“On the Sincerity and Mastery in Large Models” is a two-part essay inspired by Sun Simiao’s classical Chinese text On the Absolute Sincerity of Great Physicians. Written in classical Chinese style, it warns against superficial understanding and blind faith in large language models (LLMs). It calls for practitioners to uphold a spirit of diligence (“精”) and sincerity (“诚”)—to understand the inner principles of algorithms and the biases within data. The model is but a tool; its moral compass lies in the human operator. Only by combining technical rigor with ethical restraint can AI serve humanity and avoid causing harm. This is both a philosophical treatise on AI and a critique of today’s hasty tech culture.
Mark Zuckerberg’s recent move to bring Alex Wang and his team into Meta represents a bold and strategic maneuver amid the rapid advancement of large models and AGI development. Putting aside the ethical considerations, Zuckerberg’s approach—laying off staff, then offering sky-high compensation packages with a 48-hour ultimatum to Top AI scientists and engineers from OpenAI , alongside Meta’s acquisition of a 49% stake in Scale AI—appears to serve multiple objectives:
1. Undermining Competitors
By poaching key talent from rival companies, Meta not only weakens their R&D teams and disrupts their momentum but also puts pressure on Google, OpenAI, and others to reassess their partnerships with Scale AI. Meta’s investment may further marginalize these competitors by injecting uncertainty into their collaboration with Scale AI.
2. Reinvigorating the Internal Team
Bringing in fresh blood like Alex Wang’s team and Open AI Top talents could reenergize Meta’s existing research units. A successful “talent reset” may help the company gain a competitive edge in the race toward AGI.
3. Enhancing Brand Visibility
Even if the move doesn’t yield immediate results, it has already amplified Meta’s media presence, boosting its reputation as a leader in AI innovation.
From both a talent acquisition and PR standpoint, this appears to be a masterstroke for Meta.
However, the strategy is not without significant risks:
1. Internal Integration and Morale Challenges
The massive compensation packages offered to those talents could trigger resentment among existing employees—especially in the wake of recent layoffs—due to perceived pay inequity. This may lower morale and even accelerate internal attrition. Cultural differences between the incoming and incumbent teams could further complicate internal integration and collaboration.
2. Return on Investment and Performance Pressure
Meta’s substantial investment in Alex Wang and Scale AI comes with high expectations for short-term deliverables. In a domain as uncertain as AGI, both the market and shareholders will be eager for breakthroughs. If Wang’s team fails to deliver measurable progress quickly, Meta could face mounting scrutiny and uncertainty over the ROI.
3. Impacts on Scale AI and the Broader Ecosystem
Alex Wang stepping away as CEO is undoubtedly a major loss for Scale AI, even if he retains a board seat. Leadership transitions and potential talent departures may follow. Moreover, Scale AI’s history of legal and compliance issues could reflect poorly on Meta’s brand—especially if public perception ties Meta to those concerns despite holding only non-voting shares. More broadly, Meta’s aggressive “poaching” approach may escalate the AI talent war, drive up industry-wide costs, and prompt renewed debate over ethics and hiring norms in the AI sector.
Conclusion Meta’s latest move is undeniably ambitious. While it positions the company aggressively in the AGI race, it also carries notable risks in terms of internal dynamics, ROI pressure, and broader ecosystem disruption. Only time will tell whether this bold gamble pays off.
AI technology is increasingly being utilized in industry and retail sectors to enhance efficiency, productivity, and customer experiences. In this post, we firstly revisit the relationship between the industry and retail sections, then provide some common AI technologies and applications used in these domains.
Industry and Retail Relationship
The key difference between industry and retail lies in their primary functions and the nature of their operations:
Industry:
Industry, often referred to as manufacturing or production, involves the creation, extraction, or processing of raw materials and the transformation of these materials into finished goods or products.
Industrial businesses are typically involved in activities like manufacturing, mining, construction, or agriculture.
The primary focus of the industry is to produce goods on a large scale, which are then sold to other businesses, wholesalers, or retailers. These goods are often used as inputs for other industries or for further processing.
Industries may have complex production processes, rely on machinery and technology, and require substantial capital investment.
Retail:
Retail, on the other hand, involves the sale of finished products or goods directly to the end consumers for personal use. Retailers act as intermediaries between manufacturers or wholesalers and the end customers.
Retailers can take various forms, including physical stores, e-commerce websites, supermarkets, boutiques, and more.
Retailers may carry a wide range of products, including those manufactured by various industries. They focus on providing a convenient and accessible point of purchase for consumers.
Retail operations are primarily concerned with merchandising, marketing, customer service, inventory management, and creating a satisfying shopping experience for consumers.
AI in Industry
AI, or artificial intelligence, is revolutionizing industry sectors by powering various applications and technologies that enhance efficiency, productivity, and customer experiences. Here are some common AI technologies and applications used in these domains:
1. Robotics and Automation: AI-driven robots and automation systems are used in manufacturing to perform repetitive, high-precision tasks, such as assembly, welding, and quality control. Machine learning algorithms enable these robots to adapt and improve their performance over time.
2. Predictive Maintenance: AI is used to predict when industrial equipment, such as machinery or vehicles, is likely to fail. This allows companies to schedule maintenance proactively, reducing downtime and maintenance costs.
3. Quality Control: Computer vision and machine learning algorithms are employed for quality control processes. They can quickly identify defects or irregularities in products, reducing the number of faulty items reaching the market.
4. Supply Chain Optimization: AI helps in optimizing the supply chain by predicting demand, managing inventory, and optimizing routes for logistics and transportation.
5. Process Optimization: AI can optimize manufacturing processes by adjusting parameters in real time to increase efficiency and reduce energy consumption.
6. Safety and Compliance: AI-driven systems can monitor and enhance workplace safety, ensuring that industrial facilities comply with regulations and safety standards.
AI in Retail
AI technology is revolutionizing the retail sector too, introducing innovative solutions and transforming the way businesses engage with customers. Here are some key AI technologies and applications used in retail:
1. Personalized Marketing: AI is used to analyze customer data and behaviours to provide personalized product recommendations, targeted marketing campaigns, and customized shopping experiences.
2. Chatbots and Virtual Assistants: Retailers employ AI-powered chatbots and virtual assistants to provide customer support, answer queries, and assist with online shopping.
3. Inventory Management: AI can optimize inventory levels and replenishment by analyzing sales data and demand patterns, reducing stockouts and overstock situations.
4. Price Optimization: Retailers use AI to dynamically adjust prices based on various factors, such as demand, competition, and customer behaviour, to maximize revenue and profits.
5. Visual Search and Image Recognition: AI enables visual search in e-commerce, allowing customers to find products by uploading images or using images they find online.
6. Supply Chain and Logistics: AI helps optimize supply chain operations, route planning, and warehouse management, improving efficiency and reducing costs.
7. In-Store Analytics: AI-powered systems can analyze in-store customer behaviour, enabling retailers to improve store layouts, planogram designs, and customer engagement strategies.
