
[2023-06 Update Review]: add more details about related terms for better understanding.
In this blog, I will review the Classic Technical Framework of the modern (Deep Learning) recommendation system (aka. recommender system).
Before Starting
Before I start, I want to ask readers a question:
What is the first thing you want to do when you start learning a new field X?
Of course, everyone has their own answers, but for me, there are two questions I want to know the most at the beginning. Here X is the recommender system.
What problem is this X trying to solve?
Is there a high-level mind map so that I can understand the basic concepts, main technologies and development requirements in this X?
Moreover, for the field of “deep learning recommendation system”, there may be a third question.
Why do people keep emphasizing “deep learning“, and what revolutionary impact does deep learning bring to the recommendation system?
I hope you will find answers to these three questions after reading this blog.
What is the fundamental problem to be solved by a recommender system?
The applications of recommender systems have gotten into all aspects of life, such as shopping, entertainment, and learning. Although the recommendation scenarios such as product recommendation, video recommendation, and news recommendation may be completely different, since they are all called “recommender systems”, the essential problem to be solved must be the same and follow a common logical framework.
The problem to be solved by the recommender system can be summed up in one sentence:
In the information overload era, how can Users efficiently obtain the Items of their interest?
Therefore, the recommendation system is a bridge built between “the overloaded Internet information” and “users’ interests“.
Let’s look at the recommender system’s abstract logical architecture, and then build its technical architecture step by step, so you can have an overall impression of the entire system.
The logical architecture of the recommender system
Starting from the fundamental problem of the recommendation system, we can clearly see that the recommendation system is actually dealing with the relationship between “people” and “information“. That is, based on “people” and “information” to construct a method of finding interesting information for the people.
- User – From the perspective of “people“, in order to more reliably infer the interests of “people”, the recommender system hopes to use a large amount of information related to “people”, including historical behaviour, population attributes, relationship networks, etc. They may be collectively referred to as “User Information“.
