Skip to content
Facebook
Twitter
Instagram
TikTok
YouTube
Search
C. Cui's Blog
Chris Cui
2026-07-31
Mathematics in the Age of AI: Terence Tao’s Vision for the Mathematical Community
Chris Cui
2026-07-13
Goodhart’s Law: The Tyranny of Metrics
Chris Cui
2026-05-10
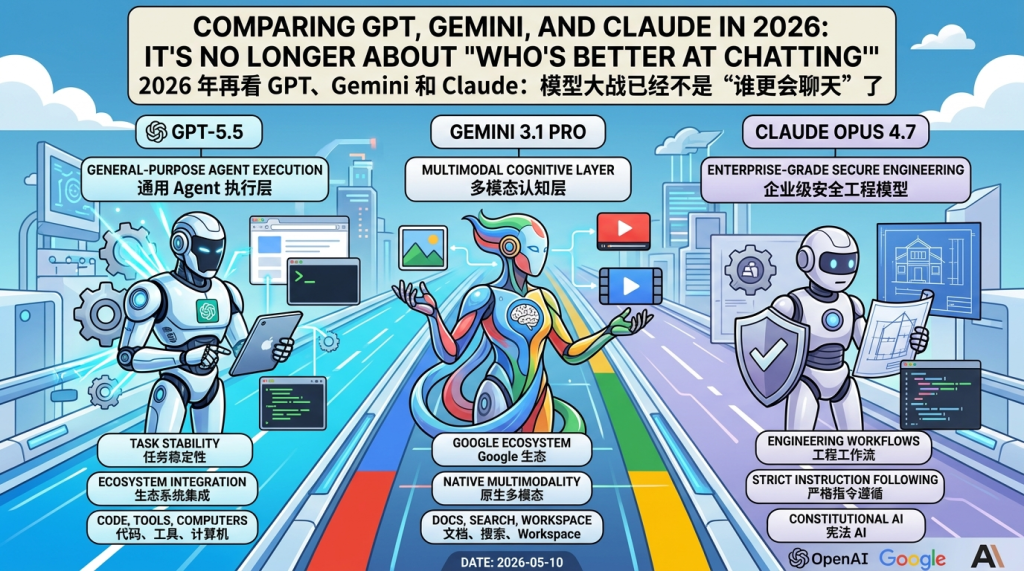
Comparing GPT, Gemini, and Claude in 2026: It’s No Longer About ‘Who’s Better at Chatting’
Chris Cui
2026-05-02
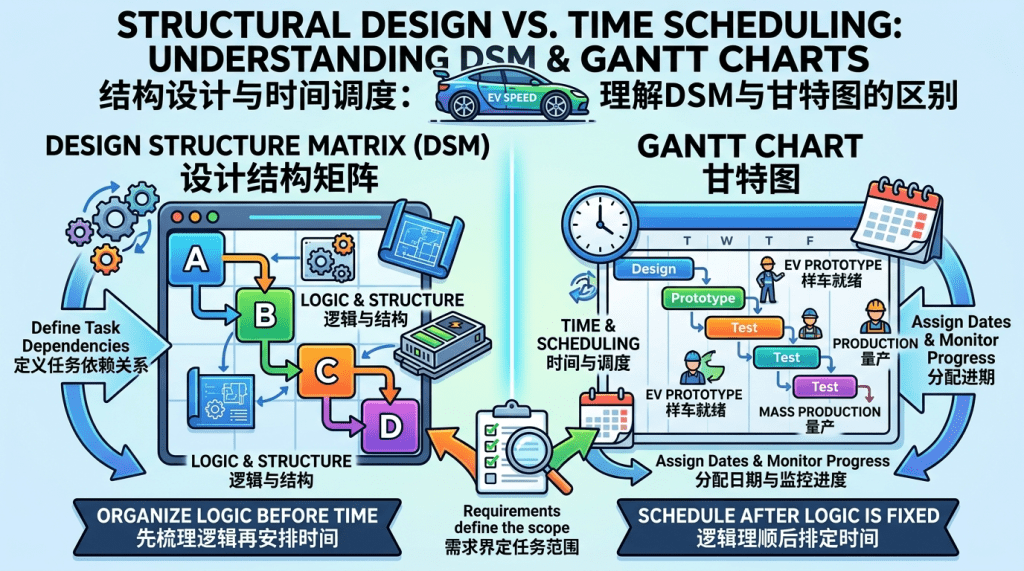
Design Structure Matrix (DSM) and Gantt Charts: Structural Design vs. Time Scheduling
Chris Cui
2026-04-25
The Architecture of Thinking: Cognitive Models for Complex Systems and Decision-Making
Chris Cui
2026-02-08
仙侠演义下的人工智能大道之争
Chris Cui
2025-09-14
Understanding the Forward Deployed Engineer (FDE) Model for AI Startups
Chris Cui
2025-08-20
AI-Powered Search: Google’s Transformation vs. Perplexity
Chris Cui
2025-08-18
小说:见证者 Witness
Chris Cui
1
2
3
…
9
Next Page
Archives
Health
.
Fashion
.
Food
.
Shopping
.
Events
.
Fiction
.
Travel
.
Japan
.
Education
.
Privacy & Cookies: This site uses cookies. By continuing to use this website, you agree to their use.
To find out more, including how to control cookies, see here:
Cookie Policy
Subscribe
Subscribed
C. Cui's Blog
Sign me up
Already have a WordPress.com account?
Log in now.
C. Cui's Blog
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar