

TL;DR, Play the podcast (Audio Overview generated by NotebookLM)
- Abstract
- Google’s AI Transformation: From PageRank to Gemini-Powered Search
- Perplexity AI Architecture: The RAG-Powered Search Revolution
- The New Search Paradigm: AI-First vs AI-Enhanced Approaches
- The Future of AI-Powered Search: A New Competitive Landscape
- Strategic Implications and Future Outlook
- Recommendations for Stakeholders
- Conclusion
Abstract
This blog examines the rapidly evolving landscape of AI-powered search, comparing Google’s recent transformation with its Search Generative Experience (SGE) and Gemini integration against Perplexity AI‘s native AI-first approach. Both companies now leverage large language models, but with fundamentally different architectures and philosophies.
The New Reality: Google has undergone a dramatic transformation from traditional keyword-based search to an AI-driven conversational answer engine. With the integration of Gemini, LaMDA, PaLM, and the rollout of AI Overviews (formerly SGE), Google now synthesizes information from multiple sources into concise, contextual answers—directly competing with Perplexity’s approach.
Key Findings:
- Convergent Evolution: Both platforms now use LLMs for answer generation, but Google maintains its traditional search infrastructure while Perplexity was built AI-first from the ground up
- Architecture Philosophy: Google integrates AI capabilities into its existing search ecosystem (hybrid approach), while Perplexity centers everything around RAG and multi-model orchestration (AI-native approach)
- AI Technology Stack: Google leverages Gemini (multimodal), LaMDA (conversational), and PaLM models, while Perplexity orchestrates external models (GPT, Claude, Gemini, Llama, DeepSeek)
- User Experience: Google provides AI Overviews alongside traditional search results, while Perplexity delivers answer-first experiences with citations
- Market Dynamics: The competition has intensified with Google’s AI transformation, making the choice between platforms more about implementation philosophy than fundamental capabilities
This represents a paradigm shift where the question is no longer “traditional vs. AI search” but rather “how to best implement AI-powered search” with different approaches to integration, user experience, and business models.
