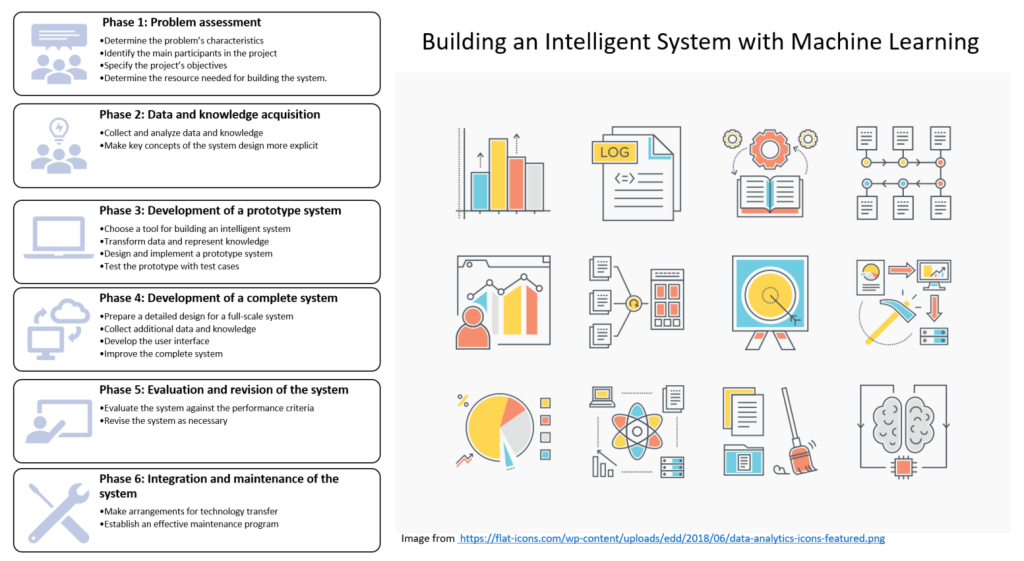
This post is following upgrade with respect to the early post How to Build an Artificial Intelligent System (I) The last one is focused on introducing the six phases of the building an intelligent system, and explaining the details of the Problem Assesment phase.
In the following content, I will address the rest phases and key steps during the building process. Readers can download the keynotes here: Building an Intelligent System with Machine Learning.
1. Problem Assessment
1.1 Determine the problem’s characteristics
The first step of problem assessment is to determine the problem’s characteristics which include the problem types, input/output variables and form/content of the solution.
In general, to tell the type of problems is a typical divide-and-conquer process by recursively breaking down a problem into two or more sub-problems for the same or related types, until these become simple enough to be solved directly by existing tools and knowledge. The key is to “do not rebuild the wheel”.
Tips: In this phase, it will be very helpful to prepare an information board, a whiteboard that has everything you know about this project and makes connections among those elements. Then, initiate and propose a workflow and a data pipeline for the team to discuss and keep track of the progress. This is also good for increasing transparency and knowledge sharing among team members. Keep tracking of the changes of the board, workflow and data pipeline, this will also help you to focus on solving the most important task (i.e. Microsoft whiteboard ).
1.2 Identify the main participants in the projects
Identifying the main participants can be boiled down to find two critical individuals in building an AI system. We need to identify
- The knowledge engineer: a person capable of designing, building and testing an intelligent system.
- The domain expert: a knowledgeable person capable of solving problems in a specific area or domain.
whenever confusion and disagreements happen in the project, these two will represent the R&D and make the final call.
1.3 Specify the project’s objectives
This part should be sent to the project manager who has direct connects with the clients or the leader who is in charge of the project. The most common objectives will be like gaining a competitive edge, improving the quality of decisions, reducing labour costs, and improving the quality of products and services.
1.4 Determine the resource needed for building the system
The final step for problem assessment is to determine what resources are needed for building the system. They normally include computer facilities, development software, knowledge and data sources (human experts, textbooks, manuals, websites, databases and case reports) and funds, of course, among all of these, the most important three are money, money and money.
The project budges control and cost estimation are also very important, you can image how many good projects failed because the fund burns out. Thus, it is very important to limit the expectations with respect to the money you want to spend. Check the movie the-Hummingbird-Project, you will understand what I am saying.
The following two figures summarise Phase 1: problem assessment.


