Recently, Y Combinator hosted Bob McGrew, the former Chief Research Officer at OpenAI and a veteran technologist from PayPal and Palantir. What surprised many was the line of questioning. Instead of asking him how to build the next GPT, founders kept pressing him on a very different topic: Palantir’s FDE model.
Bob admitted that over the past year, nearly every startup he’s advised has been obsessed with learning how this model works in practice.
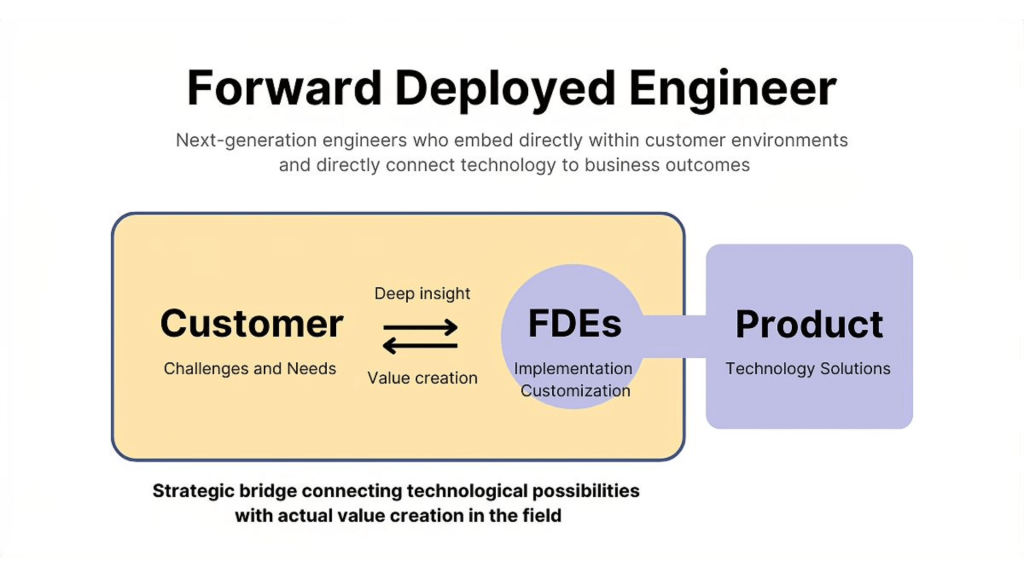
What Exactly Is FDE?
FDE (Forward Deployed Engineer) is a model where engineers embed directly with customers to bridge the gap between what the product aspires to be and what the customer actually needs.
The idea traces back to Palantir’s early days working with U.S. intelligence agencies. The challenges were messy, complex, and had no off-the-shelf solutions. The only way forward was to “build on the ground” with the client. At the time, many dismissed it as unscalable, labor-intensive, and far from the clean SaaS ideal. Fast forward to today, and the very same approach is being embraced by AI startups building agents and enterprise solutions.
How It Works
Palantir structured its FDE teams around two roles:
Echo: the industry-savvy operator who lives inside the customer’s workflow, identifies core pain points, and challenges the status quo.
Delta: the technical builder who can spin up prototypes quickly, solving problems in real time.
Meanwhile, the core product team back at HQ takes these frontline hacks and turns them into platform features. Think of it as paving a permanent road where the FDEs first laid down gravel.
Why It Matters
The strength of the FDE model is that it forges unusually deep relationships with customers. It surfaces real market demand—things no survey or user interview could ever uncover. Done right, it creates a defensible moat.
But it’s also risky. Without discipline, FDE can collapse into traditional consulting or body-shop outsourcing. The litmus test of a healthy model is whether the core platform keeps evolving, making each new deployment faster, cheaper, and more scalable.
Different from Consulting
The distinction is critical:
Consulting delivers one-off solutions.
FDE is about feeding learnings back into the product, so the platform gets stronger with every customer.
This feedback loop—and the ability of product managers to abstract from bespoke requests—is what turns customer-specific fixes into reusable product capabilities.
Why AI Startups Love It
For AI Agent companies, the market is far too fragmented and unpredictable for a “one-size-fits-all” solution. No universal product exists. Embedding deeply with customers isn’t optional—it’s the only way to figure out what works, discover product-market fit, and build enduring platforms.
A Shift in Business Models
Unlike traditional SaaS, which scales on pure subscriptions, FDE contracts are more outcome-driven and flexible. The key lever is product leverage: doing the same amount of frontline work but translating it into larger contracts and less marginal customization over time.
The Bigger Picture
The rise of FDE highlights a paradox of modern tech: at scale, the best companies keep doing the things that “don’t scale.” The gulf between breakthrough AI capabilities and messy, real-world adoption is exactly where the biggest opportunities lie today.
It’s not an easy path—more trench warfare than blitzscaling—but for founders, it may be the only one that works.
This blog examines the rapidly evolving landscape of AI-powered search, comparing Google’s recent transformation with its Search Generative Experience (SGE) and Gemini integration against Perplexity AI‘s native AI-first approach. Both companies now leverage large language models, but with fundamentally different architectures and philosophies.
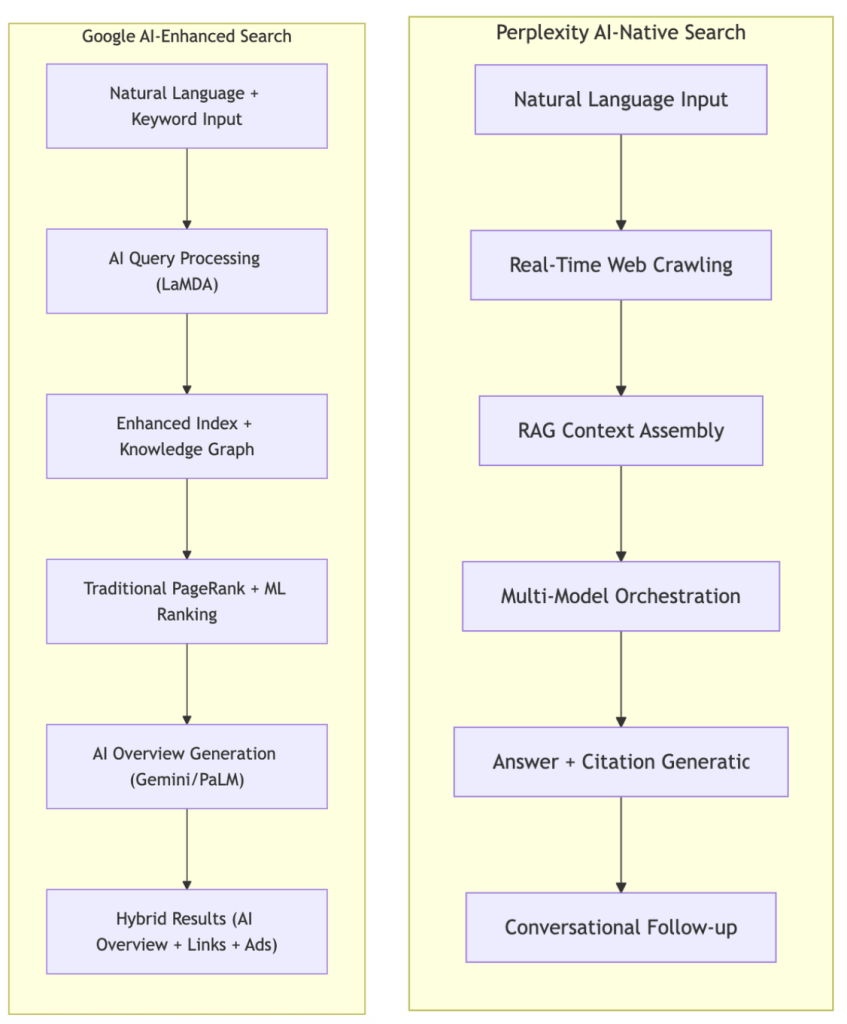
The New Reality: Google has undergone a dramatic transformation from traditional keyword-based search to an AI-driven conversational answer engine. With the integration of Gemini, LaMDA, PaLM, and the rollout of AI Overviews (formerly SGE), Google now synthesizes information from multiple sources into concise, contextual answers—directly competing with Perplexity’s approach.
Key Findings:
Convergent Evolution: Both platforms now use LLMs for answer generation, but Google maintains its traditional search infrastructure while Perplexity was built AI-first from the ground up
Architecture Philosophy: Google integrates AI capabilities into its existing search ecosystem (hybrid approach), while Perplexity centers everything around RAG and multi-model orchestration (AI-native approach)
AI Technology Stack: Google leverages Gemini (multimodal), LaMDA (conversational), and PaLM models, while Perplexity orchestrates external models (GPT, Claude, Gemini, Llama, DeepSeek)
User Experience: Google provides AI Overviews alongside traditional search results, while Perplexity delivers answer-first experiences with citations
Market Dynamics: The competition has intensified with Google’s AI transformation, making the choice between platforms more about implementation philosophy than fundamental capabilities
This represents a paradigm shift where the question is no longer “traditional vs. AI search” but rather “how to best implement AI-powered search” with different approaches to integration, user experience, and business models.
Keywords: AI Search, RAG, Large Language Models, Search Architecture, Perplexity AI, Google Search, Conversational AI, SGE, Gemini.
Google’s AI Transformation: From PageRank to Gemini-Powered Search
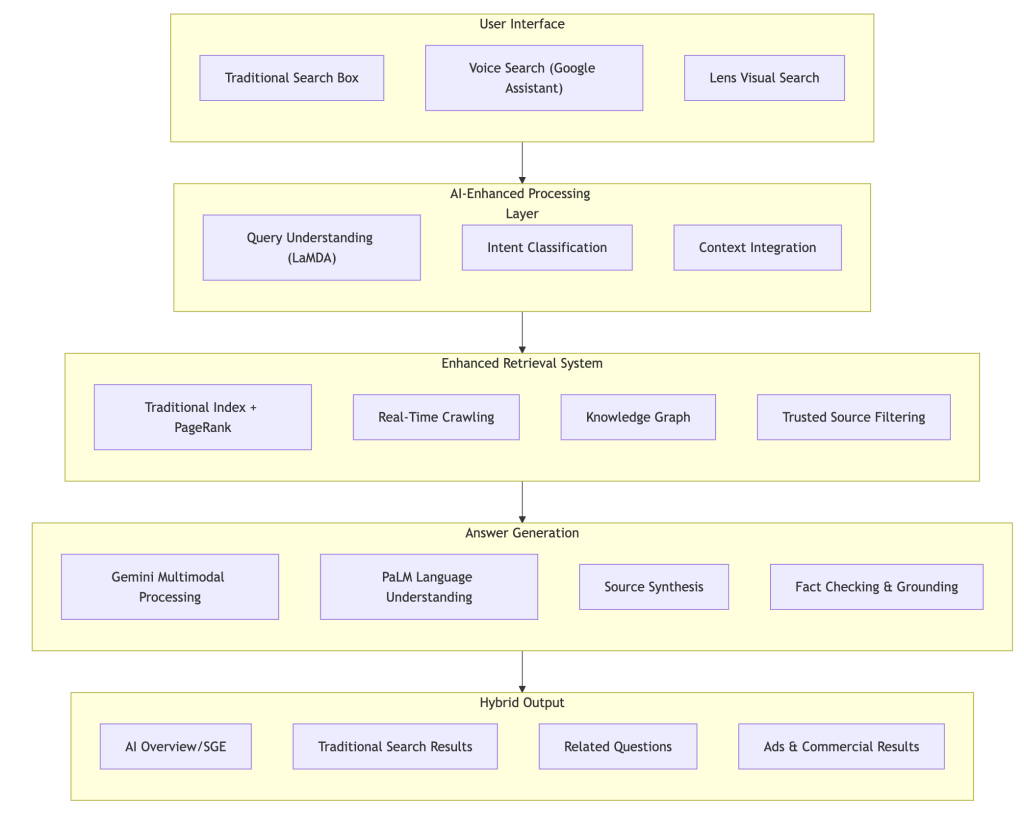
Google has undergone one of the most significant transformations in its history, evolving from a traditional link-based search engine to an AI-powered answer engine. This transformation represents a strategic response to the rise of AI-first search platforms and changing user expectations.
The Search Generative Experience (SGE) Revolution
Google’s Search Generative Experience (SGE), now known as AI Overviews, fundamentally changes how search results are presented:
AI-Synthesized Answers: Instead of just providing links, Google’s AI generates comprehensive insights, explanations, and summaries from multiple sources
Contextual Understanding: Responses consider user context including location, search history, and preferences for personalized results
Multi-Step Query Handling: The system can handle complex, conversational queries that require reasoning and synthesis
Real-Time Information Grounding: AI overviews are grounded in current, real-time information while maintaining accuracy
Google’s LLM Arsenal
Google has strategically integrated multiple advanced AI models into its search infrastructure:
Gemini: The Multimodal Powerhouse
Capabilities: Understands and generates text, images, videos, and audio
Search Integration: Enables complex query handling including visual search, reasoning tasks, and detailed information synthesis
Multimodal Processing: Handles queries that combine text, images, and other media types
LaMDA: Conversational AI Foundation
Purpose: Powers natural, dialogue-like interactions in search
Features: Enables follow-up questions and conversational context maintenance
Role: Provides advanced language processing capabilities
Applications: Powers complex reasoning, translation (100+ languages), and contextual understanding
Scale: Handles extended documents and multimodal inputs
Technical Architecture Integration
Google’s approach differs from AI-first platforms by layering AI capabilities onto existing infrastructure:
Key Differentiators of Google’s AI Search
Hybrid Architecture: Maintains traditional search capabilities while adding AI-powered features
Scale Integration: Leverages existing massive infrastructure and data
DeepMind Synergy: Strategic integration of DeepMind research into commercial search applications
Continuous Learning: ML ranking algorithms and AI models learn from user interactions in real-time
Global Reach: AI features deployed across 100+ languages with localized understanding
Perplexity AI Architecture: The RAG-Powered Search Revolution
Perplexity AI represents a fundamental reimagining of search technology, built on three core innovations:
Retrieval-Augmented Generation (RAG): Combines real-time web crawling with large language model capabilities
Multi-Model Orchestration: Leverages multiple AI models (GPT, Claude, Gemini, Llama, DeepSeek) for optimal responses
Integrated Citation System: Provides transparent source attribution with every answer
The platform offers multiple access points to serve different user needs: Web Interface, Mobile App, Comet Browser, and Enterprise API.