- Item – The definition of “information” has specific meanings and diverse interpretations in different scenarios. For example, it refers to “product information” in product recommendations, “video information” in video recommendations, and “news information” in news recommendations. We can collectively refer to them as “Item Information” for convenience.
- Content – In addition, in a specific recommendation scenario, the user’s final selection is generally affected by a series of environmental information such as time, location, and user status, which can also be called “scene information” or “context information”.
With these definitions, the problem to be dealt with by the recommender system can be formally defined as:
For a certain user U (User), in a specific scenario C (Context), build a function for massive “item” information, predict the user’s preference for a specific candidate item I (Item), and then sort all candidate items according to the preference to generate a recommendation list.
In this way, we can abstract the logical framework of the recommender system, as shown in Figure 1. Although this logical framework is relatively simple, it is on this simple basis that we can refine and expand each module to produce the entire technical system.
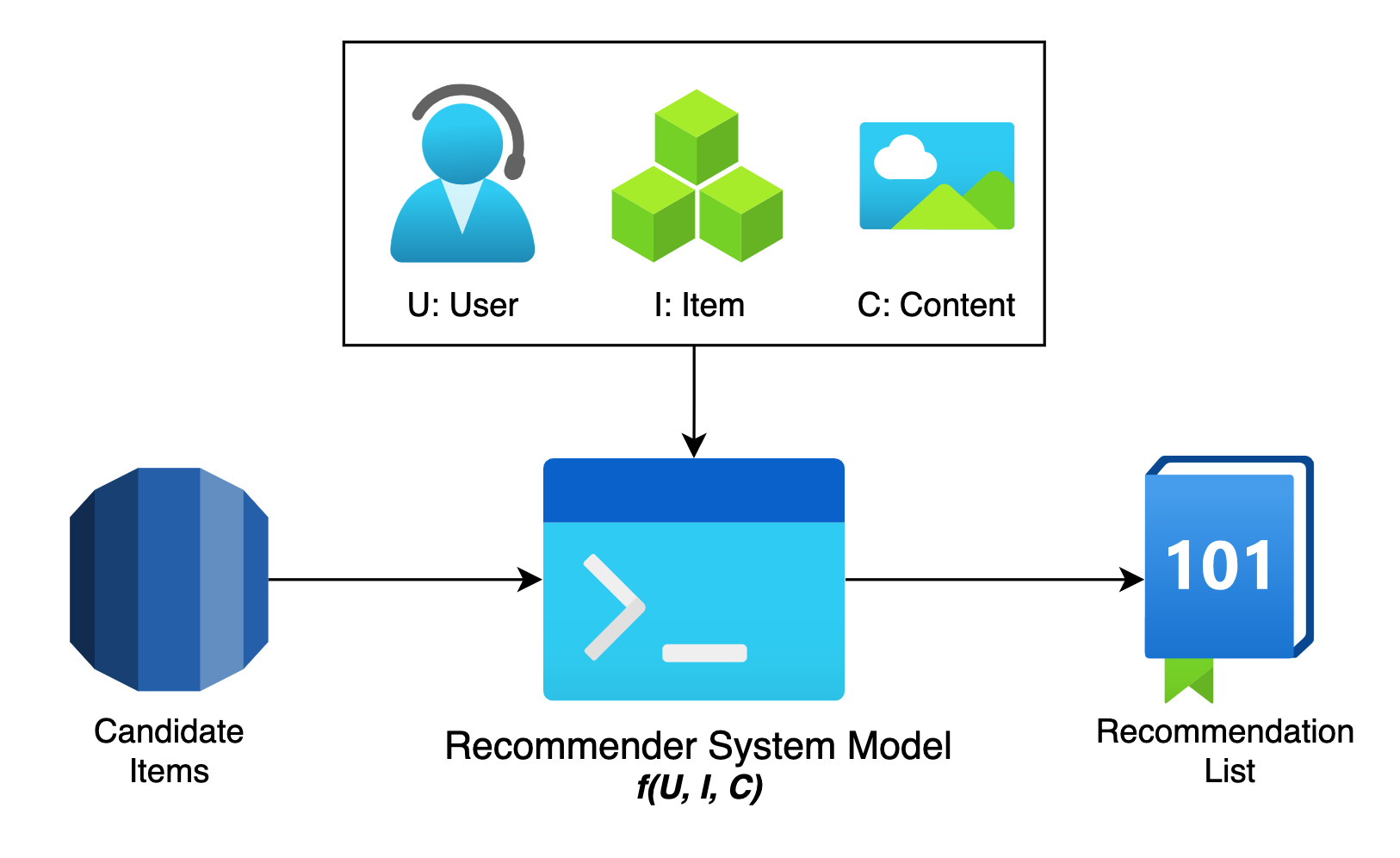
The Revolution of Deep Learning for Recommender Systems
With the logical architecture of the recommender system (Figure 1), we can answer the third question from the beginning:
“What revolutionary impact does deep learning bring to the recommender system?“
In the logic architecture diagram, the central position is an abstract function f(U, I, C), which is responsible for “guessing” the user’s heart and “scoring” the items that the user may be interested in so as to obtain the final recommended item list. In the recommender system, this function is generally referred to as the “recommendation system model” (hereinafter referred to as the “recommendation model“).
The application of deep learning to recommendation systems can greatly enhance the fitting and expressive capabilities of recommendation models. Simply put, deep learning aims to make the recommendation model “guess more accurately” and better capture the “heart” of users.
So you may still not have a clear concept. Next, let’s compare the difference between the traditional machine learning recommendation model and the deep learning recommendation model from the perspective of the model structure so that you can have a clearer understanding.
Here is a model structure comparison chart in Figure 2, which compares the difference between the traditional Matrix Factorization model and the Deep Learning Matrix Factorization model.
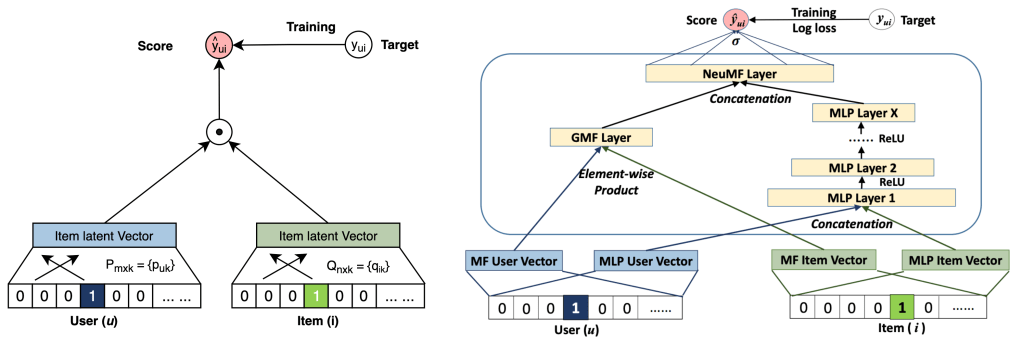
Let’s ignore the details for now. How do you feel at first glance?
