Latest
-

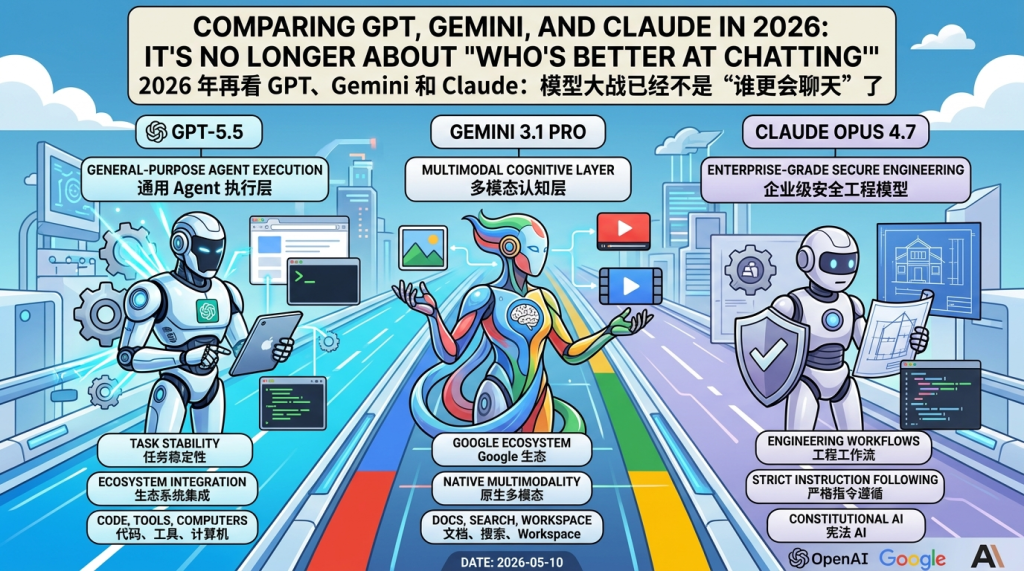
Mathematics in the Age of AI: Terence Tao’s Vision for the Mathematical Community
TL;DR [中文] In Terence Tao’s ICM 2026 public lecture Mathematics in the Age of AI, his central question was not simply, “Can AI do mathematics?” but rather: If AI can soon complete a significant portion of research-level mathematical tasks, what should the mathematical community optimise, and what must it protect? As proofs move from scarcity…