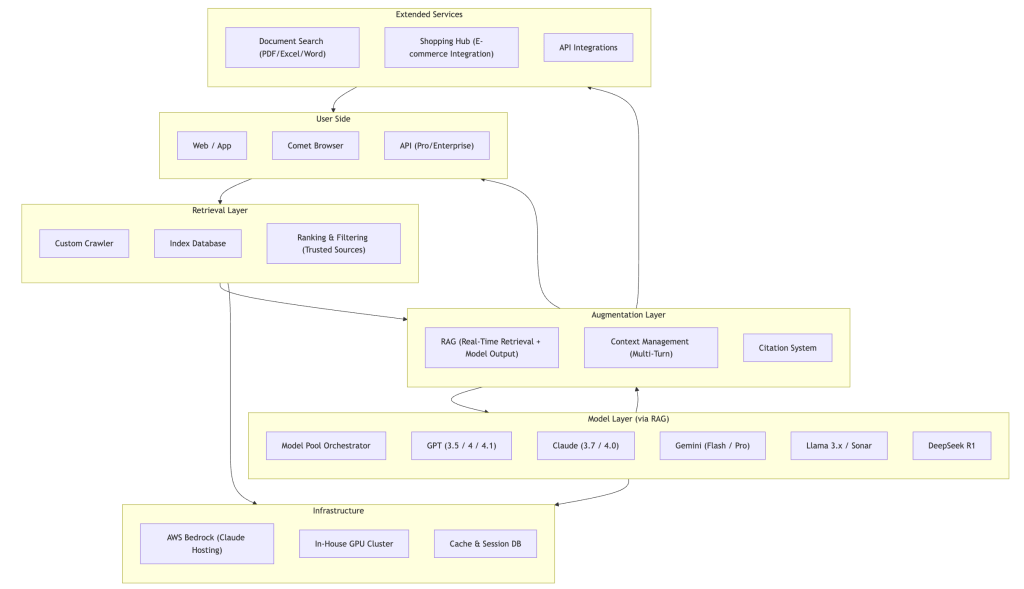
Core Architecture Components
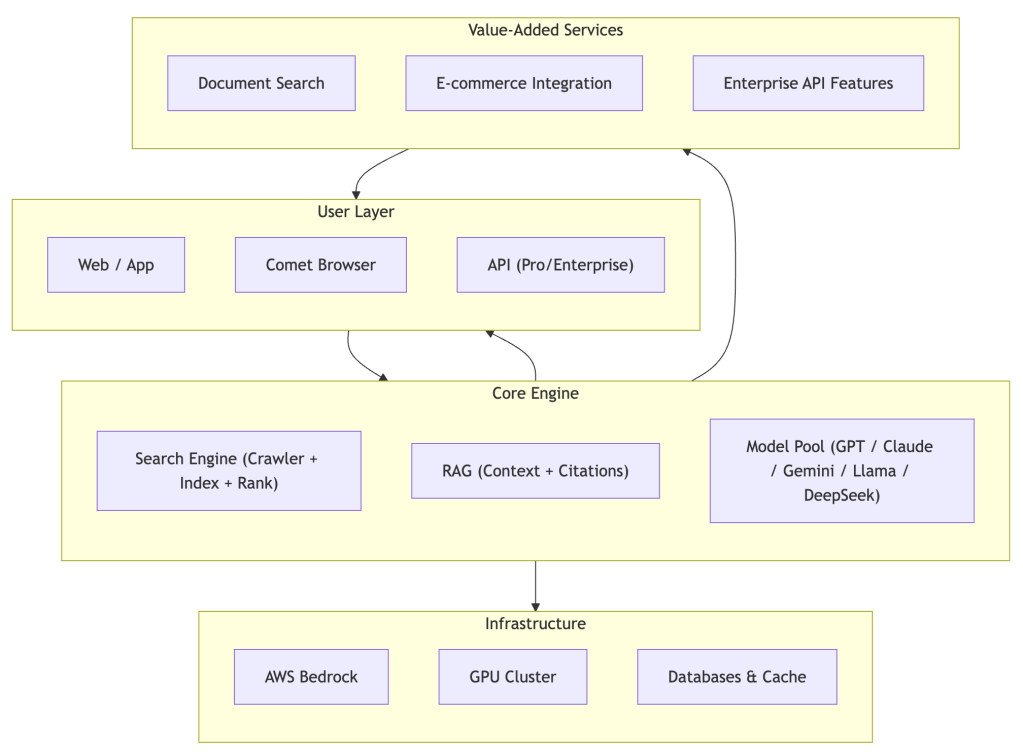
Simplified Architecture View
For executive presentations and high-level discussions, this three-layer view highlights the essential components:
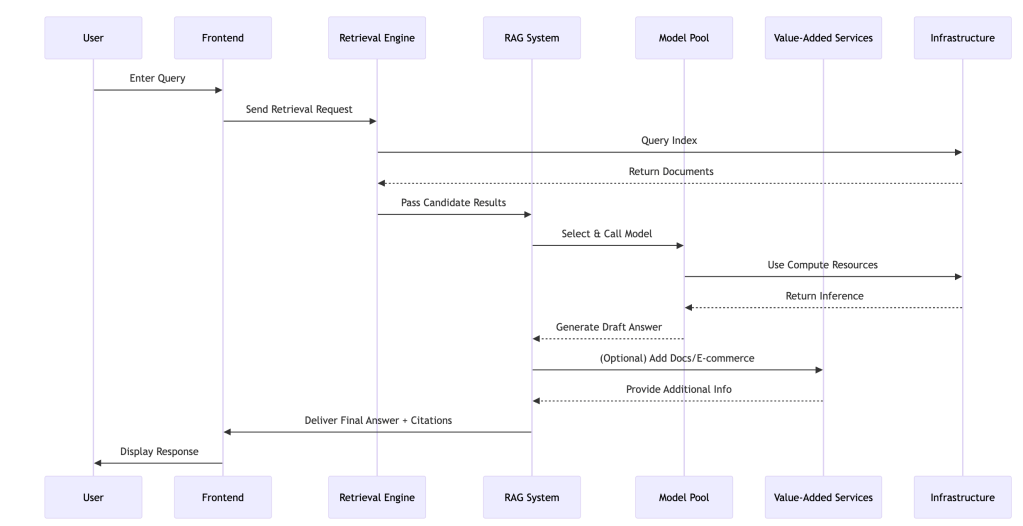
How Perplexity Works: From Query to Answer
Understanding Perplexity’s workflow reveals why it delivers fundamentally different results than traditional search engines. Unlike Google’s approach of matching keywords to indexed pages, Perplexity follows a sophisticated multi-step process:
The Eight-Step Journey
Query Reception: User submits a natural language question through any interface
Real-Time Retrieval: Custom crawlers search the web for current, relevant information
Source Indexing: Retrieved content is processed and indexed in real-time
Context Assembly: RAG system compiles relevant information into coherent context
Model Selection: AI orchestrator chooses the optimal model(s) for the specific query type
Answer Generation: Selected model(s) generate comprehensive responses using retrieved context
Citation Integration: System automatically adds proper source attribution
Response Delivery: Final answer with citations is presented to the user
Technical Workflow Diagram
The sequence below shows how a user query flows through Perplexity’s system.
This process typically completes in under 3 seconds, delivering both speed and accuracy.
The New Search Paradigm: AI-First vs AI-Enhanced Approaches
The competition between Google and Perplexity has evolved beyond traditional vs. AI search to represent two distinct philosophies for implementing AI-powered search experiences.
The Future of AI-Powered Search: A New Competitive Landscape
The integration of AI into search has fundamentally changed the competitive landscape. Rather than a battle between traditional and AI search, we now see different approaches to implementing AI-powered experiences competing for user mindshare and market position.