Do you feel that the deep learning model has become more complex, layer after layer, and the number of layers has increased a lot?
In addition, the flexible model structure of the deep learning model also gives it an irreplaceable advantage; that is, we can let the neural network of the deep learning model simulate the changing process of many user interests and even the thinking process of the user making a decision.
For example, Alibaba‘s deep learning model, Deep Interest Evolution Network (Figure 3 DIEN), uses the structure of a three-layer sequence model to simulate the process of users’ interest evolution when purchasing goods, while such a powerful data fitting ability to interpret user behaviour is not available in traditional machine learning models.
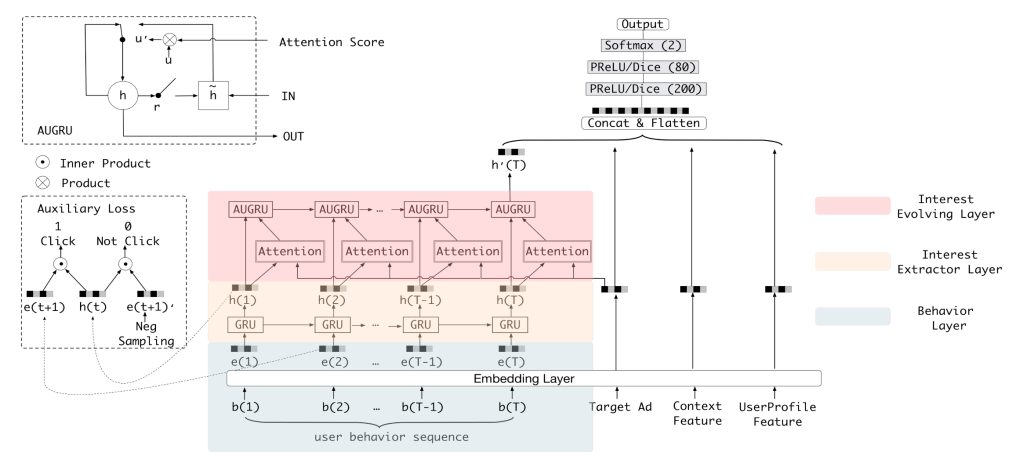
Moreover, the revolutionary impact of deep learning on recommender systems goes far beyond that. In recent years, due to the greatly increased structural complexity of deep learning models, more and more data streams are required to converge for the model training, testing and serving. The data storage, processing and updating modules related to the recommender systems on the cloud computing platforms have also entered the “deep learning era”.
After talking so much about the impact of deep learning on recommender systems, we seem to have not seen a complete deep learning recommender system architecture. Don’t worry. Let’s talk about what the technical architecture of a classic deep-learning recommender system looks like in the next section.
Technical Architecture of Deep Learning Recommendation System
The architecture of the deep learning recommender system is in the same line as the classic one. It improves some specific modules of the classic architecture to enable and support the application of deep learning. So, I will first talk about the classic recommender system architecture and then talk about deep learning and its improvements.
In the actual recommender system, there are two types of problems that engineers need to focus on in projects.
Type 1 is about data and information. What are “user information”, “item information”, and “scenario information”? How to store, update and process these data?
Type 2 is on recommendation algorithms and models. How to train, predict, and achieve better recommendation results for the system?
An industrial recommendation system’s technical architecture is based on these two parts.
- The “data and information” part has gradually developed into a data flow framework that integrates offline (nearline) batch processing of data and real-time stream processing in the recommender system.
- The “model and algorithm” part is further refined into a model framework that integrates training, evaluation, deployment, and online inference in the recommender system.
Based on this, we can summarize the technical architecture diagram of the recommender system as in Figure 4.