8. Fraud Detection: AI is used to detect and prevent fraudulent activities, such as credit card fraud and return fraud, to protect both retailers and customers.
Summary
AI’s potential to transform industry and retail is huge and its future applications are very promising. As AI technologies advance, we can expect increased levels of automation, personalization, and optimization in industry and retail operations.
AI technologies in these sectors often rely on machine learning (ML), deep learning (DL), natural language processing (NLP), and computer vision (CV), and now Generative Large Language Models (LLM) to analyze and gain insights from data. These AI applications are continuously evolving and are changing the way businesses in these sectors operate, leading to improved processes and customer experiences.
AI will drive high levels of efficiency, innovation, and customer satisfaction in these sectors, ultimately revolutionizing the way businesses operate and interact with consumers.
Prompt engineering is like adjusting audio without opening the equipment.
Introduction
Prompt Engineering, also known as In-Context Prompting, refers to methods for communicating with a Large Language Model (LLM) like GPT (Generative Pre-trained Transformer) to manipulate/steer its behaviour for expected outcomes without updating, retraining or fine-tuning the model weights.
Researchers, developers, or users may engage in prompt engineering to instruct a model for specific tasks, improve the model’s performance, or adapt it to better understand and respond to particular inputs. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.
This post only focuses on prompt engineering for autoregressive language models, so nothing with image generation or multimodality models.
Basic Prompting
Zero-shot and few-shot learning are the two most basic approaches for prompting the model, pioneered by many LLM papers and commonly used for benchmarking LLM performance. That is to say, Zero-shot and few-shot testing are scenarios used to evaluate the performance of large language models (LLMs) in handling tasks with little or no training data. Here are examples for both:
Zero-shot
Zero-shot learning simply feeds the task text to the model and asks for results.
Scenario: Text Completion (Please try the following input in ChatGPT or Google Bard)
Input:
Task: Complete the following sentence:
Input: The capital of France is ____________.
Output (ChatGPT / Bard):
Output: The capital of France is Paris.
Few-shot
Few-shot learning presents a set of high-quality demonstrations, each consisting of both input and desired output, on the target task. As the model first sees good examples, it can better understand human intention and criteria for what kinds of answers are wanted. Therefore, few-shot learning often leads to better performance than zero-shot. However, it comes at the cost of more token consumption and may hit the context length limit when the input and output text are long.
Scenario: Text Classification
Input:
Task: Classify movie reviews as positive or negative.
Examples: Review 1: This movie was amazing! The acting was superb. Sentiment: Positive Review 2: I couldn't stand this film. The plot was confusing. Sentiment: Negative
Question: Review: I'll bet the video game is a lot more fun than the film. Sentiment:____
Output
Sentiment: Negative
Many studies have explored the construction of in-context examples to maximize performance. They observed that the choice of prompt format, training examples, and the order of the examples can significantly impact performance, ranging from near-random guesses to near-state-of-the-art performance.
Hallucination
In the context of Large Language Models (LLMs), hallucination refers to a situation where the model generates outputs that are incorrect or not grounded in reality. A hallucination occurs when the model produces information that seems plausible or coherent but is actually not accurate or supported by the input data.
For example, in a language generation task, if a model is asked to provide information about a topic and it generates details that are not factually correct or have no basis in the training data, it can be considered as hallucination. This phenomenon is a concern in natural language processing because it can lead to the generation of misleading or false information.
Addressing hallucination in LLMs is a challenging task, and researchers are actively working on developing methods to improve the models’ accuracy and reliability. Techniques such as fine-tuning, prompt engineering, and designing more specific evaluation metrics are among the approaches used to mitigate hallucination in language models.
Perfect Prompt Formula for ChatBots
For personal daily documenting work such as text generation, there are six key components making up the perfect formula for ChatGPT and Google Bard:
Task, Context, Exemplars, Persona, Format, and Tone.
Prompt Formula for ChatBots
The Task sentence needs to articulate the end goal and start with an action verb.
Use three guiding questions to help structure relevant and sufficient Context.
Exemplars can drastically improve the quality of the output by giving specific examples for the AI to reference.
For Persona, think of who you would ideally want the AI to be in the given task situation.
Visualizing your desired end result will let you know what format to use in your prompt.
And you can actually use ChatGPT to generate a list of Tone keywords for you to use!
If you are ever curious about what the heck are those techies talking about with the above words? Please continues …
OK, so here’s the deal. We’re diving into the world of academia, talking about machine learning and large language models in the computer science and engineering domains. I’ll try to explain it in a simple way, but you can always dig deeper into these topics elsewhere.
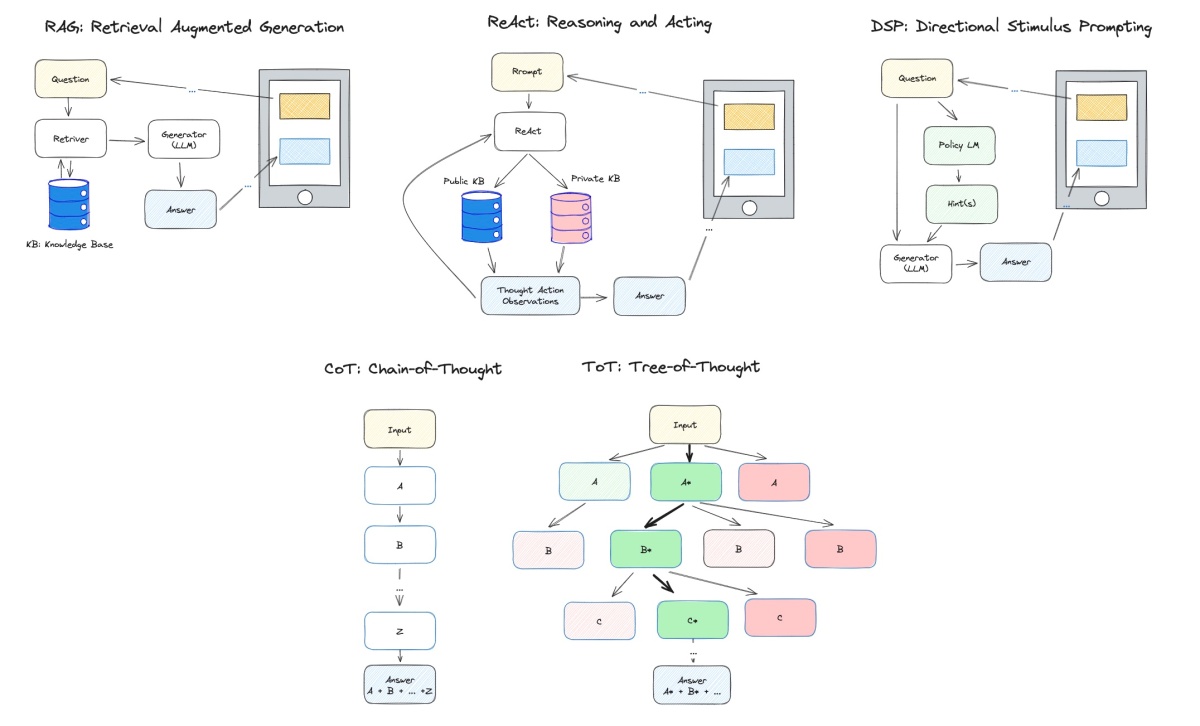
RAG: Retrieval-Augmented Generation
RAG (Retrieval-Augmented Generation): RAG typically refers to a model that combines both retrieval and generation approaches. It might use a retrieval mechanism to retrieve relevant information from a database or knowledge base and then generate a response based on that retrieved information. In real applications, the users’ input and the model’s output will be pre/post-processed to follow certain rules and obey laws and regulations.