Implementation Strategy Battle: Integration vs. Innovation
Google’s Integration Strategy:
Advantage: Massive user base and infrastructure to deploy AI features at scale
Challenge: Balancing AI innovation with existing business model dependencies
Approach: Gradual rollout of AI features while maintaining traditional search options
Perplexity’s Innovation Strategy:
Advantage: Clean slate design optimized for AI-first experiences
Challenge: Building user base and competing with established platforms
Approach: Focus on superior AI experience to drive user acquisition
The Multi-Modal Future
Both platforms are moving toward comprehensive multi-modal experiences:
Visual Search Integration: Google Lens vs. Perplexity’s image understanding capabilities
Voice-First Interactions: Google Assistant integration vs. conversational AI interfaces
Video and Audio Processing: Gemini’s multimodal capabilities vs. orchestrated model approaches
Document Intelligence: Enterprise document search and analysis capabilities
Business Model Evolution Under AI
Advertising Model Transformation:
Google must adapt its ad-centric model to AI Overviews without disrupting user experience
Challenge of monetizing direct answers vs. traditional click-through advertising
Need for new ad formats that work with conversational AI
Subscription and API Models:
Perplexity’s success with subscription tiers validates alternative monetization
Growing enterprise demand for AI-powered search APIs and integrations
Despite different starting points, both platforms are converging on similar technical capabilities:
Real-Time Information: Both now emphasize current, up-to-date information retrieval
Source Attribution: Transparency and citation becoming standard expectations
Conversational Context: Multi-turn conversation support across platforms
Model Diversity: Google developing multiple specialized models, Perplexity orchestrating external models
The Browser and Distribution Channel Wars
Perplexity’s Chrome Acquisition Strategy:
$34.5B all-cash bid for Chrome represents unprecedented ambition in AI search competition
Strategic Value: Control over browser defaults, user data, and search distribution
Market Impact: Success would fundamentally alter competitive dynamics and user acquisition costs
Regulatory Reality: Bid likely serves as strategic positioning and leverage rather than realistic acquisition
Alternative Distribution Strategies:
AI-native browsers (Comet) as specialized entry points
API integrations into enterprise and developer workflows
Mobile-first experiences capturing younger user demographics
Strategic Implications and Future Outlook
The competition between Google’s AI-enhanced approach and Perplexity’s AI-native strategy represents a fascinating case study in how established platforms and startups approach technological transformation differently.
Key Strategic Insights
The AI Integration Challenge: Google’s transformation demonstrates that even dominant platforms must fundamentally reimagine their core products to stay competitive in the AI era
Architecture Philosophy Matters: The choice between hybrid integration (Google) vs. AI-first design (Perplexity) creates different strengths, limitations, and user experiences
Business Model Pressure: AI-powered search challenges traditional advertising models, forcing experimentation with subscriptions, APIs, and premium features
User Behavior Evolution: Both platforms are driving the shift from “search and browse” to “ask and receive” interactions, fundamentally changing how users access information
The New Competitive Dynamics
Advantages of Google’s AI-Enhanced Approach:
Massive scale and infrastructure for global AI deployment
Existing user base to gradually transition to AI features
Deep integration with knowledge graphs and proprietary data
Ability to maintain traditional search alongside AI innovations
Advantages of Perplexity’s AI-Native Approach:
Optimized user experience designed specifically for conversational AI
Agility to implement cutting-edge AI techniques without legacy constraints
Model-agnostic architecture leveraging best-in-class external AI models
Clear value proposition for users seeking direct, cited answers
Looking Ahead: Industry Predictions
Near-Term (1-2 years):
Continued convergence of features between platforms
Google’s global rollout of AI Overviews across all markets and languages
Perplexity’s expansion into enterprise and specialized vertical markets
Emergence of more AI-native search platforms following Perplexity’s model
Medium-Term (3-5 years):
AI-powered search becomes the standard expectation across all platforms
Specialized AI search tools for professional domains (legal, medical, scientific research)
Integration of real-time multimodal capabilities (live video analysis, augmented reality search)
New regulatory frameworks for AI-powered information systems
Long-Term (5+ years):
Fully conversational AI assistants replace traditional search interfaces
Personal AI agents that understand individual context and preferences
Integration with IoT and ambient computing for seamless information access
Potential emergence of decentralized, blockchain-based search alternatives
Recommendations for Stakeholders
For Technology Leaders:
Hybrid Strategy: Consider Google’s approach of enhancing existing systems with AI rather than complete rebuilds
Model Orchestration: Investigate Perplexity’s approach of orchestrating multiple AI models for optimal results
Real-Time Capabilities: Invest in real-time information retrieval and processing systems
Citation Systems: Implement transparent source attribution to build user trust
For Business Strategists:
Revenue Model Innovation: Experiment with subscription, API, and premium feature models beyond traditional advertising
User Experience Focus: Prioritize conversational, answer-first experiences in product development
Distribution Strategy: Evaluate the importance of browser control and default search positions
Competitive Positioning: Decide between AI-enhancement of existing products vs. AI-native alternatives
For Investors:
Platform Risk Assessment: Evaluate how established platforms are adapting to AI disruption
Technology Differentiation: Assess the sustainability of competitive advantages in rapidly evolving AI landscape
Business Model Viability: Monitor the success of alternative monetization strategies beyond advertising
Regulatory Impact: Consider potential regulatory responses to AI-powered information systems and search market concentration
The future of search will be determined by execution quality, user adoption, and the ability to balance innovation with practical business considerations. Both Google and Perplexity have established viable but different paths forward, setting the stage for continued innovation and competition in the AI-powered search landscape.
Monitor the browser control battle and distribution channel acquisitions
Technology Differentiation: Assess the sustainability of competitive advantages in rapidly evolving AI landscape
Business Model Viability: Monitor the success of alternative monetization strategies beyond advertising
Regulatory Impact: Consider potential regulatory responses to AI-powered information systems and search market concentration
Conclusion
The evolution of search from Google’s traditional PageRank-driven approach to today’s AI-powered landscape represents one of the most significant technological shifts in internet history. Google’s recent transformation with its Search Generative Experience and Gemini integration demonstrates that even the most successful platforms must reinvent themselves to remain competitive in the AI era.
The competition between Google’s AI-enhanced strategy and Perplexity’s AI-native approach offers valuable insights into different paths for implementing AI at scale. Google’s hybrid approach leverages massive existing infrastructure while gradually transforming user experiences, while Perplexity’s clean-slate design optimizes entirely for conversational AI interactions.
As both platforms continue to evolve, the ultimate winners will be users who gain access to more intelligent, efficient, and helpful ways to access information. The future of search will likely feature elements of both approaches: the scale and comprehensiveness of Google’s enhanced platform combined with the conversational fluency and transparency of AI-native solutions.
The battle for search supremacy in the AI era has only just begun, and the innovations emerging from this competition will shape how humanity accesses and interacts with information for decades to come.
This analysis reflects the state of AI-powered search as of August 2025. The rapidly evolving nature of AI technology and competitive dynamics may significantly impact future developments. Both Google and Perplexity continue to innovate at unprecedented pace, making ongoing monitoring essential for stakeholders in this space.This analysis represents the current state of AI-powered search as of August 2025. The rapidly evolving nature of AI technology and competitive landscape may impact future developments.
Mark Zuckerberg’s recent move to bring Alex Wang and his team into Meta represents a bold and strategic maneuver amid the rapid advancement of large models and AGI development. Putting aside the ethical considerations, Zuckerberg’s approach—laying off staff, then offering sky-high compensation packages with a 48-hour ultimatum to Top AI scientists and engineers from OpenAI , alongside Meta’s acquisition of a 49% stake in Scale AI—appears to serve multiple objectives:
1. Undermining Competitors
By poaching key talent from rival companies, Meta not only weakens their R&D teams and disrupts their momentum but also puts pressure on Google, OpenAI, and others to reassess their partnerships with Scale AI. Meta’s investment may further marginalize these competitors by injecting uncertainty into their collaboration with Scale AI.
2. Reinvigorating the Internal Team
Bringing in fresh blood like Alex Wang’s team and Open AI Top talents could reenergize Meta’s existing research units. A successful “talent reset” may help the company gain a competitive edge in the race toward AGI.
3. Enhancing Brand Visibility
Even if the move doesn’t yield immediate results, it has already amplified Meta’s media presence, boosting its reputation as a leader in AI innovation.
From both a talent acquisition and PR standpoint, this appears to be a masterstroke for Meta.