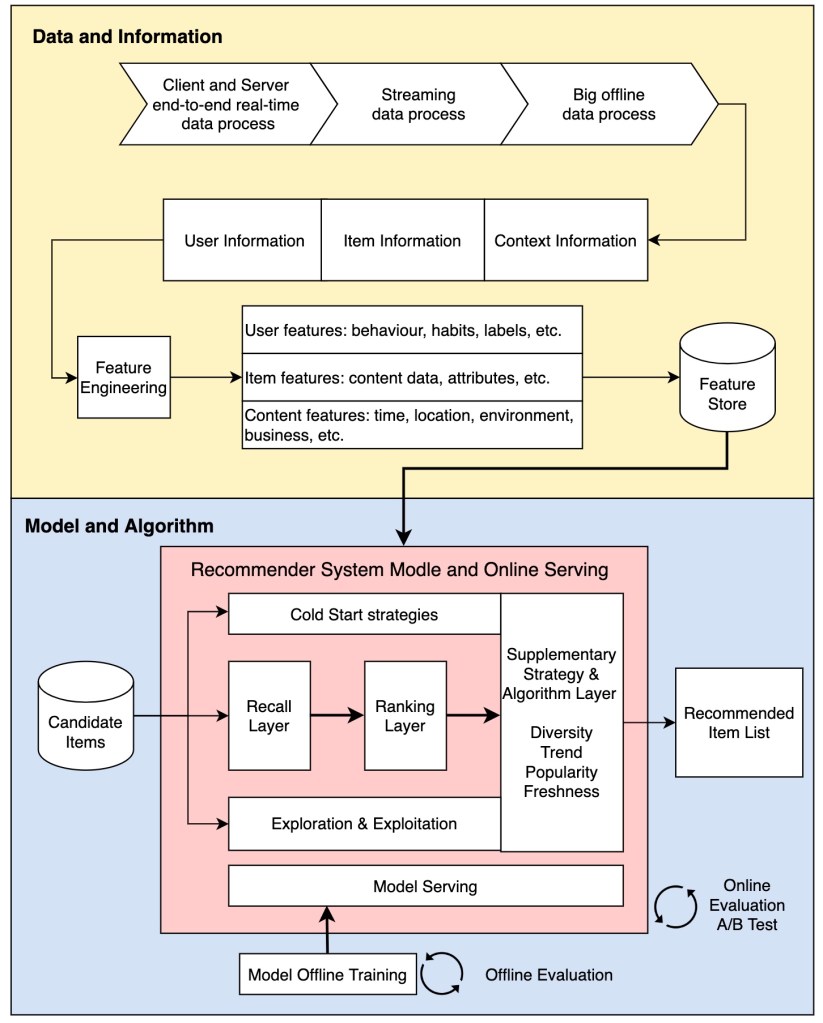
In Figure 4, I divided the technical architecture of the recommender system into a “data part” and a “model part”.
Part 1: Data Framework
The “data part” of the recommender system is mainly responsible for the collection and processing of “user“, “item” and “content” information. Based on the difference in the amount of data and the real-time processing requirements, we use three different data processing methods sorted by order of real-time performance, they are:
- Client and Server end-to-end real-time data processing.
- Real-time stream data processing.
- Big data offline processing.
From 1 to 3, the real-time performance of these methods decreases from strong to weak, and the massive data processing capabilities of the three methods increase from weak to strong.
| Method | Real-Time Performance | Data Processing Capability | Possible Solutions |
| Client and Server end-to-end real-time data processing | Strong | Weak | Flink |
| Real-time stream data processing | Medium | Medium | … |
| Big data offline processing | Weak | Strong | Spark |
Therefore, the data flow system of a mature recommender system will complement each other and use them together.
The big data computing platform (e.g., AWS, Azure, GCP, etc.) of the recommender system can extract training data, feature data, and statistical data through the processing of the system logs and metadata of items and users. So what are these data for?
Specifically, there are three downstream applications based on the data exported from the data platform:
- Generate the Sample Data required by the recommender system model for the training and evaluation of the algorithm model.
- Generate “user features“, “item features” and a part of “content features” required by the recommendation system model service (Model Serving) for online inference.
- Generate statistical data required for System Monitoring and Business Intelligence (BI) systems.
The data part is the “water source” of the entire recommender system. Only by ensuring the continuity and purity of the “water source” can we continuously “nourish” the recommender system so that it can operate efficiently and output accurately.