Keywords: AI Search, RAG, Large Language Models, Search Architecture, Perplexity AI, Google Search, Conversational AI, SGE, Gemini.
Google’s AI Transformation: From PageRank to Gemini-Powered Search
Google has undergone one of the most significant transformations in its history, evolving from a traditional link-based search engine to an AI-powered answer engine. This transformation represents a strategic response to the rise of AI-first search platforms and changing user expectations.
The Search Generative Experience (SGE) Revolution
Google’s Search Generative Experience (SGE), now known as AI Overviews, fundamentally changes how search results are presented:
- AI-Synthesized Answers: Instead of just providing links, Google’s AI generates comprehensive insights, explanations, and summaries from multiple sources
- Contextual Understanding: Responses consider user context including location, search history, and preferences for personalized results
- Multi-Step Query Handling: The system can handle complex, conversational queries that require reasoning and synthesis
- Real-Time Information Grounding: AI overviews are grounded in current, real-time information while maintaining accuracy
Google’s LLM Arsenal
Google has strategically integrated multiple advanced AI models into its search infrastructure:
Gemini: The Multimodal Powerhouse
- Capabilities: Understands and generates text, images, videos, and audio
- Search Integration: Enables complex query handling including visual search, reasoning tasks, and detailed information synthesis
- Multimodal Processing: Handles queries that combine text, images, and other media types
LaMDA: Conversational AI Foundation
- Purpose: Powers natural, dialogue-like interactions in search
- Features: Enables follow-up questions and conversational context maintenance
- Integration: Supports Google’s shift toward conversational search experiences
PaLM: Large-Scale Language Understanding
- Role: Provides advanced language processing capabilities
- Applications: Powers complex reasoning, translation (100+ languages), and contextual understanding
- Scale: Handles extended documents and multimodal inputs
Technical Architecture Integration
Google’s approach differs from AI-first platforms by layering AI capabilities onto existing infrastructure:
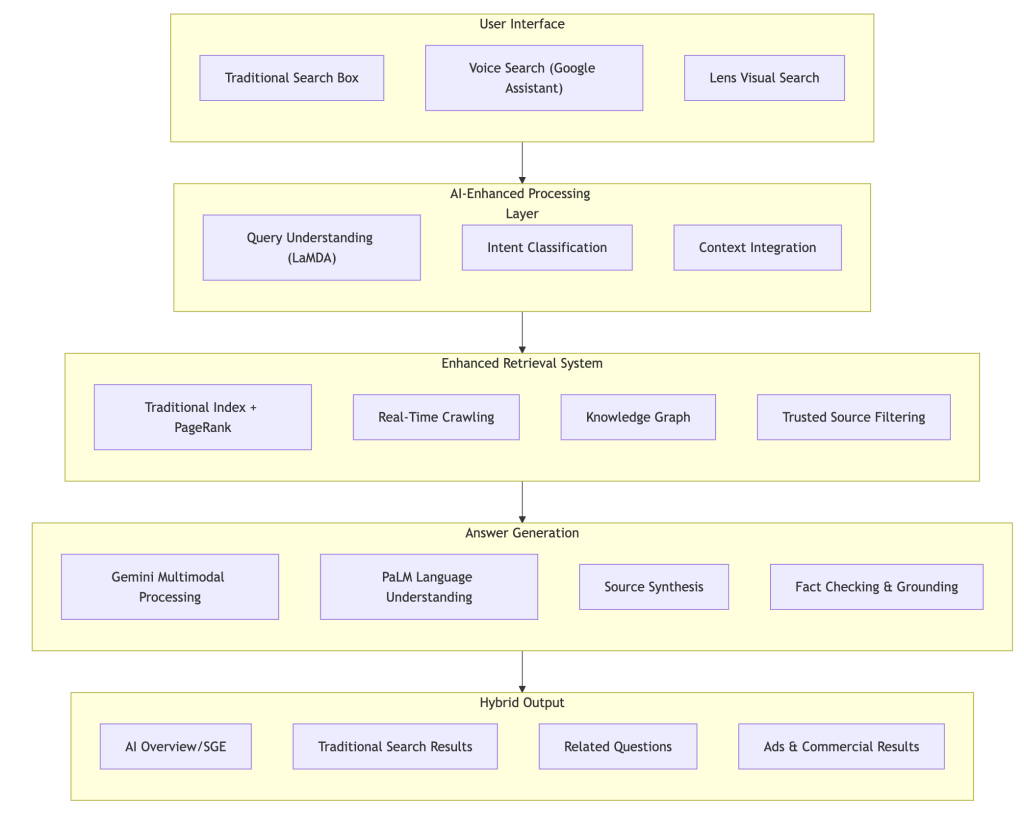
Key Differentiators of Google’s AI Search
- Hybrid Architecture: Maintains traditional search capabilities while adding AI-powered features