However, the strategy is not without significant risks:
1. Internal Integration and Morale Challenges
The massive compensation packages offered to those talents could trigger resentment among existing employees—especially in the wake of recent layoffs—due to perceived pay inequity. This may lower morale and even accelerate internal attrition. Cultural differences between the incoming and incumbent teams could further complicate internal integration and collaboration.
2. Return on Investment and Performance Pressure
Meta’s substantial investment in Alex Wang and Scale AI comes with high expectations for short-term deliverables. In a domain as uncertain as AGI, both the market and shareholders will be eager for breakthroughs. If Wang’s team fails to deliver measurable progress quickly, Meta could face mounting scrutiny and uncertainty over the ROI.
3. Impacts on Scale AI and the Broader Ecosystem
Alex Wang stepping away as CEO is undoubtedly a major loss for Scale AI, even if he retains a board seat. Leadership transitions and potential talent departures may follow. Moreover, Scale AI’s history of legal and compliance issues could reflect poorly on Meta’s brand—especially if public perception ties Meta to those concerns despite holding only non-voting shares. More broadly, Meta’s aggressive “poaching” approach may escalate the AI talent war, drive up industry-wide costs, and prompt renewed debate over ethics and hiring norms in the AI sector.
Conclusion Meta’s latest move is undeniably ambitious. While it positions the company aggressively in the AGI race, it also carries notable risks in terms of internal dynamics, ROI pressure, and broader ecosystem disruption. Only time will tell whether this bold gamble pays off.
应对人工智能的独特错误模式:布鲁斯·施奈尔(Bruce Schneier)和内森·E·桑德斯(Nathan E. Sanders)(网络安全视角)指出,人工智能系统,特别是大型语言模型(LLMs),其错误模式与人类错误显著不同——它们更难预测,不集中在知识空白处,且缺乏对自身错误的自我意识。他们提出双重研究方向:一是工程化人工智能以产生更易于人类理解的错误(例如,通过RLHF等精炼的对齐技术);二是开发专门针对人工智能独特“怪异”之处的新型安全与纠错系统(例如,迭代且多样化的提示)。
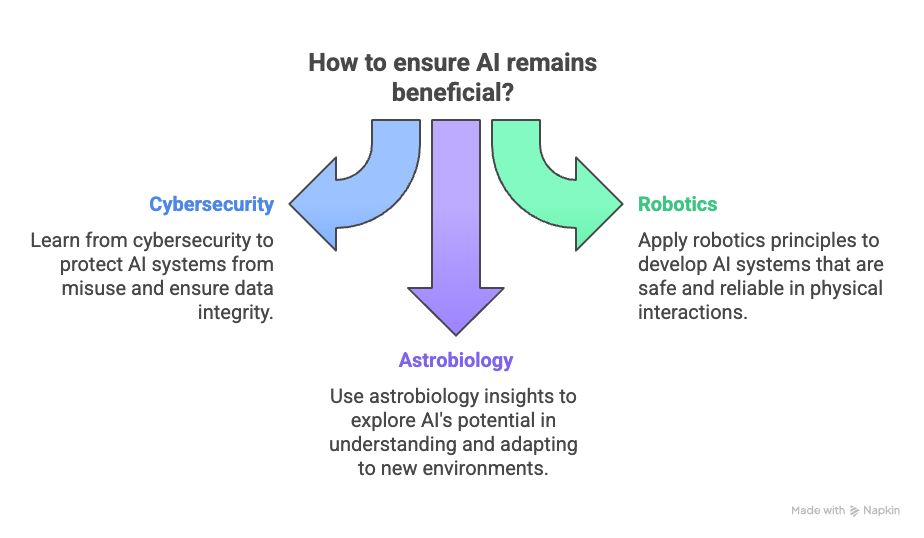
Abstract: this article presents three distinct, cross-disciplinary strategies for ensuring the safe and beneficial development of Artificial Intelligence.
Addressing Idiosyncratic AI Error Patterns (Cybersecurity Perspective): Bruce Schneier and Nathan E. Sanders highlight that AI systems, particularly Large Language Models (LLMs), exhibit error patterns significantly different from human mistakes—being less predictable, not clustered around knowledge gaps, and lacking self-awareness of error. They propose a dual research thrust: engineering AIs to produce more human-intelligible errors (e.g., through refined alignment techniques like RLHF) and developing novel security and mistake-correction systems specifically designed for AI’s unique “weirdness” (e.g., iterative, varied prompting).
Updating Ethical Frameworks to Combat AI Deception (Robotics & Internet Culture Perspective): Dariusz Jemielniak argues that Isaac Asimov’s traditional Three Laws of Robotics are insufficient for modern AI due to the rise of AI-enabled deception, including deepfakes, sophisticated misinformation campaigns, and manipulative AI interactions. He proposes a “Fourth Law of Robotics”: A robot or AI must not deceive a human being by impersonating a human being.Implementing this law would necessitate mandatory AI disclosure, clear labeling of AI-generated content, technical identification standards, legal enforcement, and public AI literacy initiatives to maintain trust in human-AI collaboration.
Establishing Rigorous Protocols for AGI Detection and Interaction (Astrobiology/SETI Perspective): Edmon Begoli and Amir Sadovnik suggest that research into Artificial General Intelligence (AGI) can draw methodological lessons from the Search for Extraterrestrial Intelligence (SETI). They advocate for a structured scientific approach to AGI that includes:
Developing clear, multidisciplinary definitions of “general intelligence” and related concepts like consciousness.
Creating robust, novel metrics and evaluation benchmarks for detecting AGI, moving beyond limitations of tests like the Turing Test.
Formulating internationally recognized post-detection protocols for validation, transparency, safety, and ethical considerations, should AGI emerge.
Collectively, these perspectives emphasize the urgent need for innovative, multi-faceted approaches—spanning security engineering, ethical guideline revision, and rigorous scientific protocol development—to proactively manage the societal integration and potential future trajectory of advanced AI systems.
Here are the full detailed content:
3 Ways to Keep AI on Our Side
AS ARTIFICIAL INTELLIGENCE reshapes society, our traditional safety nets and ethical frameworks are being put to the test. How can we make sure that AI remains a force for good? Here we bring you three fresh visions for safer AI.
In the first essay, security expert Bruce Schneier and data scientist Nathan E. Sanders explore how AI’s “weird” error patterns create a need for innovative security measures that go beyond methods honed on human mistakes.
Dariusz Jemielniak, an authority on Internet culture and technology, argues that the classic robot ethics embodied in Isaac Asimov’s famous rules of robotics need an update to counterbalance AI deception and a world of deepfakes.
And in the final essay, the AI researchers Edmon Begoli and Amir Sadovnik suggest taking a page from the search for intelligent life in the stars; they propose rigorous standards for detecting the possible emergence of human-level AI intelligence.
As AI advances with breakneck speed, these cross-disciplinary strategies may help us keep our hands on the reins.
AI Mistakes Are Very Different from Human Mistakes
WE NEED NEW SECURITY SYSTEMS DESIGNED TO DEAL WITH THEIR WEIRDNESS
Bruce Schneier & Nathan E. Sanders
HUMANS MAKE MISTAKES all the time. All of us do, every day, in tasks both new and routine. Some of our mistakes are minor, and some are catastrophic. Mistakes can break trust with our friends, lose the confidence of our bosses, and sometimes be the difference between life and death.
Over the millennia, we have created security systems to deal with the sorts of mistakes humans commonly make. These days, casinos rotate their dealers regularly, because they make mistakes if they do the same task for too long. Hospital personnel write on patients’ limbs before surgery so that doctors operate on the correct body part, and they count surgical instruments to make sure none are left inside the body. From copyediting to double-entry bookkeeping to appellate courts, we humans have gotten really good at preventing and correcting human mistakes.
