Skip to content
Facebook
Twitter
Instagram
TikTok
YouTube
Search
C. Cui's Blog
Machine Learning
2026-07-31
Mathematics in the Age of AI: Terence Tao’s Vision for the Mathematical Community
Chris Cui
2026-02-08
仙侠演义下的人工智能大道之争
Chris Cui
2025-07-27
《大模型精诚》两篇
Chris Cui
2025-05-31
Our Future with AI: Three Strategies to Ensure It Stays on Our Side
Chris Cui
2024-10-19
2024 Guest Lecture Notes: AI, Machine Learning and Data Mining in Recommendation System and Entity Matching
Chris Cui
2024-05-26
Is the AI PC a Gimmick or a Faster Carriage?
Chris Cui
2024-05-25
AI Revolutionizes Industry and Retail: From Production Lines to Personalized Shopping Experiences
Chris Cui
2024-05-04
The Future of Coding: Will Generative AI Make Programmers Obsolete?
Chris Cui
2024-02-04
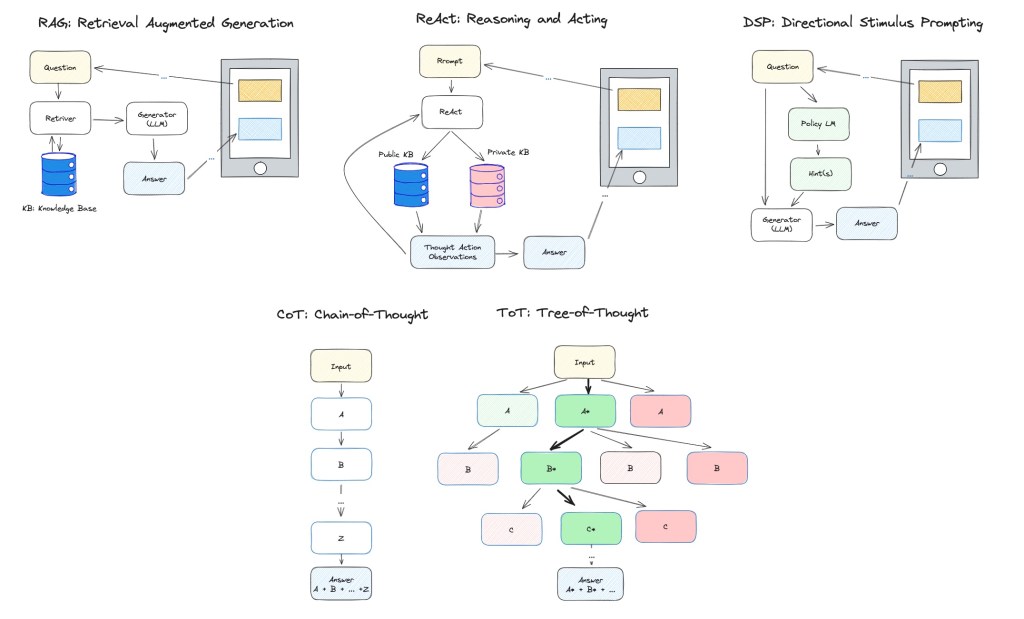
Prompt Engineering for LLM
Chris Cui
1
2
3
Next Page
Archives
Health
.
Fashion
.
Food
.
Shopping
.
Events
.
Fiction
.
Travel
.
Japan
.
Education
.
Privacy & Cookies: This site uses cookies. By continuing to use this website, you agree to their use.
To find out more, including how to control cookies, see here:
Cookie Policy
Subscribe
Subscribed
C. Cui's Blog
Sign me up
Already have a WordPress.com account?
Log in now.
C. Cui's Blog
Subscribe
Subscribed
Sign up
Log in
Report this content
View site in Reader
Manage subscriptions
Collapse this bar