-sense knowledge.
- Examples include facts like “Biden is the current President of the United States” and common-sense notions like “People have two eyes.”
- Numerous studies have explored the extent to which LLM models can absorb world knowledge, and the consensus suggests that they indeed acquire a substantial amount of it from their training data.
- This knowledge tends to be concentrated primarily in the mid and high levels of the Transformer model. Notably, as the depth of the Transformer model increases, its capacity to learn and retain knowledge expands exponentially. LLM can be likened to an implicit knowledge graph stored within its model parameters.
A study titled “When Do You Need Billions of Words of Pre-training Data?” delves into the relationship between the volume of pre-training data and the knowledge acquired by the model.

The conclusion drawn is that for Bert-type language models, a corpus containing 10 million to 100 million words suffices to learn linguistic knowledge, including syntax and semantics. However, to grasp factual knowledge, a more substantial volume of training data is required.
This is logical, given that linguistic knowledge is relatively finite and static, while factual knowledge is vast and constantly evolving. Current research demonstrates that as the amount of training data increases, the pre-trained model exhibits enhanced performance across a range of downstream tasks, emphasizing that the incremental data mainly contributes to the acquisition of world knowledge.
The Repository of Knowledge: How LLM Stores and Retrieves Information
As discussed earlier, Large Language Models (LLM) accumulate an extensive reservoir of language and world knowledge from their training data. But where exactly is this knowledge stored within the model, and how does LLM access it? These are intriguing questions worth exploring.
Evidently, this knowledge is stored within the model parameters of the Transformer architecture. The model parameters can be divided into two primary components: the multi-head attention (MHA) segment, which constitutes roughly one-third of the total parameters, and the remaining two-thirds of the parameters are concentrated in the feedforward neural network (FFN) structure.
The MHA component primarily serves to gauge the relationships and connections between words or pieces of knowledge, facilitating the integration of global information. It’s more geared toward establishing contextual connections rather than storing specific knowledge points. Therefore, it’s reasonable to infer that the substantial knowledge base of the LLM model is primarily housed within the FFN structure of the Transformer.
However, the granularity of such positioning is still too coarse, and it is difficult to answer how a specific piece of knowledge is stored and retrieved.
A relatively novel perspective, introduced in the article “Transformer Feed-Forward Layers Are Key-Value Memories,” suggests that the feedforward neural network (FFN) layers in the Transformer architecture function as a Key-Value memory system storing a wealth of specific knowledge. The figure below illustrates this concept, with annotations on the right side for improved clarity (since the original paper’s figure on the left side can be somewhat challenging to grasp).
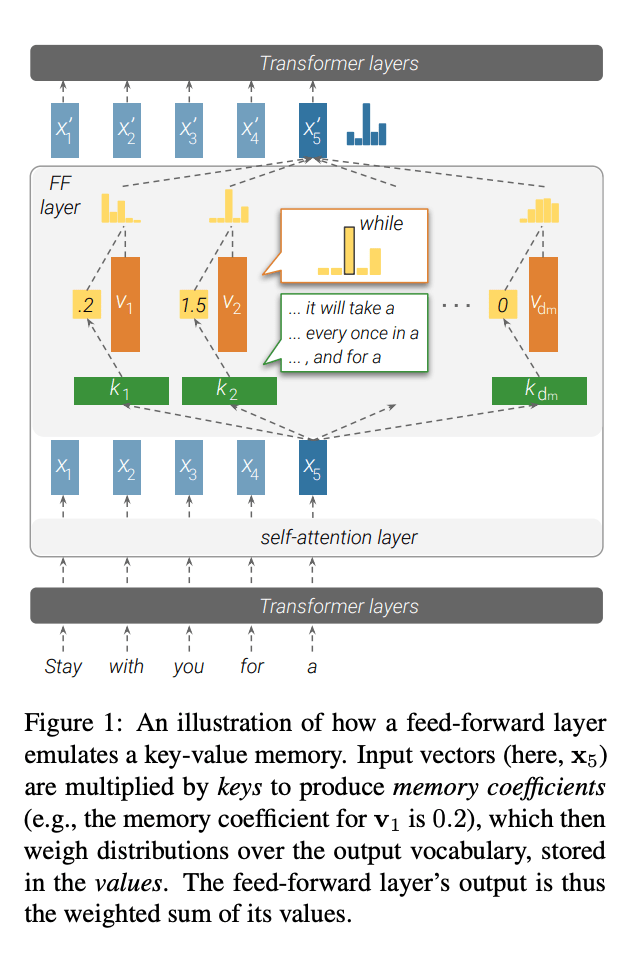
In this Key-Value memory framework, the first layer of the FFN serves as the Key layer, characterized by a wide hidden layer, while the second layer combines a narrow hidden layer with the Value layer. The input to the FFN layer corresponds to the output embedding generated by the Multi-Head Attention (MHA) mechanism for a specific word, encapsulating the comprehensive context information drawn from the entire input sentence via self-attention.