2. Data and knowledge acquisition
In this phase, we need to obtain further understanding of the problem domain by collecting and analysing both data and knowledge, and making key concepts of the system’s design more explicit.
2.1 Data collection: A particular tool for a particular type of data
Data for intelligent systems are often collected from different sources, and thus can be of different types. However, a particular tool for building an intelligent system requires a particular type of data.
Please give up on finding the best tool to collect data, this will never happen.
There are three important issues that must be resolved before managing the data:
- incompatible data: Often the data we want to analyse store text (name, address, time, ..) and numbers (table, images, video, …) in packed decimal format. Symbolic (textual) data need to be converted into standard ASCII code (or UTF-8, ISOXXX) and numerical data to be reviewed as well.
- inconsistent data: Often the same facts the same data are represented differently in different databases. If these differences are not spotted and resolved in time, we lose information in problem analysis, which leads to a biased model or conclusions.
- missing data: Nothing is perfect in this world. Actual data records often contain blank fields. Sometimes we might throw such incomplete records away, but normally we would attempt to infer some useful information from them. In many cases, we can simply fill the blank fields in with the most common or average values. In other cases, the fact that a particular field has not been filled in might itself provide us with very useful information.
Our choice of the system building tool depends on the acquired data. For example, with the imprecise and noisy data, you may prefer to build a rule-based expert system. However, with well-defined and clean data, most machine learning models can be better choices.
2.2 Knowledge acquisition: an inherently iterative process
Knowledge acquisition is an inherently iterative process. Usually, we start with reviewing documents and reading books, papers and manuals related to the problem domain. Once we become familiar with the problem, we can collect further knowledge through interviewing the domain expert. Then we study and analyse the acquired knowledge, and repeat the entire process again.
During a number of interviews, the expert is asked to identify four or five
typical cases, describe how he or she solves each case, and explain, or ‘think out loud’, the reasoning behind each solution.
2.3 Agreement on the key concepts and system design
The data and knowledge acquired during the second phase of knowledge engineering should enable the team to describe the problem-solving strategy at the most abstract, conceptual, level and choose tools for building a prototype. Here, it can be a list of different models to try and compare, but you should start with the most promising one or the easiest one. Do not make a detailed analysis of the problem before evaluating the prototype, because you do not know what will happen in the project even you are an experienced expert.
The following figure summarises Phase 2: Data and knowledge acquisition.

3 Development of a prototype system
The development of a prototype system includes choosing a tool for building the system, transforming data and representing knowledge, designing and implementing the system and testing it with a number of test cases.
3.1 What is a prototype?
A prototype system can be defined as a small version of the final system. It is designed to test how well we understand the problem, or in other words to make sure that the problem-solving strategy, the tool selected for building a system, and techniques for representing acquired data and knowledge are adequate to the task. It also provides us with an opportunity to persuade the sceptics and, in many cases, to actively engage the domain expert in the system’s development.
3.2 Build the prototype
After choosing a tool (AI model), massaging the data and representing the acquired knowledge in the form suitable for that tool, we can design and then implement a prototype version of the system.
Once it is built, we examine (usually together with the domain expert) the prototype’s performance by testing it with a variety of test cases. The domain expert takes an active part in testing the system, and as a result, becomes more involved in the system’s development.
3.3 What is a test case?
A test case is a problem successfully solved in the past for which input data and an output solution are known. During testing, the system is presented with the same input data and its solution is compared with the original solution.
In machine learning, we usually partition the collected data (samples with input and output pairs) into three parts: training dataset, validation dataset, and testing dataset.
- As we know, the training dataset is used to build the model,
- The validation dataset is a sample of data held back from training the model that is used to give an estimate of model skill while tuning model’s hyperparameters. For example, the hyperparameters of neural networks will include the number of layer and nodes (structure), the type of activation functions, the configurations of the learning algorithms (SGD, Adam, RMSprop, …). It is also used to give an unbiased estimate of the skill of the final tuned model when comparing or selecting between different models.
- The testing dataset will be used as the final checking standard of the model’s performance and its generalization ability, which shows us the model learned something instead of memorizing all the data.
3.4 Made a bad choice of the system-building tool?
We should throw the prototype away and start the prototyping phase over again – any attempt to force an ill-chosen tool to suit a problem it wasn’t designed for would only lead to further delays in the system’s development.
The main goal of the prototyping phase is to obtain a better understanding of the problem, and thus by starting this phase with a new tool, we waste neither time nor money.
The following figure summarises Phase 3: Development of a prototype system.