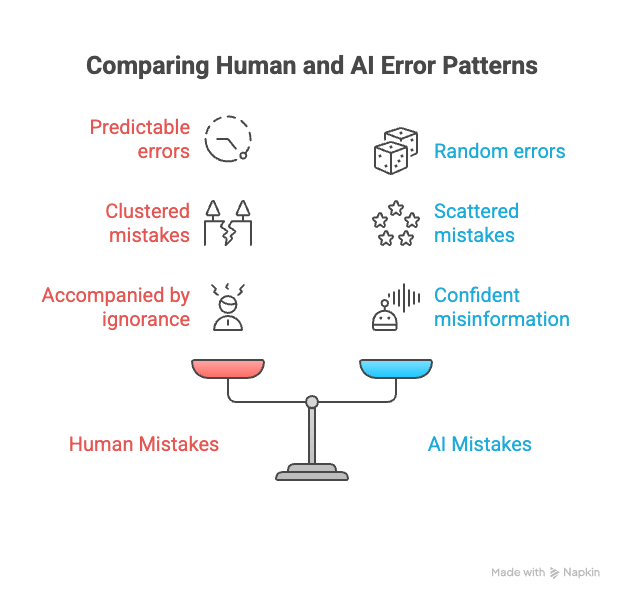
Humanity is now rapidly integrating a wholly different kind of mistakemaker into society: AI. Technologies like large language models (LLMs) can perform many cognitive tasks traditionally fulfilled by humans, but they make plenty of mistakes. You may have heard about chatbots telling people to eat rocks or add glue to pizza. What differentiates AI systems’ mistakes from human mistakes is their weirdness. That is, AI systems do not make mistakes in the same ways that humans do.
Much of the risk associated with our use of AI arises from that difference. We need to invent new security systems that adapt to these differences and prevent harm from AI mistakes.
IT’S FAIRLY EASY to guess when and where humans will make mistakes. Human errors tend to come at the edges of someone’s knowledge: Most of us would make mistakes solving calculus problems. We expect human mistakes to be clustered: A single calculus mistake is likely to be accompanied by others. We expect mistakes to wax and wane depending on factors such as fatigue and distraction. And mistakes are typically accompanied by ignorance: Someone who makes calculus mistakes is also likely to respond “I don’t know” to calculus-related questions.
To the extent that AI systems make these humanlike mistakes, we can bring all of our mistake-correcting systems to bear on their output. But the current crop of AI models—particularly LLMs—make mistakes differently.
AI errors come at seemingly random times, without any clustering around particular topics. The mistakes tend to be more evenly distributed through the knowledge space; an LLM might be equally likely to make a mistake on a calculus question as it is to propose that cabbages eat goats. And AI mistakes aren’t accompanied by ignorance. An LLM will be just as confident when saying something completely and obviously wrong as it will be when saying something true.
The inconsistency of LLMs makes it hard to trust their reasoning in complex, multistep problems. If you want to use an AI model to help with a business problem, it’s not enough to check that it understands what factors make a product profitable; you need to be sure it won’t forget what money is.
THIS SITUATION INDICATES two possible areas of research: engineering LLMs to make mistakes that are more humanlike, and building new mistake-correcting systems that deal with the specific sorts of mistakes that LLMs tend to make.
We already have some tools to lead LLMs to act more like humans. Many of these arise from the field of “alignment” research, which aims to make models act in accordance with the goals of their human developers. One example is the technique that was arguably responsible for the breakthrough success of ChatGPT: reinforcement learning with human feedback. In this method, an AI model is rewarded for producing responses that get a thumbs-up from human evaluators. Similar approaches could be used to induce AI systems to make humanlike mistakes, particularly by penalizing them more for mistakes that are less intelligible.
When it comes to catching AI mistakes, some of the systems that we use to prevent human mistakes will help. To an extent, forcing LLMs to double-check their own work can help prevent errors. But LLMs can also confabulate seemingly plausible yet truly ridiculous explanations for their flights from reason.
Other mistake-mitigation systems for AI are unlike anything we use for humans. Because machines can’t get fatigued or frustrated, it can help to ask an LLM the same question repeatedly in slightly different ways and then synthesize its responses. Humans won’t put up with that kind of annoying repetition, but machines will.
RESEARCHERS ARE still struggling to understand where LLM mistakes diverge from human ones. Some of the weirdness of AI is actually more humanlike than it first appears.
Small changes to a query to an LLM can result in wildly different responses, a problem known as prompt sensitivity. But, as any survey researcher can tell you, humans behave this way, too. The phrasing of a question in an opinion poll can have drastic impacts on the answers.
LLMs also seem to have a bias toward repeating the words that were most common in their training data—for example, guessing familiar place names like “America” even when asked about more exotic locations. Perhaps this is an example of the human “availability heuristic” manifesting in LLMs; like humans, the machines spit out the first thing that comes to mind rather than reasoning through the question. Also like humans, perhaps, some LLMs seem to get distracted in the middle of long documents; they remember more facts from the beginning and end.
In some cases, what’s bizarre about LLMs is that they act more like humans than we think they should. Some researchers have tested the hypothesis that LLMs perform better when offered a cash reward or threatened with death. It also turns out that some of the best ways to “jailbreak” LLMs (getting them to disobey their creators’ explicit instructions) look a lot like the kinds of social-engineering tricks that humans use on each otherfor example, pretending to be someone else or saying that the request is just a joke. But other effective jailbreaking techniques are things no human would ever fall for. One group found that if they used ASCII art (constructions of symbols that look like words or pictures) to pose dangerous questions, like how to build a bomb, the LLM would answer them willingly.
Humans may occasionally make seemingly random, incomprehensible, and inconsistent mistakes, but such occurrences are rare and often indicative of more serious problems. We also tend not to put people exhibiting these behaviors in decision-making positions. Likewise, we should confine AI decision-making systems to applications that suit their actual abilities—while keeping the potential ramifications of their mistakes firmly in mind.
Asimov’s Laws of Robotics Need an Update for AI PROPOSING A FOURTH LAW OF ROBOTICS
Dariusz Jemielniak
IN 1942, the legendary science fiction author Isaac Asimov introduced his Three Laws of Robotics in his short story “Runaround.” The laws were later popularized in his seminal story collection I, Robot.
FIRST LAW: A robot may not injure a human being or, through inaction, allow a human being to come to harm.
SECOND LAW: A robot must obey the orders given it by human beings except where such orders would conflict with the First Law.
THIRD LAW: A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
While drawn from works of fiction, these laws have shaped discussions of robot ethics for decades. And as AI systems—which can be considered virtual robots—have become more sophisticated and pervasive, some technologists have found Asimov’s framework useful for considering the potential safeguards needed for AI that interacts with humans.
But the existing three laws are not enough. Today, we are entering an era of unprecedented human-AI collaboration that Asimov could hardly have envisioned. The rapid advancement of generative AI, particularly in language and image generation, has created challenges beyond Asimov’s original concerns about physical harm and obedience.
THE PROLIFERATION of AI-enabled deception is particularly concerning. According to the FBI’s most recent Internet Crime Report, cybercrime involving digital manipulation and social engineering results in annual losses counted in the billions. The European Union Agency for Cybersecurity’s ENISA Threat Landscape 2023 highlighted deepfakes—synthetic media that appear genuine—as an emerging threat to digital identity and trust.
Social-media misinformation is a huge problem today. I studied it during the pandemic extensively and can say that the proliferation of generative AI tools has made its detection increasingly difficult. AI-generated propaganda is often just as persuasive as or even more persuasive than traditional propaganda, and bad actors can very easily use AI to create convincing content. Deepfakes are on the rise everywhere. Botnets can use AI-generated text, speech, and video to create false perceptions of widespread support for any political issue. Bots are now capable of making phone calls while impersonating people, and AI scam calls imitating familiar voices are increasingly common. Any day now, we can expect a boom in video-call scams based on AI-rendered overlay avatars, allowing scammers to impersonate loved ones and target the most vulnerable populations.