In the deep learning era, models have higher requirements for “water sources”. First of all, the amount of water must be large. Only in this way can we ensure that the deep learning models we build can converge as soon as possible; Secondly, the “water flow” should be fast so that the data can flow to the system modules for model updates and adjustments. Thus, the model can grasp the changes in user interest in real time. This is the same reason causing the rapid development and application of big data engine (Spark) and the stream computing platform (Flink).
Part II: Model Framework
The “model part” is the major body of the recommender system. The structure of the model is generally composed of a “recall layer“, a “ranking layer”, and a “supplementary (auxiliary) strategy and algorithm layer“.
- The “recall layer” is generally composed of efficient recall rules, algorithms or simple models, which allow the recommender system to quickly recall items that users may be interested in from a massive candidate set.
- The “ranking layer” uses the ranking/sorting model(s) to fine-sort-rank the candidate items that are initially screened by the recall layer.
- The “supplementary strategy and algorithm layer“, also known as the “re-ranking layer“, is a combination of some supplements to take into account indicators such as “diversity“, “popularity” and “freshness” of the results before returning to the user recommendation list. The strategy and algorithm make more adjustments to the item list and finally form a user-visible recommendation list.
The “model serving process” means the recommender system model receives a full candidate item set and then generates the recommendation list.
In order to optimise the model parameters required by the model service process, we need to determine the model structure, the specific values of the different parameter weights in the structure, and the parameter values in the model-related algorithms and strategies through model training.
The training methods can be divided into “offline training” and “online updating” according to different environments.
- The advantage of offline training is that the optimizer can use the full samples and all the features to build the model approach to the global optimal performance.
- While online updating can “digest” new data samples in real-time, learn and reflect new data trends more quickly, and meet the real-time recommending requirements.
In addition, in order to evaluate the performance of the recommender system model and optimize the model iteratively, the model part of the recommender system also includes various evaluation modules such as “offline evaluation” and “online A/B test“, which are used to obtain offline and online indicators to guide the model iteration and optimization.
We just said that the revolution of deep learning for recommender systems is in the model part, so what are the specifics?
I summarized the most typical deep learning applications into 3 points:
- The application of embedding technology in the recall layer in deep learning. Embedding technology of deep learning is already a mainstream solution in the industry to support the recall layer to quickly generate user-related items.
- The application of deep learning models with different structures in the ranking layer. The ranking layer (also known as the fine sorting layer) is the most important factor affecting the system’s performance, and it is also the area where deep learning models show their strengths. The deep learning model has high flexibility and strong expressive ability, making it suitable for accurately sorting under large data volumes. Undoubtedly, the deep learning ranking model is a hot topic in both industry and academia. It will keep gaining investments and being rapidly iterated by researchers and engineers.
- The application of reinforcement learning in the direction of model updating and integration (CI/CD). Reinforcement learning is another field of machine learning closely related to deep learning. Its application in recommender systems enables the systems to take a higher level of real-time performance.
Summary
In this blog, I reviewed the technical architecture of the deep learning recommendation system. Although it involves a lot of content, you don’t have to worry about it if you cannot remember all the details. All you need is to keep the impression of this framework in your mind.
You can use the content of this framework as a technical index of a recommender system, making it your own knowledge map. Visually speaking, you can think of the content of this blog as a tree of knowledge, which has roots, stems, branches, leaves, and flowers.
Let’s recall the most important concepts again:
- The root is that the recommender system aims to solve the challenge of how to help users efficiently obtain the items of interest in this “information overload” era.
- The stems of the recommender system are the logical architecture of the recommendation system: for a user U (User), in a specific scenario C (Context), a function is constructed for a large number of “items” (products, videos, etc.) to predict the user’s response to a specific candidate item I (Item). ) with the degree of preference.
- The branches and leaves are the technical modules of the recommender system and the algorithms/models of each module, respectively. The technical module is responsible for supporting the system’s technical architecture. Using algorithms and models, we can create diverse functions within the system and provide accurate results.
Finally, the application of deep learning is undoubtedly the pearl of the current technical architecture of recommender systems. It is like a flower blooming on this big tree, and it is the most wonderful finishing touch.