RAG: Retrieval-Augmented Generation
Here is a simplified example of using a Retrieval-Augmented Generation (RAG) model for a question-answering task. In this example, we’ll use a system that retrieves relevant passages from a knowledge base and generates an answer based on that retrieved information.
Input:
User Query: What are the symptoms of COVID-19?
Knowledge Base:
1. Title: Symptoms of COVID-19 Content: COVID-19 symptoms include fever, cough, shortness of breath, fatigue, body aches, loss of taste or smell, sore throat, etc.
2. Title: Prevention measures for COVID-19 Content: To prevent the spread of COVID-19, it's important to wash hands regularly, wear masks, practice social distancing, and get vaccinated.
3. Title: COVID-19 Treatment Content: COVID-19 treatment involves rest, hydration, and in severe cases, hospitalization may be required.
RAG Model Output:
Generated Answer:
The symptoms of COVID-19 include fever, cough, shortness of breath, fatigue, body aches, etc.
Remark: ChatGPT 3.5 will give basic results like the above. But, Google Bard will provide extra resources like CDC links and other sources it gets from the Search Engines. We could guess Google used a different framework to OpenAI.
CoT: Chain-of-Thought
Chain-of-thought (CoT) prompting (Wei et al. 2022) generates a sequence of short sentences to describe reasoning logics step by step, known as reasoning chains or rationales, to eventually lead to the final answer.
The benefit of CoT is more pronounced for complicated reasoning tasks while using large models (e.g. with more than 50B parameters). Simple tasks only benefit slightly from CoT prompting.
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, essentially creating a tree structure. The search process can be BFS or DFS while each state is evaluated by a classifier (via a prompt) or majority vote.
CoT : Chain-of-Thought and ToT: Tree-of-Thought
Self-Ask + Search Engine
Self-Ask (Press et al. 2022) is a method to repeatedly prompt the model to ask follow-up questions to construct the thought process iteratively. Follow-up questions can be answered by search engine results.
Self-Ask+Search Engine Example
ReAct: Reasoning and Acting
ReAct (Reason + Act; Yao et al. 2023) combines iterative CoT prompting with queries to Wikipedia APIs to search for relevant entities and content and then add it back into the context.
In each trajectory consists of multiple thought-action-observation steps (i.e. dense thought), where free-form thoughts are used for various purposes.
Specifically, from the paper, the authors use a combination of thoughts that decompose questions (“I need to search x, find y, then find z”), extract information from Wikipedia observations (“x was started in 1844”, “The paragraph does not tell x”), perform commonsense (“x is not y, so z must instead be…”) or arithmetic reasoning (“1844 < 1989”), guide search reformulation (“maybe I can search/lookup x instead”), and synthesize the final answer (“…so the answer is x”).
DSP: Directional Stimulus Prompting
Directional Stimulus Prompting (DSP, Z. Li 2023), is a novel framework for guiding black-box large language models (LLMs) toward specific desired outputs. Instead of directly adjusting LLMs, this method employs a small tunable policy model to generate an auxiliary directional stimulus (hints) prompt for each input instance.
DSP: Directional Stimulus Prompting
Summary and Conclusion
Prompt engineering involves carefully crafting these prompts to achieve desired results. It can include experimenting with different phrasings, structures, and strategies to elicit the desired information or responses from the model. This process is crucial because the performance of language models can be sensitive to how prompts are formulated.
I believe a lot of researchers will agree with me. Some prompt engineering papers don’t need to be 8 pages long. They could explain the important points in just a few lines and use the rest for benchmarking.
As researchers and developers delve further into the realms of prompt engineering, they continue to push the boundaries of what these sophisticated models can achieve.
To achieve this, it’s important to create a user-friendly LLM benchmarking system that many people will use. Developing better methods for creating prompts will help advance language models and improve how we use LLMs. These efforts will have a big impact on natural language processing and related fields.
The post first discusses different interface technologies used to connect people with language models. These include zero-shot prompting, few-shot prompting, in-context learning, and instruction. It explains the differences between zero-shot and few-shot learning and their advantages and limitations.
Next, it explores the concept of in-context learning, where language models can predict new examples by looking at existing ones without changing their parameters. It compares in-context learning with fine-tuning and highlights the differences between the two approaches.
The post then focuses on instructing understanding, dividing it into two categories: research-oriented and human/customer needs-oriented instruction. It emphasizes the importance of considering actual user needs in instruct-based tasks.
Lastly, it suggests a possible connection between in-context learning and instruction, proposing that language models could generate task descriptions based on real task instances. It mentions a study that shows improved performance when using instruction derived from this method.
Interface with LLM
Generally, the interface technologies between people and LLM that we often mention include zero-shot prompting, few-shot prompting, In-Context Learning, and instruction. These are actually ways of describing a specific task. But if you look at the literature, you will find that the names are quite confusing.
Zero-shot learning simply feeds the task text to the model and asks for results.
Text: i'll bet the video game is a lot more fun than the film. Sentiment:
Few-shot learning presents a set of high-quality demonstrations, each consisting of both input and desired output, on the target task. As the model first sees good examples, it can better understand human intention and criteria for what kinds of answers are wanted. Therefore, few-shot learning often leads to better performance than zero-shot. However, it comes at the cost of more token consumption and may hit the context length limit when the input and output text are long.
Text: (lawrence bounces) all over the stage, dancing, running, sweating, mopping his face and generally displaying the wacky talent that brought him fame in the first place. Sentiment: positive
Text: despite all evidence to the contrary, this clunker has somehow managed to pose as an actual feature movie, the kind that charges full admission and gets hyped on tv and purports to amuse small children and ostensible adults. Sentiment: negative
Text: for the first time in years, de niro digs deep emotionally, perhaps because he's been stirred by the powerful work of his co-stars. Sentiment: positive
Text: i'll bet the video game is a lot more fun than the film. Sentiment:
Among them, Instruct is the interface method of ChatGPT, which means that people give descriptions of tasks in natural language, such as
Translate this sentence from Chinese to English: ....
“Zero-shot prompting” used to be called “zero-shot” in the past, but now it’s commonly referred to as “Instruct.” The two terms have the same meaning but there are two different methods involved.
When interacting with instruction models, we should describe the task requirement in detail, trying to be specific and precise and avoiding saying “not do something” but rather specify what to do.