4. Development of a complete system
As soon as the prototype begins functioning satisfactorily, we can assess what is
actually involved in developing a full-scale system. We develop a plan, schedule and budget for the complete system, and also clearly define the system’s performance criteria.
The main work at this phase is often associated with adding data and knowledge to the system including adding special cases.
The next task is to develop the user interface – the means of delivering information to a user. The user interface should make it easy for users to obtain any details they need. Some systems may be required to explain its reasoning process and justify its advice, analysis or conclusion, while others need to represent their results in a graphical form.
Collecting feedback is key to improve user experience (UX).
The development of an intelligent system is, in fact, an evolutionary process. As the project proceeds and new data and knowledge are collected and added to the system, its capability improves and the new features gradually evolves into a final system.

5. Evaluation and revision of the system
Intelligent systems, unlike conventional computer programs, are designed to solve problems that quite often do not have clearly defined ‘right’ and ‘wrong’ solutions.
To evaluate an intelligent system is, in fact, to assure that the system performs the intended task to the user’s satisfaction. A formal evaluation of the system is normally accomplished with the test cases selected by the user.
The system’s performance is compared against the performance criteria that were agreed upon at the end of the prototyping phase. The evaluation often reveals the system’s limitations and weaknesses, so it is revised and relevant development phases are repeated.

6. Integration and maintenance of the system
6.1 System integration and maintenance
This is the final phase of developing the system. It involves integrating the system into the environment where it will operate and establishing an effective maintenance program.
By ‘integrating’ we mean interfacing a new intelligent system with existing systems within an organisation and arranging for technology transfer. We must make sure that the user knows how to use and maintain the system.
Intelligent systems are knowledge-based systems, and because knowledge evolves over time, users need to be able to modify the system. Learning session and Q&A session are both good choices.
6.2 Who maintains the system?
Once the system is integrated into the working environment, the knowledge engineer withdraws from the project. This leaves the system in the hands of its users. Thus, the organisation that uses the system should have the in-house expertise to maintain and modify the system.
6.3 Which tool should we use?
There is no single tool that is applicable to all tasks. AI / Machine Learning / Deep Learning may not cover special needs.
Remember:
“All models are wrong, but some are useful”
6.4 Should the System add GPU support?
Due to the media hype and academia/big-tech buzz of the modern deep learning model, it seems GPU support is necessary, but it is not, or at least not in the new future (5~10 years) in industry.
The main reason is that GPU support will introduce many software dependencies and introduce platform-specific issues.
The starting intelligent system should be easy to install on a wide variety of platforms. Unless the project itself is based on image data and video, i.e., CCTV system, smart city, etc.
Outside of deep neural networks (i.e., ConvNets for image analysis), GPUs don’t play a large role in machine learning today (Just kidding, it already did), and much larger gains in speed can often be achieved by a careful choice of algorithms or models, 🙂
6.5 Be real and rational!
- To apply an intelligent system, one had first to find a “good” problem that has some chance for success.
- Knowledge engineering projects with AI/ML can be expensive, laborious and have high investment risks.
- Today, most general intelligent systems are built within months rather than years.
- Commercial toolboxes (Amazon, Microsoft, Google) can run applications on the cloud or standard PCs.

7. Recording and Documenting
Assume the project has been a great success, the documenting work is the second important one for the long run. How to record the research and development work is crucial to the system maintains and upgrades. Because the developer and experts who were first in building the projects may not be the same ones who will maintain and upgrade it. Thus, here are ten simple rules for reproducible R&D documents:

Download the keynotes: Building an Intelligent System with Machine Learning.
Reference:
[1] Negnevitsky Michael, Artificial Intelligence: A Guide to Intelligent Systems, 2nd edition, Pearson Education (2005).
[2] Adam Rule, Amanda Birmingham, etc. Ten Simple Rules for Reproducible Research in Jupyter Notebooks. arXiv:1810.08055 (2018).



Leave a comment