The structure of the deep learning model is complex, but its data fitting ability and expression ability is stronger, so the recommender model can better simulate the user’s interest-changing process and even the decision-making process. The development of deep learning has also promoted a revolution in the data flow framework, leading to higher requirements for cloud computing service providers to process the data faster and stronger.
Hope you like this blog. To be continued the Next Blog will be Deep Learning Recommender Systems Part 2: Feature Engineering.
One more thing…
Figure 5 is the recommender system of Netflix. Here is the challenge, can you combine the technical framework of the recommender system discussed in this blog to tell which parts are the data part and which are the model part in the diagram?
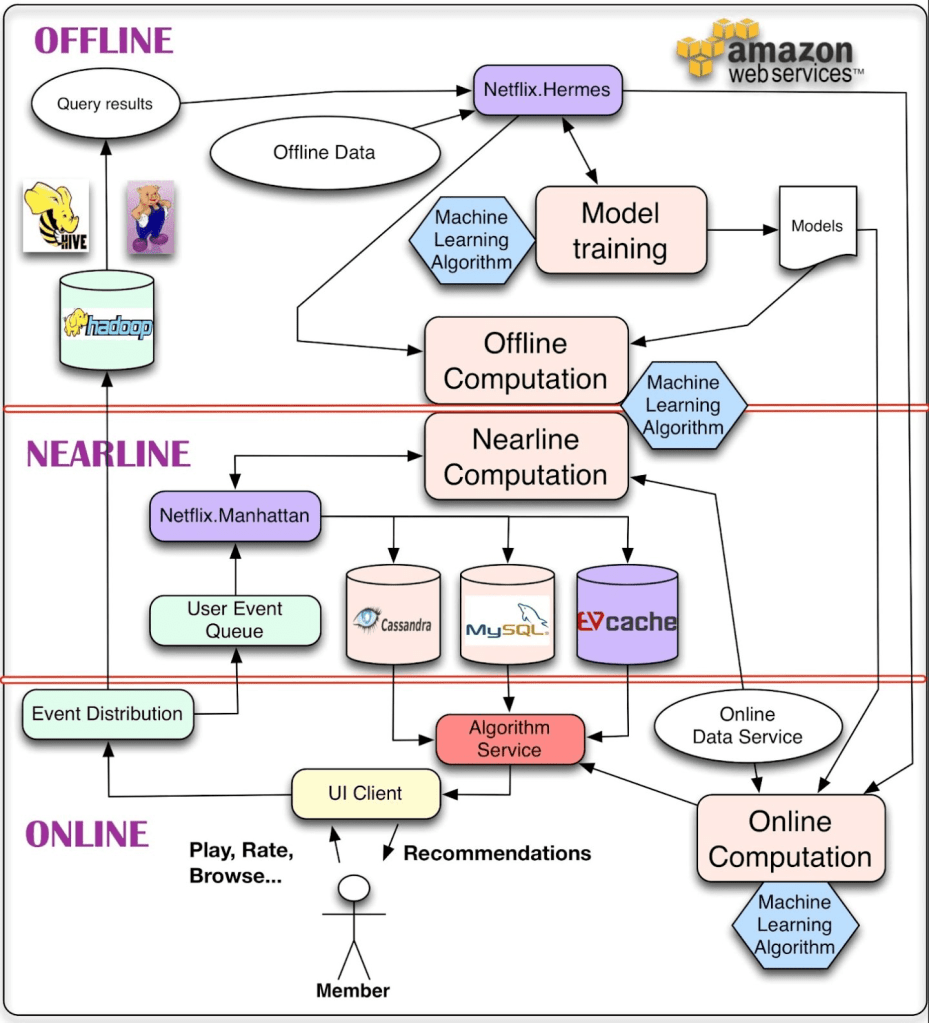
Reference:
- [1] 极客时间《深度学习推荐系统实战》, 王喆 Roku 推荐系统架构负责人,前 hulu 高级研究员,《深度学习推荐系统》作者.
- [2] He, Xiangnan, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. “Neural collaborative filtering.” In Proceedings of the 26th international conference on world wide web, pp. 173-182. 2017.
- [3] Zhou, Guorui, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. “Deep interest evolution network for click-through rate prediction.” In Proceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, pp. 5941-5948. 2019.



Leave a comment