Please label the sentiment towards the movie of the given movie review. The sentiment label should be "positive" or "negative". Text: i'll bet the video game is a lot more fun than the film. Sentiment:
Explaining the desired audience is another smart way to give instructions. For example to produce educational materials for kids, and safe content,
Describe what is quantum physics to a 6-year-old.
.. in language that is safe for work.
In-context instruction learning (Ye et al. 2023) combines few-shot learning with instruction prompting. It incorporates multiple demonstration examples across different tasks in the prompt, each demonstration consisting of instruction, task input, and output. Note that their experiments were only on classification tasks and the instruction prompt contains all label options.
Definition: Determine the speaker of the dialogue, "agent" or "customer". Input: I have successfully booked your tickets. Ouput: agent
Definition: Determine which category the question asks for, "Quantity" or "Location". Input: What's the oldest building in US? Ouput: Location
Definition: Classify the sentiment of the given movie review, "positive" or "negative". Input: i'll bet the video game is a lot more fun than the film. Output:
In the early days, people would attempt to express a task by using different words or sentences, continually refining their approach. This method was effective for fitting the training data, without considering the distribution. The current approach is to give a specific command statement and aim for the language model to understand it. Both methods involve expressing tasks, but the underlying ideas behind them are distinct.
In Context Learning and few-shot prompting have a similar meaning. They both involve providing examples to a language model and using them to solve new problems.
In my opinion, In Context Learning can be seen as a specific task, while Instruct is a more abstract method of describing tasks. However, the usage of these terms can be confusing, and this understanding is just my personal opinion. Therefore, I will only discuss In Context Learning and Instruct here, and no longer mention zero-shot and few-shot anymore.
The Mysterious In-Context Learning
If you think about it carefully, you will find that In Context Learning is a very magical technology. What’s so magical about it?
The magic is that when you provide LLM with several sample examples {<x1,y1>, <x2, y2>, …, <xn, yn> }, and then give {<x_n+1>} to it, LLM can successfully predict the corresponding ones {<y_n+1>}.
When you hear this, you might ask: What’s so magical about this? Isn’t that how fine-tuning works? If you ask this, it means you haven’t thought deeply enough about this issue.
Fine-tuning and In Context Learning both seem to provide some examples to LLM, but they are qualitatively different (refer to the figure above): Fine-tuning uses these examples as training data and uses backpropagation to modify LLM. The model parameters and the action of modifying the model parameters reflect the process of LLM learning from these examples.
However, In Context Learning only took out examples for LLM to take a look at, and did not use backpropagation to modify the parameters of the LLM model based on the examples, and asked it to predict new examples. Since the model parameters have not been modified, this means that it seems that LLM has not gone through a learning process. If it has not gone through a learning process, then why can it predict new examples just by looking at it?
This is the magic of In Context Learning. Does this remind you of a lyric: “Just because I took one more look at you in the crowd, I can never forget your face again.” The song is called “Legend”. Are you saying it is legendary or not?
It seems that In Context Learning does not learn knowledge from examples. In fact, does LLM learn strangely? Or is it true that it didn’t learn anything? The answer to this question is still an unsolved mystery. Some existing studies have different versions, and it is difficult to judge which one tells the truth. Some research conclusions are even contradictory.
Here are some current opinions. As for who is right and who is wrong, you can only decide for yourself. Of course, I think pursuing the truth behind this magical phenomenon is a good research topic.
It was discovered that in the sample examples {<xi, yi>} provided to LLM, it does not actually matter whether the corresponding correct answer is yi. If we replace the correct answer with another random answer, this does not affect the effect of In Context Learning.
What really has a greater impact on In Context Learning is the distribution of x and y, that is, the distribution of the input text x and the candidate answers y. If you change these two distributions, for example, replace y with something other than the candidate answer. , then the In Context Learning effect drops sharply.
In short, this work proves that In Context Learning does not learn the mapping function, but the distribution of input and output is very important, and these two cannot be changed randomly.
Magical Instruct understanding
We can regard “Instruct” as a task description that is convenient for human beings to understand. Under this premise, the current research on “Instruct” can be divided into two types: “Instruct” which is more academic research, and “Instruct” which describes human real needs.
Let’s look at the first type “Instruct” which is more academically research-oriented. Its core research theme is the generalization ability of the LLM model to understand “Instruct” in multi-task scenarios.
As shown in the FLAN model in the figure above, that is to say, there are many NLP tasks. For each task, the researchers construct one or more Prompt templates as the Instruct of the task and then use training examples to fine-tune the LLM model so that LLM can learn multiple tasks at the same time. task.
After training the model, give the LLM model instruction for a brand-new task that it has never seen before, and then let LLM solve the zero-shot task. Based on whether the task is solved well enough, we can judge whether the LLM model has the generalization ability to understand the Instruct.
Research findings suggest several factors that can significantly enhance the generalization capabilities of the Language Models Instruction (LLM). To augment the model’s instructional comprehension, the following strategies have proven effective: increasing the number of multi-tasking tasks, expanding the size of the LLM model, implementing CoT Prompting, and diversifying the range of tasks. By incorporating these measures, the LLM model can substantially improve its capacity to understand instructions.
Type 2: Human/Customer Needs Orented Instruct
The second type is instruction based on real human needs. This type of research is represented by InstructGPT and ChatGPT. This type of work is also based on multi-tasking, but the biggest difference from academic research-oriented work is that it is oriented to the real needs of human users.
Why do you say that? Because the task description prompts they use for LLM multi-task training are sampled from real requests submitted by a large number of users, instead of fixing the scope of the research task and then letting researchers write the task description prompts.
The so-called “real needs” here are reflected in two aspects: first, because they are randomly selected from the task descriptions submitted by users, the types of tasks covered are more diverse and more in line with the real needs of users; second, a certain prompt description of a task is submitted by the user and reflects what ordinary users would say when expressing task requirements, not what you think users would say. Obviously, the user experience of the LLM model modified by this type of work will be better.
In the InstructGPT paper, this method is also compared with the Instruct-based method of FLAN. First, fine-tune the tasks, data, and Prompt template mentioned by FLAN on GPT3 to reproduce the FLAN method on GPT3, and then compare it with InstructGPT. Because the basic model of InstructGPT is also GPT3, there are only differences in data and methods. The two are comparable, and it is found that the effect of the FLAN method is far behind InstructGPT.
So what’s the reason behind it? After analyzing the data, the paper believes that the FLAN method involves relatively few task fields and is a subset of the fields involved in InstructGPT, so the effect is not good. In other words, the tasks involved in the FLAN paper are inconsistent with the actual needs of users, which results in insufficient results in real scenarios. This means that itis very important to collect real needs from user data.
In Context Learning & Instruct Connection
If we assume that In Context Learning uses some examples to concretely express task commands, Instruct is an abstract task description that is more in line with human habits.