- Scale Integration: Leverages existing massive infrastructure and data
- DeepMind Synergy: Strategic integration of DeepMind research into commercial search applications
- Continuous Learning: ML ranking algorithms and AI models learn from user interactions in real-time
- Global Reach: AI features deployed across 100+ languages with localized understanding
Perplexity AI Architecture: The RAG-Powered Search Revolution
Perplexity AI represents a fundamental reimagining of search technology, built on three core innovations:
- Retrieval-Augmented Generation (RAG): Combines real-time web crawling with large language model capabilities
- Multi-Model Orchestration: Leverages multiple AI models (GPT, Claude, Gemini, Llama, DeepSeek) for optimal responses
- Integrated Citation System: Provides transparent source attribution with every answer
The platform offers multiple access points to serve different user needs: Web Interface, Mobile App, Comet Browser, and Enterprise API.
Core Architecture Components
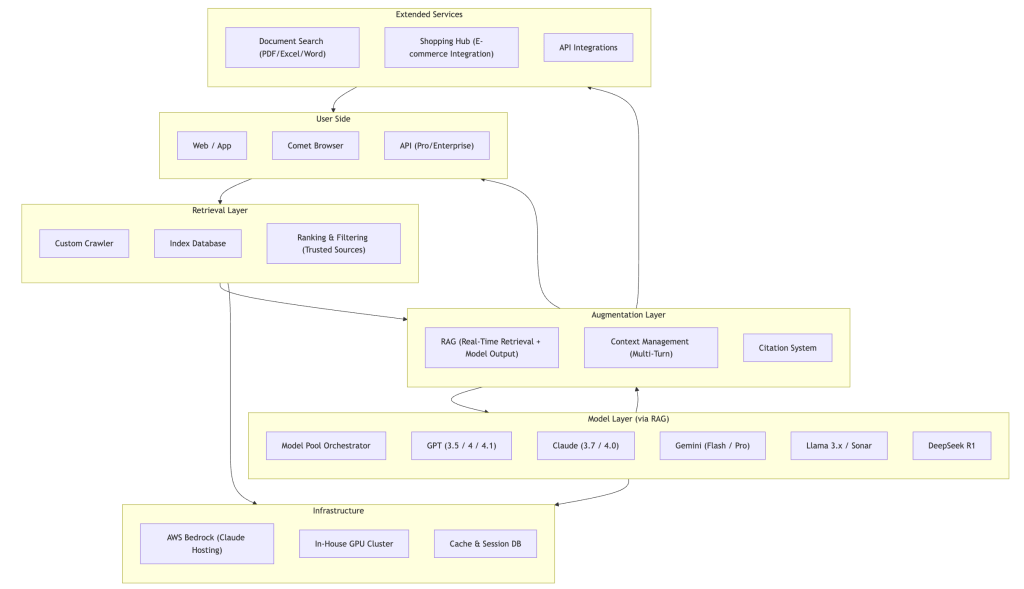
Simplified Architecture View
For executive presentations and high-level discussions, this three-layer view highlights the essential components:
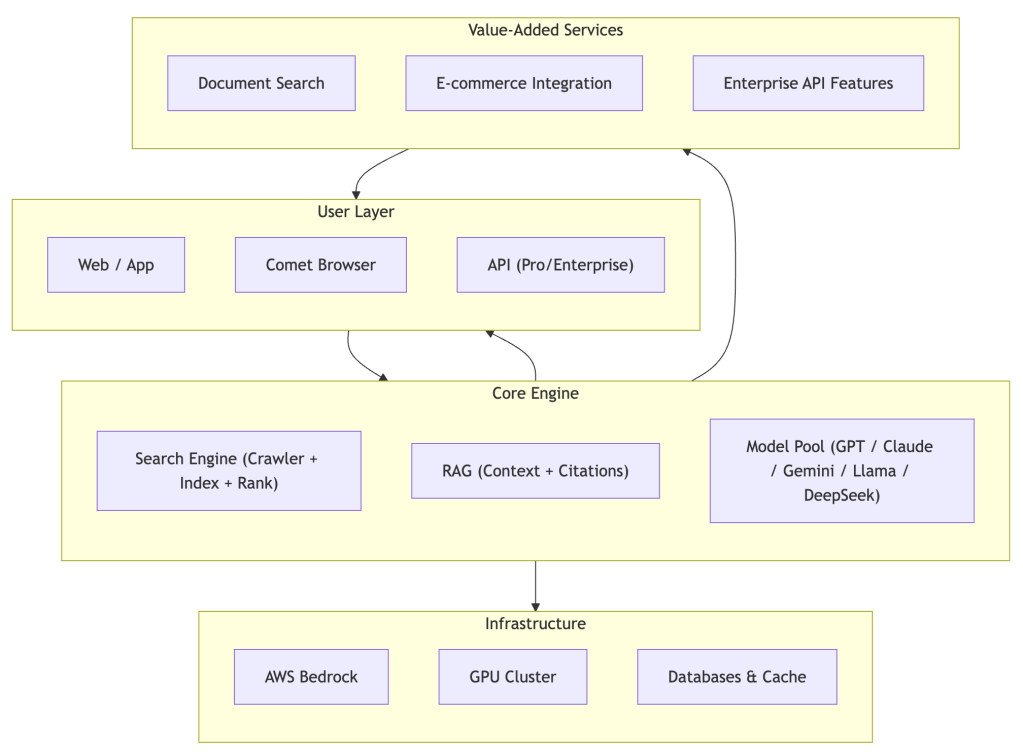
How Perplexity Works: From Query to Answer
Understanding Perplexity’s workflow reveals why it delivers fundamentally different results than traditional search engines. Unlike Google’s approach of matching keywords to indexed pages, Perplexity follows a sophisticated multi-step process:
The Eight-Step Journey
- Query Reception: User submits a natural language question through any interface
- Real-Time Retrieval: Custom crawlers search the web for current, relevant information
- Source Indexing: Retrieved content is processed and indexed in real-time
- Context Assembly: RAG system compiles relevant information into coherent context
- Model Selection: AI orchestrator chooses the optimal model(s) for the specific query type
- Answer Generation: Selected model(s) generate comprehensive responses using retrieved context
- Citation Integration: System automatically adds proper source attribution
- Response Delivery: Final answer with citations is presented to the user
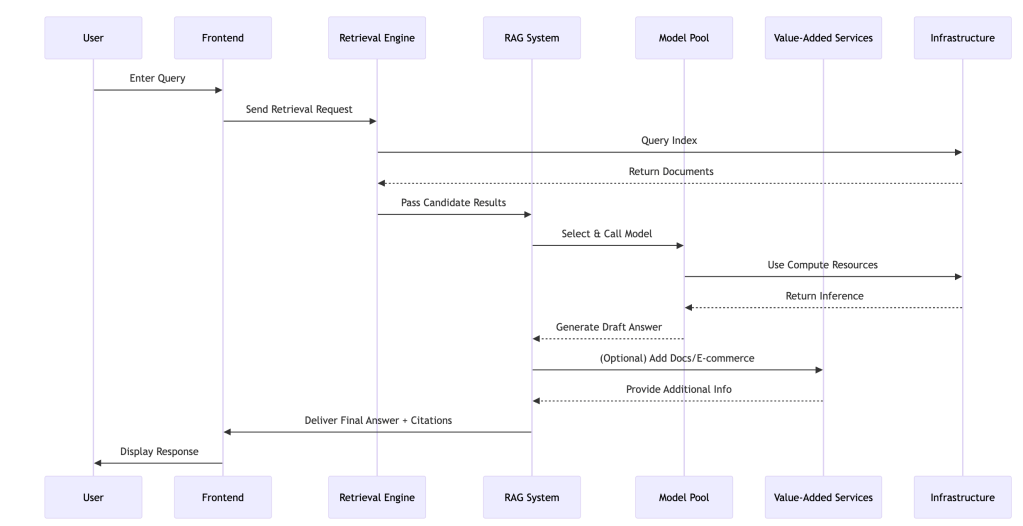
Technical Workflow Diagram
The sequence below shows how a user query flows through Perplexity’s system.