Even more alarmingly, children and teenagers are forming emotional attachments to AI agents, and are sometimes unable to distinguish between interactions with real friends and bots online. Already, there have been suicides attributed to interactions with AI chatbots.
In his 2019 book Human Compatible (Viking), the eminent computer scientist Stuart Russell argues that AI systems’ ability to deceive humans represents a fundamental challenge to social trust. This concern is reflected in recent policy initiatives, most notably the European Union’s AI Act, which includes provisions requiring transparency in AI interactions and transparent disclosure of AI-generated content. In Asimov’s time, people couldn’t have imagined the countless ways in which artificial agents could use online communication tools and avatars to deceive humans.
Therefore, we must make an addition to Asimov’s laws.
FOURTH LAW: A robot or AI must not deceive a human being by impersonating a human being.
WE NEED CLEAR BOUNDARIES. While human-AI collaboration can be constructive, AI deception undermines trust and leads to wasted time, emotional distress, and misuse of resources. Artificial agents must identify themselves to ensure our interactions with them are transparent and productive. AI-generated content should be clearly marked unless it has been significantly edited and adapted by a human.
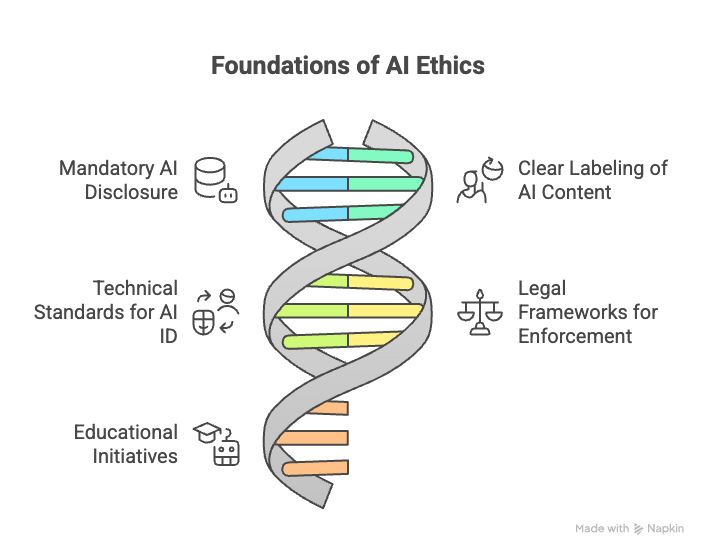
Implementation of this Fourth Law would require
mandatory AI disclosure in direct interactions,
clear labeling of AI-generated content,
technical standards for AI identification,
legal frameworks for enforcement, and
educational initiatives to improve AI literacy.
Of course, all this is easier said than done. Enormous research efforts are already underway to find reliable ways to watermark or detect AI-generated text, audio, images, and videos. But creating the transparency I’m calling for is far from a solved problem.
The future of human-AI collaboration depends on maintaining clear distinctions between human and artificial agents. As noted in the IEEE report Ethically Aligned Design, transparency in AI systems is fundamental to building public trust and ensuring the responsible development of artificial intelligence.
Asimov’s complex stories showed that even robots that tried to follow the rules often discovered there were unintended consequences to their actions. Still, having AI systems that are at least trying to follow Asimov’s ethical guidelines would be a very good start.
What Can AI Researchers Learn from Alien Hunters?
THE SETI INSTITUTE’S APPROACH HAS LESSONS FOR RESEARCH ON ARTIFICIAL GENERAL INTELLIGENCE
Edmon Begoli & Amir Sadovnik
THE EMERGENCE OF artificial general intelligence (systems that can perform any intellectual task a human can) could be the most important event in human history. Yet AGI remains an elusive and controversial concept. We lack a clear definition of what it is, we don’t know how to detect it, and we don’t know how to interact with it if it finally emerges.
What we do know is that today’s approaches to studying AGI are not nearly rigorous enough. Companies like OpenAI are actively striving to create AGI, but they include research on AGI’s social dimensions and safety issues only as their corporate leaders see fit. And academic institutions don’t have the resources for significant efforts.
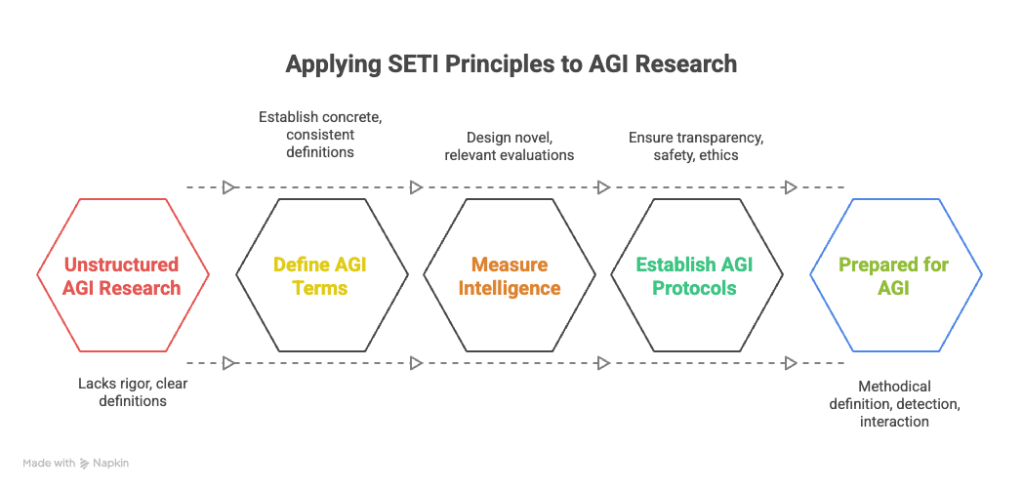
We need a structured scientific approach to prepare for AGI. A useful model comes from an unexpected field: the search for extraterrestrial intelligence, or SETI. We believe that the SETI Institute’s work provides a rigorous framework for detecting and interpreting signs of intelligent life.
The idea behind SETI goes back to the beginning of the space age. In their 1959 Nature paper, the physicists Giuseppe Cocconi and Philip Morrison suggested ways to search for interstellar communication. Given the uncertainty of extraterrestrial civilizations’ existence and sophistication, they theorized about how we should best “listen” for messages from alien societies.
We argue for a similar approach to studying AGI, in all its uncertainties. The last few years have shown a vast leap in AI capabilities. The large language models (LLMs) that power chatbots like ChatGPT and enable them to converse convincingly with humans have renewed the discussion of AGI. One notable 2023 preprint even argued that ChatGPT shows “sparks” of AGI, and today’s most cutting-edge language models are capable of sophisticated reasoning and outperform humans in many evaluations.
While these claims are intriguing, there are reasons to be skeptical. In fact, a large group of scientists have argued that the current set of tools won’t bring us any closer to true AGI. But given the risks associated with AGI, if there is even a small likelihood of it occurring, we must make a serious effort to develop a standard definition of AGI, establish a SETI-like approach to detecting it, and devise ways to safely interact with it if it emerges.
THE CRUCIAL FIRST step is to define what exactly to look for. In SETI’s case, researchers decided to look for certain narrowband signals that would be distinct from other radio signals present in the cosmic background. These signals are considered intentional and only produced by intelligent life. None have been found so far.
In the case of AGI, matters are far more complicated. Today, there is no clear definition of artificial general intelligence. The term is hard to define because it contains other imprecise and controversial terms. Although intelligence has been defined by the Oxford English Dictionary as “the ability to acquire and apply knowledge and skills,” there is still much debate on which skills are involved and how they can be measured. The term general is also ambiguous. Does an AGI need to be able to do absolutely everything a human can do?