So, a natural question is: is there any connection between them? For example, can we provide LLM with several specific examples of completing a certain task and let LLM find the corresponding Instruct command described in natural language? (aka, Can LLM create the instruct command for itself by watching the human involved process)
There’s actually some work being done on this issue here and there, and I think it’s a really interesting research direction.
Let’s talk about the answer first. The answer is: Yes, LLM can.
As shown in the figure above, for a certain task, give LLM some examples, let LLM automatically generate natural language commands that can describe the task, and then it use the task description generated by LLM to test the task’s effectiveness.
The basic models it uses are GPT 3 and InstructGPT. After the blessing of this technology, the effect of Instruct generated by LLM is greatly improved compared to GPT 3 and InstructGPT which do not use this technology, and in some tasks Superhuman performance.
This shows that there is a mysterious inner connection between concrete task examples and natural language descriptions of tasks. As for what exactly this connection is? We don’t know anything solid conclusions about this yet.
What’s Next?
Technical Review 05: How to Enhance LLM’s Reasoning Ability
This blog discusses the scale of Large Language Models (LLMs) and their impact on performance. LLMs like GPT, LaMDA, and PaLM have billions of parameters, raising questions about the consequences of their continued growth.
The journey of an LLM involves two stages: pre-training and scenario application. Pre-training focuses on optimizing the model using cross-entropy, while scenario application evaluates the model’s performance in specific use cases. Evaluating an LLM’s quality requires considering both stages, rather than relying solely on pre-training indicators.
Increasing training data, model parameters, and training time has been found to enhance performance in the pre-training stage. OpenAI and DeepMind have explored this issue, with OpenAI finding that a combination of more data and parameters, along with fewer training steps, produces the best results. DeepMind considers the amount of training data and model parameters equally important.
The influence of model size on downstream tasks varies. Linear tasks show consistent improvement as the model scales, while breakthrough tasks only benefit from larger models once they reach a critical scale. Tasks involving logical reasoning demonstrate sudden improvement at specific model scales. Some tasks exhibit U-shaped growth, where performance initially declines but then improves with larger models.
Reducing the LLM’s parameters while increasing training data proportionally can decrease the model’s size without sacrificing performance, leading to faster inference speed.
Understanding the impact of model size on both pre-training and downstream tasks is vital for optimizing LLM performance and exploring the potential of these language models.
Introduction
In recent years, we’ve witnessed a surge in the size of Large Language Models (LLMs), with models now boasting over 100 billion parameters becoming the new standard. Think OpenAI’s GPT-3 (175B), Google’s LaMDA (137B), PaLM (540B), and other global heavyweights. China, too, contributes to this landscape with models like Zhiyuan GLM, Huawei’s “Pangu,” Baidu’s “Wenxin,” etc. But here’s the big question: What unfolds as these LLMs continue to grow?
The journey of pre-trained models involves two crucial stages: pre-training and scenario application.
In the pre-training stage, the optimization goal is cross entropy. For autoregressive language models such as GPT, it is to see whether LLM correctly predicts the next word;
However, the real test comes in the scenario application stage, where specific use cases dictate evaluation criteria. Generally, our intuition is that if the LLM has better indicators in the pre-training stage, its ability to solve downstream tasks will naturally be stronger. However, this is not entirely true.
Existing research has proven that the optimization index in the pre-training stage does show a positive correlation with downstream tasks, but it is not completely positive. In other words, it is not enough to only look at the indicators in the pre-training stage to judge whether an LLM model is good enough. Based on this, we will look separately at these two different stages to see what the impact will be as the LLM model increases.
Part One: pre-training phase
First, let’s look at what happens as the model size gradually increases during the pre-training stage. OpenAI specifically studied this issue in “Scaling Laws for Neural Language Models” and proposed the “scaling law” followed by the LLM model.
As shown in the figure above, this study proves that when we independently increase (1) the amount of training data, (2) model parameter size and (3) extend the model training time (such as from 1 Epoch to 2 Epochs), the Loss of the pre-trained model on the test set will decrease monotonically. In other words, the model’s effectiveness is improving steadily.
Since all three factors are important when we actually do pre-training, we have a decision-making problem on how to allocate computing power:
Question: Assuming that the total computing power budget used to train LLM (such as fixed GPU hours or GPU days) is given. How to allocate computing power?
Should we increase the amount of data and reduce model parameters?
Or should we increase the amount of data and model size at the same time but reduce the number of training steps?
Open AI
As one zero-sum game, the scale of one-factor increases, and the scale of other factors must be reduced to keep the total computing power unchanged, so there are various possible computing power allocation plans.
In the end, OpenAI chose to increase the amount of training data and model parameters at the same time but used an early stopping strategy to reduce the number of training steps. Because it proves that: for the two elements of training data volume and model parameters, if you only increase one of them separately, this is not the best choice. It is better to increase both at the same time according to a certain proportion. Its conclusion is to give priority to increasing the model parameters, and then the amount of training data.
Assuming that the total computing power budget used to train LLM increases by 10 times, then the amount of model parameters should be increased by 5.5 times and the amount of training data should be increased by 1.8 times. At this time, the model gets the best performance.
Its basic conclusions are similar to those of OpenAI. For example, it is indeed necessary to increase the amount of training data and model parameters at the same time, so that the model effect will be better.
Many large models do not consider this when doing pre-training. Many large LLM models were trained just monotonically increasing the model parameters while fixing the amount of training data. This approach is wrong and limits the potential of the LLM model.
However, DeepMind corrects the proportional relationship between the two by OpenAI and believes that the amount of training data and model parameters are equally important.
In other words, assuming that the total computing power budget used to train LLM increases by 10 times, the number of model parameters should be increased by 3.3 times, and the amount of training data should also be increased by 3.3 times to get the best model.
This means that increasing the amount of training data is more important than we previously thought. Based on this understanding, DeepMind chose another configuration in terms of computing power allocation when designing the Chinchilla model: compared with the Gopher model with a data volume of 300B and a model parameter volume of 280B, Chinchilla chose to increase the training data by 4 times, but reduced the model The parameters are reduced to one-fourth that of Gopher, which is about 70B. However, regardless of pre-training indicators or many downstream task indicators, Chinchilla is better than the larger Gopher.
This brings us to the following enlightenment:
We can choose to enlarge the training data and reduce the LLM model parameters in the same proportion to achieve the purpose of greatly reducing the size of the model without reducing the model performance.
Reducing the size of the model has many benefits, such as the inference speed will be much faster when applied. This is undoubtedly a promising development route for LLM.
Part Two: downstream tasks
The above is the impact of the model scale from the pre-training stage. From the perspective of the effect of LLM on solving specific downstream tasks, as the model scale increases, different types of tasks have different performances.
Specifically, there are the following three types of tasks.
(a) Tasks that achieve the highest linearity scores see model performance improve predictably with scale and typically rely on knowledge and simple textual manipulations.
(b) Tasks with high breakthroughs do not see model performance improve until the model reaches a critical scale. These tasks generally require sequential steps or logical reasoning. Around 5% of BIG-bench tasks see models achieve sudden score breakthroughs with increasing scale.