Each neuron node in the Key layer stores a pair of information. For instance, the node in the first hidden layer of the FFN may record the knowledge.
The Key vector associated with a node essentially acts as a pattern detector, aiming to identify specific language or knowledge patterns within the input. If a relevant pattern is detected, the input vector and the key node’s weight are computed via the vector inner product, followed by the application of the Rectified Linear Unit (ReLU) activation function, signalling that the pattern has been detected. The resulting response value is then propagated to the second FFN layer through the Value weights of the node.
In essence, the FFN’s forward propagation process resembles the detection of a specific knowledge pattern using the Key, retrieving the corresponding Value, and incorporating it into the second FFN layer’s output. As each node in the second FFN layer aggregates information from all nodes in the Key layer, it generates a mixed response, with the collective response across all nodes in the Value layer serving as probability distribution information for the output word.
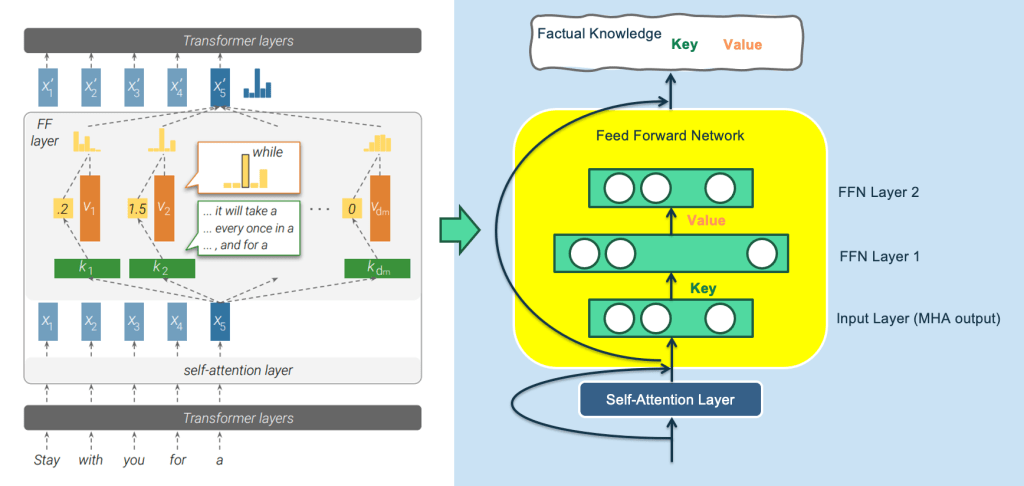
It may still sound complicated, so let’s use an extreme example to illustrate. We assume that the node in the above figure is the Key-Value memory that records the knowledge. Its Key vector is used to detect the knowledge pattern “The capital of China is…” and its Value. The vector basically stores a vector that is close to the Embedding of the word “Beijing”. When the input of the Transformer is “The capital of China is [Mask]”, the node detects this knowledge pattern from the input layer, so it generates a larger response output. We assume that other neurons in the Key layer have no response to this input, then the corresponding node in the Value layer will actually only receive the word embedding corresponding to the Value “Beijing”, and pass the large response value to perform further numerical calculations. enlarge. Therefore, the output corresponding to the Mask position will naturally output the word “Beijing”. It’s basically this process. It looks complicated, but it’s actually very simple.
Moreover, this article also pointed out that the low-level Transformer responds to the surface pattern of sentences, and the high-level responds to the semantic pattern. That is to say, the low-level FFN stores surface knowledge such as lexicon and syntax, and the middle and high-level layers store semantic and factual concept knowledge. This is consistent with other research The conclusion is consistent.
I would guess that the idea of treating FFN as a Key-Value memory is probably not the final correct answer, but it is probably not too far from the final correct answer.
Knowledge Correction in LLM: Adapting to Evolving Information
As we’ve established that specific pieces of factual knowledge reside in the parameters of one or more feedforward neural network (FFN) nodes within the Large Language Models (LLM), it’s only natural to ponder the feasibility of correcting erroneous or outdated knowledge stored within these models.
Let’s consider an example to illustrate this point. If you were to ask, “Who is the current Prime Minister of the United Kingdom?” in a dynamic political landscape where British Prime Ministers frequently change, would LLM tend to produce “Boris” or “Sunak” as the answer?
In such a scenario, the model is likely to encounter a higher volume of training data containing “Boris.” Consequently, there’s a considerable risk that LLM could provide an incorrect response. Therefore, there arises a compelling need to address the issue of correcting outdated or erroneous knowledge stored within the LLM.
By exploring strategies to rectify knowledge within LLM and adapting it to reflect real-time developments and evolving information, we take a step closer to harnessing the full potential of these models in providing up-to-date and accurate answers to questions that involve constantly changing facts or details. This endeavour forms an integral part of enhancing the reliability and relevance of LLM in practical applications.
Methods for Modifying Knowledge in LLM
Currently, there are three distinctive approaches for modifying knowledge within Large Language Models (LLMs):
Correcting Knowledge at the Source
This method aims to rectify knowledge errors by identifying the specific training data responsible for the erroneous knowledge in the LLM. With advancements in research, it’s possible to trace back the source data that led the LLM to learn a particular piece of knowledge. In practical terms, this means we can identify the training data associated with a specific knowledge item, allowing us to potentially delete or amend the relevant data source. However, this approach has limitations, particularly when dealing with minor knowledge corrections. The need for retraining the entire model to implement even small adjustments can be prohibitively costly. Therefore, this method is better suited for large-scale data removal, such as addressing bias or eliminating toxic content.
Fine-Tuning to Correct Knowledge
This approach involves constructing new training data containing the desired knowledge corrections. The LLM model is then fine-tuned on this data, guiding it to remember new knowledge and forget old knowledge.
While straightforward, it presents challenges, such as the issue of “catastrophic forgetting,” where fine-tuning leads the model to forget not only the targeted knowledge but also other essential knowledge. Given the large size of current LLMs, frequent fine-tuning can be computationally expensive.
Directly Modifying Model Parameters
In this method, knowledge correction is achieved by directly altering the LLM’s model parameters associated with specific knowledge. For instance, if we wish to update the knowledge from “<UK, current Prime Minister, Boris>” to “<UK, current Prime Minister, Sunak>”, we locate the FFN node storing the old knowledge within the LLM parameters.
Subsequently, we forcibly adjust and replace the relevant model parameters within the FFN to reflect the new knowledge. This approach involves two key components: the ability to pinpoint the storage location of knowledge within the LLM parameter space and the capacity to alter model parameters for knowledge correction. Deeper insight into this knowledge revision process contributes to a more profound understanding of LLMs’ internal mechanisms.
These methods provide a foundation for adapting and correcting the knowledge within LLMs, ensuring that these models can produce accurate and up-to-date information in response to ever-changing real-world scenarios.
What’s Next
The next blog is about the Technical Review 03: Scale Effect: What happens when LLM gets bigger and bigger



Leave a comment