One of the first missions of a “SETI for AGI” project must be to clearly define the terms general and intelligence so the research community can speak about them concretely and consistently. These definitions need to be grounded in disciplines such as computer science, measurement science, neuroscience, psychology, mathematics, engineering, and philosophy.
There’s also the crucial question of whether a true AGI must include consciousness and self-awareness. These terms also have multiple definitions, and the relationships between them and intelligence must be clarified. Although it’s generally thought that consciousness isn’t necessary for intelligence, it’s often intertwined with discussions of AGI because creating a self-aware machine would have many philosophical, societal, and legal implications.
NEXT COMES the task of measurement. In the case of SETI, if a candidate narrowband signal is detected, an expert group will verify that it is indeed from an extraterrestrial source. They’ll use established criteria—for example, looking at the signal type and checking for repetition—and conduct assessments at multiple facilities for additional validation.
How to best measure computer intelligence has been a long-standing question in the field. In a famous 1950 paper, Alan Turing proposed the “imitation game,” more widely known as the Turing Test, which assesses whether human interlocutors can distinguish if they are chatting with a human or a machine. Although the Turing Test was useful in the past, the rise of LLMs has made clear that it isn’t a complete enough test to measure intelligence. As Turing himself noted, the relationship between imitating language and thinking is still an open question.
Future appraisals must be directed at different dimensions of intelligence. Although measures of human intelligence are controversial, IQ tests can provide an initial baseline to assess one dimension. In addition, cognitive tests on topics such as creative problem-solving, rapid learning and adaptation, reasoning, and goal-directed behavior would be required to assess general intelligence.
But it’s important to remember that these cognitive tests were designed for humans and might contain assumptions that might not apply to computers, even those with AGI abilities. For example, depending on how it’s trained, a machine may score very high on an IQ test but remain unable to solve much simpler tasks. In addition, an AI may have new abilities that aren’t measurable by our traditional tests. There’s a clear need to design novel evaluations that can alert us when meaningful progress is made toward AGI.
IF WE DEVELOP AGI, we must be prepared to answer questions such as: Is the new form of intelligence a new form of life? What kinds of rights does it have? What are the potential safety concerns, and what is our approach to containing the AGI entity?
Here, too, SETI provides inspiration. SETI’s postdetection protocols emphasize validation, transparency, and international cooperation, with the goal of maximizing the credibility of the process, minimizing sensationalism, and bringing structure to such a profound event. Likewise, we need internationally recognized AGI protocols to bring transparency to the entire process, apply safety-related best practices, and begin the discussion of ethical, social, and philosophical concerns.
We readily acknowledge that the SETI analogy can go only so far. If AGI emerges, it will be a human-made phenomenon. We will likely gradually engineer AGI and see it slowly emerge, so detection might be a process that takes place over a period of years, if not decades. In contrast, the existence of extraterrestrial life is something that we have no control over, and contact could happen very suddenly.
The consequences of a true AGI are entirely unpredictable. To best prepare, we need a methodical approach to defining, detecting, and interacting with AGI, which could be the most important development in human history.
In October of 2024, I was invited by Dr Lydia C. and Dr Peng C to give two presentations as a guest lecturer at La Trobe University (Melbourne) to the students enrolled with CSE5DMI Data Mining and CSE5ML Machine Learning.
The lectures are focused on data mining and machine learning applications and practice in industry and digital retail; and how students should prepare themselves for their future. Attendees are postgraduate students currently enrolled in CSE5ML or CSE5DMI in 2024 Semester 2, approximately 150 students for each subject (CSE5ML or CSE5DMI) who are pursuing one of the following degrees:
This repository is intended for educational purposes only. The content, including presentations and case studies, is provided “as is” without any warranties or guarantees of any kind. The authors and contributors are not responsible for any errors or omissions, or for any outcomes related to the use of this material. Use the information at your own risk. All trademarks, service marks, and company names are the property of their respective owners. The inclusion of any company or product names does not imply endorsement by the authors or contributors.
This is public repository aiming to share the lecture for the public. The *.excalidraw files can be download and open on https://excalidraw.com/)
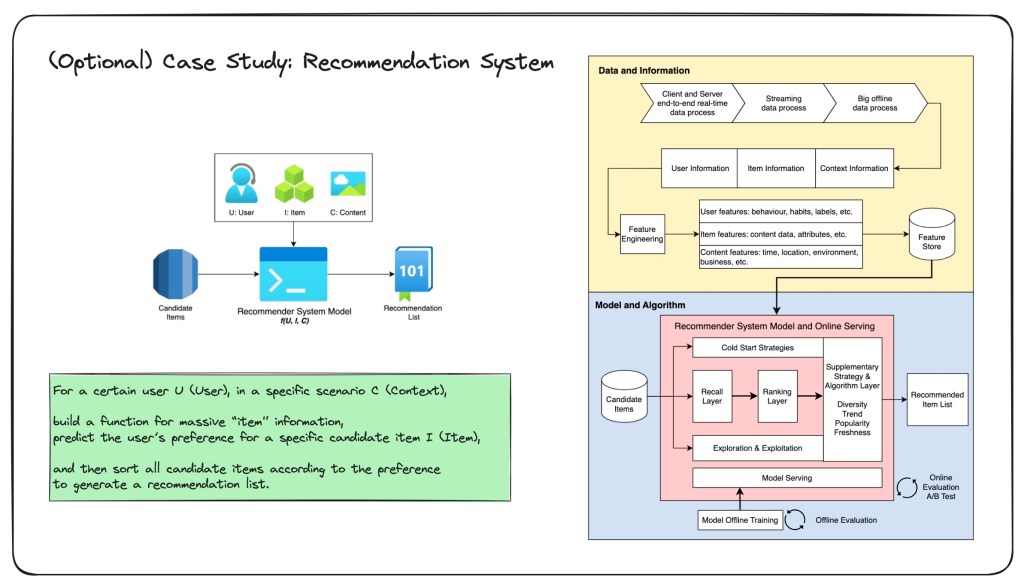
A recommendation system is an artificial intelligence or AI algorithm, usually associated with machine learning, that uses Big Data to suggest or recommend additional products to consumers. These can be based on various criteria, including past purchases, search history, demographic information, and other factors.
This presentation is developed for students of CSE5ML LaTrobe University, Melbourne and used in the guest lecture on 2024 October 14.
Entity matching – the task of clustering duplicated database records to underlying entities.”Given a large collection of records, cluster these records so that the records in each cluster all refer to the same underlying entity.”
This presentation is developed for students of CSE5DMI LaTrobe University, Melbourne and used in the guest lecture on 2024 October 15.
Contribution to the Company and Society
This journey is also align to the Company’s strategy.
Being invited to be a guest lecturer for students with related knowledge backgrounds in 2024 aligns closely with EDG’s core values of “weʼre real, weʼre inclusive, weʼre responsible”.
By participating in a guest lecture and discussion on data analytics and AI/ML practice beyond theories, we demonstrate our commitment to sharing knowledge and expertise, embodying our responsibility to contribute positively to the academic community and bridge the gap between theory builders and problem solvers.
This event allows us to inspire and educate students in the same domains at La Trobe University, showcasing our passion and enthusiasm for the business. Through this engagement, we aim to positively impact attendees, providing suggestions for their career paths, and fostering a spirit of collaboration and continuous learning.
Showing our purpose, values, and ways of working will impress future graduates who may want to come and work for us, want to stay and thrive with us. It also helps us deliver on our purpose to create a more sociable future, together.
Moreover, I am grateful for all the support and encouragement I have received from my university friends and teammates throughout this journey. Additionally, the teaching resources and environment in the West Lecture Theatres at La Trobe University are outstanding!