(c) Tasks that achieve the lowest (negative) linearity scores see model performance degrade with scale.
Linearity Tasks
The first type of task perfectly reflects the scaling law of the LLM model, which means that as the model scale gradually increases, the performance of the tasks gets better and better, as shown in (a) above.
Such tasks usually have the following common characteristics: they are often knowledge-intensive tasks. That is to say, if the LLM model contains more knowledge, the performance of such tasks will be better.
Many studies have proven that the larger the LLM model, the higher the learning efficiency. For the same amount of training data, the larger the model, the better the performance. This shows that even when faced with the same batch of training data, a larger LLM model is relatively more efficient in getting more knowledge than small ones.
What’s more, under normal circumstances, when increasing the LLM model parameters, the amount of training data will often increase simultaneously, which means that large models can learn more knowledge points from more data. These studies can explain the above figure, why as the model size increases, these knowledge-intensive tasks become better and better.
Most traditional NLP tasks are actually knowledge-intensive tasks, and many tasks have achieved great improvement in the past few years, even surpassing human performance. Obviously, this is most likely caused by the increase in the scale of the LLM model, rather than due to a specific technical improvement.
Breakthroughs Tasks
The second type of task demonstrates that LLM has some kind of “Emergent Ability”, as shown in (b) above. The so-called “emergent ability” means that when the model parameter scale fails to reach a certain threshold, the model basically does not have any ability to solve such tasks, which reflects that its performance is equivalent to randomly selecting answers. However, when the model scale spans Once the threshold is exceeded, the LLM model’s effect on such tasks will experience a sudden performance increase.
In other words, model size is the key to unlocking (unlocking) new capabilities of LLM. As the model size becomes larger and larger, more and more new capabilities of LLM will be gradually unlocked.
This is a very magical phenomenon because it means the following possibilities that make people optimistic about the future. Many tasks that cannot be solved well by LLM at present can be solved in future if we continue to make the model larger. Because LLM has “emergent capabilities” to suddenly unlock those limits one day. The growth of the LLM model will bring us unexpected and wonderful gifts.
The article “Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models” points out that tasks that embody “emergent capabilities” also have some common features: these tasks generally consist of multiple steps, and to solve these tasks, it is often necessary to first Multiple intermediate steps are solved, and logical reasoning skills play an important role in the final solution of such tasks.
Chain of Thought (CoT) Prompting is a typical technology that enhances the reasoning ability of LLM, which can greatly improve the effect of such tasks. I will discuss the CoT technology in the following blogs.
Here the most important question is, why does LLM have this “emergent ability” phenomenon? The article “Emergent Abilities of Large Language Models” shares several possible explanations:
One possible explanation is that the evaluation indicators of some tasks are not smooth enough. For example, some metrics for generation tasks require that the string output by the model must completely match the standard answer to be considered correct otherwise it will be scored zero.
Thus, even as the model gradually becomes better and outputs more correct character fragments, because it is not completely correct, 0 points will be given for any small errors. Only when the model is large enough, the output Scores are scored when all the output segments are correct. In other words, because the indicator is not smooth enough, it cannot reflect the reality that LLM is actually gradually improving its performance on the task. It seems to be an external manifestation of “emergent ability”.
Another possible explanation is that some tasks are composed of several intermediate steps. As the size of the model increases, the ability to solve each step gradually increases, but as long as one intermediate step is wrong, the final answer will be wrong. This will also lead to this superficial “emergent ability” phenomenon.
Of course, the above explanations are still conjectures at present. As for why LLM has this phenomenon, further and in-depth research is needed.
There are also a small number of tasks. As the model size increases, the task effect curve shows U-shaped characteristics: as the model size gradually increases, the task effect gradually becomes worse, but when the model size further increases, the effect starts to get better and better. Figure above shows a U-shaped growth trend where the indicator trend of the pink PaLM model on the two tasks.
Why do these tasks appear so special? The article “Inverse Scaling Can Become U-shaped” gives an explanation:
These tasks actually contain two different types of subtasks, one is the real task, and the other is the “interference task ( distractor task)”.
When the model size is small, it cannot identify any sub-task, so the performance of the model is similar to randomly selecting answers.
When the model grows to a medium size, it mainly tries to solve the interference task, so it has a negative impact on the real task performance. This is reflected in the decline of the real task effect.
When the model size is further increased, LLM can ignore the interfering task and perform the real task, which is reflected in the effect starting to grow.
For those tasks whose performance has been declining as the model size increases, if Chain of Thought (CoT) Prompting is used, the performance of some tasks will be converted to follow the Scaling Law. That is, the larger the model size, the better the performance, while other tasks will be converted to a U-shaped growth curve.
This actually shows that this type of task should be a reasoning-type task, so the task performance will change qualitatively after adding CoT.
Personal View
Increasing the size of the LLM model may not seem technically significant, but it is actually very important to build better LLMs. In my opinion, the advancements from Bert to GPT 3 and ChatGPT are likely attributed to the growth of the LLM model size rather than a specific technology. I believe a lot of people want to explore the scale ceiling of the LLM model if possible.
The key to achieving AGI may lie in having large and diverse data, large-scale models, and rigorous training processes. Developing such large LLM models requires high engineering skills from the technical team, which means there is technical content involved.
Increasing the scale of the LLM model has research significance. There are two main reasons why it is valuable.
Firstly, as the model size grows, the performance of various tasks improves, especially for knowledge-intensive tasks. Additionally, for reasoning and difficult tasks, the effect of adding CoT Prompting follows a scaling law. Therefore, it is important to determine to what extent the scale effect of LLM can solve these tasks.
Secondly, the “emergent ability” of LLM suggests that increasing the model size may unlock new capabilities that we did not expect. This raises the question of what these capabilities could be.
Considering these factors, it is necessary to continue increasing the model size to explore the limits of its ability to solve different tasks.
Talk is cheap, and in reality, very few AI/ML practitioners have the opportunity or ability to build larger models due to high financial requirements, investment willingness, engineering capabilities, and technical enthusiasm from research institutions. There are probably no more than 10 institutions that can do this on Earth. However, in the future, there may be a possibility of joint efforts between capable institutions to build a Super-Large model:
All (Resources) for One (Model) and One (Model) for All (People).
Modified from Alexandre Dumas, The Three Musketeers
BIG-bench Project Team: 2023: Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models (https://arxiv.org/abs/2206.04615)
This blog explores the depth of knowledge acquired by Large Language Models (LLMs), such as the Transformer. The knowledge obtained can be categorized into linguistic knowledge and factual knowledge. Linguistic knowledge includes understanding language structure and rules, while factual knowledge encompasses real-world events and common-sense notions.
The blog explains that LLMs acquire linguistic knowledge at various levels, with more fundamental language elements residing in lower and mid-level structures, and abstract language knowledge distributed across mid-level and high-level structures. In terms of factual knowledge, LLMs absorb a significant amount of it, mainly in the mid and high levels of the Transformer model.
The blog also addresses how LLMs store and retrieve knowledge. It suggests that the feedforward neural network (FFN) layers in the Transformer serve as a Key-Value memory system, housing specific knowledge. The FFN layers detect knowledge patterns through the Key layer and retrieve corresponding values from the Value layer to generate output.
Furthermore, the blog discusses the feasibility of correcting erroneous or outdated knowledge within LLMs. It introduces three methods for modifying knowledge in LLMs:
Correcting knowledge at the source by identifying and adjusting training data;
Fine-tuning the model with new training data containing desired corrections;
Directly Modifying model parameters associated with specific knowledge.
These methods aim to enhance the reliability and relevance of LLMs in providing up-to-date and accurate information. The blog emphasizes the importance of adapting and correcting knowledge in LLMs to keep pace with evolving information in real-world scenarios.
In conclusion, this blog sheds light on the depth of knowledge acquired by LLMs, how it is stored and retrieved, and strategies for correcting and adapting knowledge within these models. Understanding these aspects contributes to harnessing the full potential of LLMs in various applications.
Introduction
Judging from the current Large Language Model (LLM) research results, the Transformer is a sufficiently powerful feature extractor and does not require special improvements.
So what did Transformer learn through the pre-training process?
How is knowledge accessed?
How do we correct incorrect knowledge?
This blog discusses the research progress in this area.
Unveiling the Depth of LLM Knowledge
Large Language Models (LLM) acquire a wealth of knowledge from extensive collections of free text. This knowledge can be broadly categorized into two realms: linguistic knowledge and Factual knowledge.
Linguistic Knowledge
This encompasses understanding the structure and rules of language, including morphology, parts of speech, syntax, and semantics. Extensive research has affirmed the capacity of LLM to grasp various levels of linguistic knowledge.
Since the emergence of models like Bert, numerous experiments have validated this capability. The acquisition of such linguistic knowledge is pivotal, as it substantially enhances LLM’s performance in various natural language understanding tasks following pre-training.
Additionally, investigations have shown that more fundamental language elements like morphology, parts of speech, and syntax reside in the lower and mid-level structures of the Transformer, while abstract language knowledge, such as semantics, is distributed across the mid-level and high-level structures.
Factual Knowledge
This category encompasses both factual knowledge, relating to real-world events, and common-sense knowledge.
Examples include facts like “Biden is the current President of the United States” and common-sense notions like “People have two eyes.”
Numerous studies have explored the extent to which LLM models can absorb world knowledge, and the consensus suggests that they indeed acquire a substantial amount of it from their training data.
This knowledge tends to be concentrated primarily in the mid and high levels of the Transformer model. Notably, as the depth of the Transformer model increases, its capacity to learn and retain knowledge expands exponentially. LLM can be likened to an implicit knowledge graph stored within its model parameters.
The conclusion drawn is that for Bert-type language models, a corpus containing 10 million to 100 million words suffices to learn linguistic knowledge, including syntax and semantics. However, to grasp factual knowledge, a more substantial volume of training data is required.
This is logical, given that linguistic knowledge is relatively finite and static, while factual knowledge is vast and constantly evolving. Current research demonstrates that as the amount of training data increases, the pre-trained model exhibits enhanced performance across a range of downstream tasks, emphasizing that the incremental data mainly contributes to the acquisition of world knowledge.
The Repository of Knowledge: How LLM Stores and Retrieves Information
As discussed earlier, Large Language Models (LLM) accumulate an extensive reservoir of language and world knowledge from their training data. But where exactly is this knowledge stored within the model, and how does LLM access it? These are intriguing questions worth exploring.
Evidently, this knowledge is stored within the model parameters of the Transformer architecture. The model parameters can be divided into two primary components: the multi-head attention (MHA) segment, which constitutes roughly one-third of the total parameters, and the remaining two-thirds of the parameters are concentrated in the feedforward neural network (FFN) structure.
The MHA component primarily serves to gauge the relationships and connections between words or pieces of knowledge, facilitating the integration of global information. It’s more geared toward establishing contextual connections rather than storing specific knowledge points. Therefore, it’s reasonable to infer that the substantial knowledge base of the LLM model is primarily housed within the FFN structure of the Transformer.
However, the granularity of such positioning is still too coarse, and it is difficult to answer how a specific piece of knowledge is stored and retrieved.
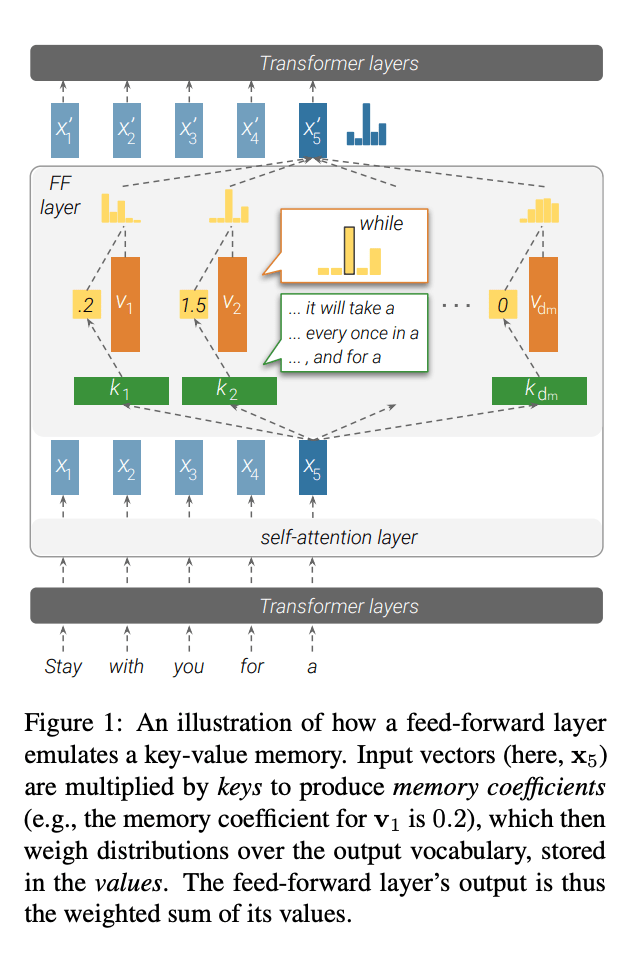
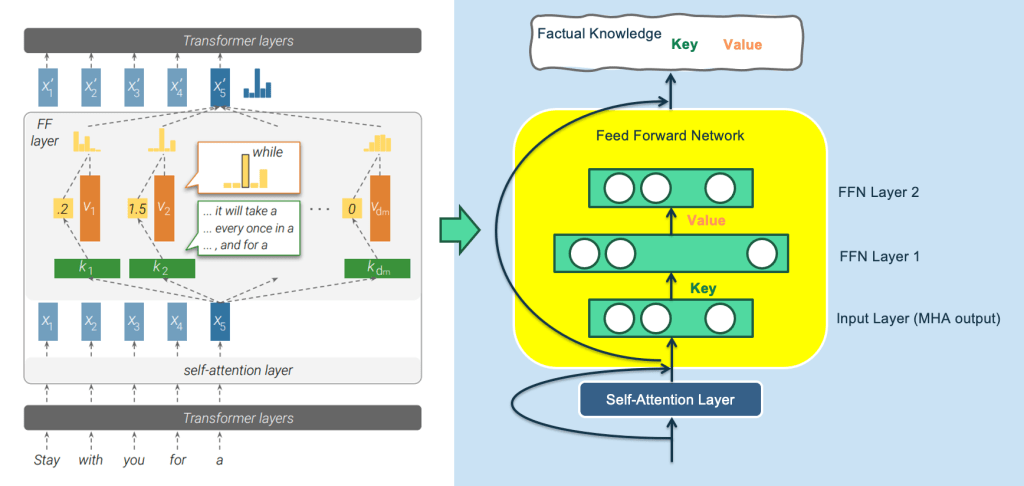
A relatively novel perspective, introduced in the article “Transformer Feed-Forward Layers Are Key-Value Memories,” suggests that the feedforward neural network (FFN) layers in the Transformer architecture function as a Key-Value memory system storing a wealth of specific knowledge. The figure below illustrates this concept, with annotations on the right side for improved clarity (since the original paper’s figure on the left side can be somewhat challenging to grasp).
In this Key-Value memory framework, the first layer of the FFN serves as the Key layer, characterized by a wide hidden layer, while the second layer combines a narrow hidden layer with the Value layer. The input to the FFN layer corresponds to the output embedding generated by the Multi-Head Attention (MHA) mechanism for a specific word, encapsulating the comprehensive context information drawn from the entire input sentence via self-attention.
Each neuron node in the Key layer stores a pair of information. For instance, the node in the first hidden layer of the FFN may record the knowledge.
The Key vector associated with a node essentially acts as a pattern detector, aiming to identify specific language or knowledge patterns within the input. If a relevant pattern is detected, the input vector and the key node’s weight are computed via the vector inner product, followed by the application of the Rectified Linear Unit (ReLU) activation function, signalling that the pattern has been detected. The resulting response value is then propagated to the second FFN layer through the Value weights of the node.
In essence, the FFN’s forward propagation process resembles the detection of a specific knowledge pattern using the Key, retrieving the corresponding Value, and incorporating it into the second FFN layer’s output. As each node in the second FFN layer aggregates information from all nodes in the Key layer, it generates a mixed response, with the collective response across all nodes in the Value layer serving as probability distribution information for the output word.
It may still sound complicated, so let’s use an extreme example to illustrate. We assume that the node in the above figure is the Key-Value memory that records the knowledge. Its Key vector is used to detect the knowledge pattern “The capital of China is…” and its Value. The vector basically stores a vector that is close to the Embedding of the word “Beijing”. When the input of the Transformer is “The capital of China is [Mask]”, the node detects this knowledge pattern from the input layer, so it generates a larger response output. We assume that other neurons in the Key layer have no response to this input, then the corresponding node in the Value layer will actually only receive the word embedding corresponding to the Value “Beijing”, and pass the large response value to perform further numerical calculations. enlarge. Therefore, the output corresponding to the Mask position will naturally output the word “Beijing”. It’s basically this process. It looks complicated, but it’s actually very simple.
Moreover, this article also pointed out that the low-level Transformer responds to the surface pattern of sentences, and the high-level responds to the semantic pattern. That is to say, the low-level FFN stores surface knowledge such as lexicon and syntax, and the middle and high-level layers store semantic and factual concept knowledge. This is consistent with other research The conclusion is consistent.
I would guess that the idea of treating FFN as a Key-Value memory is probably not the final correct answer, but it is probably not too far from the final correct answer.
Knowledge Correction in LLM: Adapting to Evolving Information
As we’ve established that specific pieces of factual knowledge reside in the parameters of one or more feedforward neural network (FFN) nodes within the Large Language Models (LLM), it’s only natural to ponder the feasibility of correcting erroneous or outdated knowledge stored within these models.
Let’s consider an example to illustrate this point. If you were to ask, “Who is the current Prime Minister of the United Kingdom?” in a dynamic political landscape where British Prime Ministers frequently change, would LLM tend to produce “Boris” or “Sunak” as the answer?
In such a scenario, the model is likely to encounter a higher volume of training data containing “Boris.” Consequently, there’s a considerable risk that LLM could provide an incorrect response. Therefore, there arises a compelling need to address the issue of correcting outdated or erroneous knowledge stored within the LLM.
By exploring strategies to rectify knowledge within LLM and adapting it to reflect real-time developments and evolving information, we take a step closer to harnessing the full potential of these models in providing up-to-date and accurate answers to questions that involve constantly changing facts or details. This endeavour forms an integral part of enhancing the reliability and relevance of LLM in practical applications.
Methods for Modifying Knowledge in LLM
Currently, there are three distinctive approaches for modifying knowledge within Large Language Models (LLMs):
Correcting Knowledge at the Source
This method aims to rectify knowledge errors by identifying the specific training data responsible for the erroneous knowledge in the LLM. With advancements in research, it’s possible to trace back the source data that led the LLM to learn a particular piece of knowledge. In practical terms, this means we can identify the training data associated with a specific knowledge item, allowing us to potentially delete or amend the relevant data source. However, this approach has limitations, particularly when dealing with minor knowledge corrections. The need for retraining the entire model to implement even small adjustments can be prohibitively costly. Therefore, this method is better suited for large-scale data removal, such as addressing bias or eliminating toxic content.
Fine-Tuning to Correct Knowledge
This approach involves constructing new training data containing the desired knowledge corrections. The LLM model is then fine-tuned on this data, guiding it to remember new knowledge and forget old knowledge.
While straightforward, it presents challenges, such as the issue of “catastrophic forgetting,” where fine-tuning leads the model to forget not only the targeted knowledge but also other essential knowledge. Given the large size of current LLMs, frequent fine-tuning can be computationally expensive.
Directly Modifying Model Parameters
In this method, knowledge correction is achieved by directly altering the LLM’s model parameters associated with specific knowledge. For instance, if we wish to update the knowledge from “<UK, current Prime Minister, Boris>” to “<UK, current Prime Minister, Sunak>”, we locate the FFN node storing the old knowledge within the LLM parameters.
Subsequently, we forcibly adjust and replace the relevant model parameters within the FFN to reflect the new knowledge. This approach involves two key components: the ability to pinpoint the storage location of knowledge within the LLM parameter space and the capacity to alter model parameters for knowledge correction. Deeper insight into this knowledge revision process contributes to a more profound understanding of LLMs’ internal mechanisms.
These methods provide a foundation for adapting and correcting the knowledge within LLMs, ensuring that these models can produce accurate and up-to-date information in response to ever-changing real-world scenarios.
What’s Next
The next blog is about the Technical Review 03: Scale Effect: What happens when LLM gets bigger and bigger