This process typically completes in under 3 seconds, delivering both speed and accuracy.
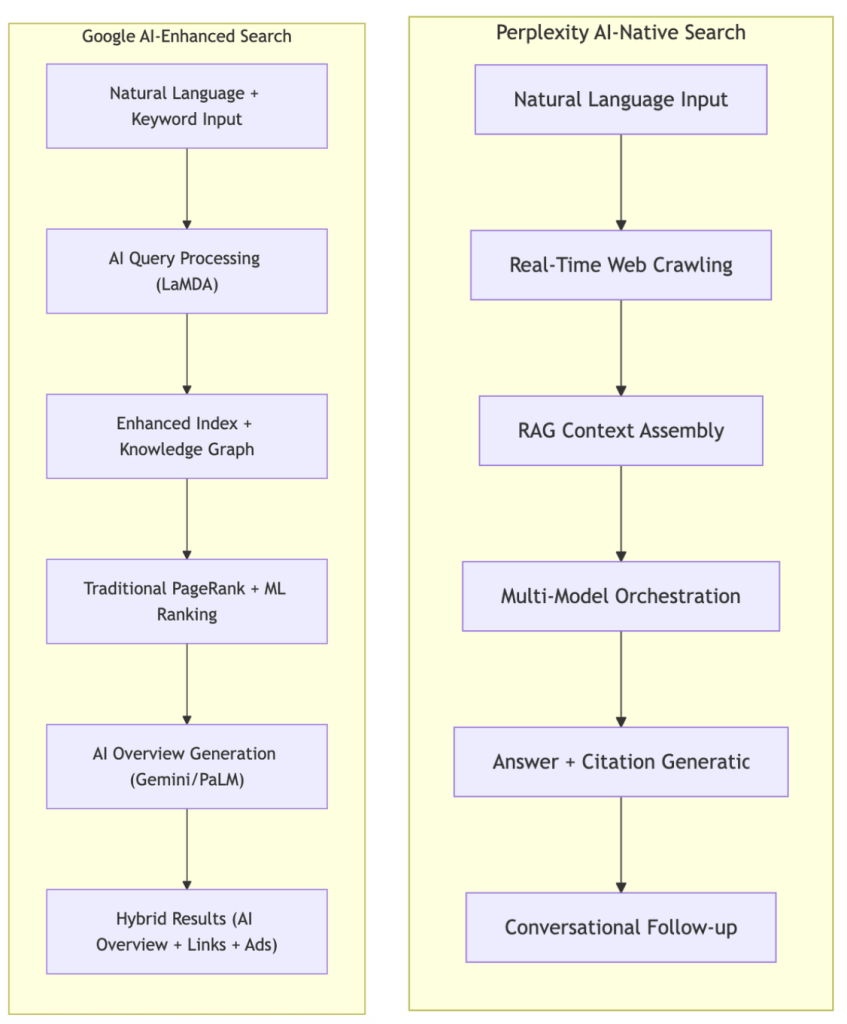
The New Search Paradigm: AI-First vs AI-Enhanced Approaches
The competition between Google and Perplexity has evolved beyond traditional vs. AI search to represent two distinct philosophies for implementing AI-powered search experiences.
Google’s Philosophy: “AI-Enhanced Universal Search”
- Hybrid Integration: Layer advanced AI capabilities onto proven search infrastructure
- Comprehensive Coverage: Maintain traditional search results alongside AI-generated overviews
- Gradual Transformation: Evolve existing user behaviors rather than replace them entirely
- Scale Advantage: Leverage massive existing data and infrastructure for AI training and deployment
Perplexity’s Philosophy: “AI-Native Conversational Search”
- Model Agnostic: Orchestrate best-in-class models rather than developing proprietary AI
- Clean Slate Design: Built from the ground up with AI-first architecture
- Answer-Centric: Focus entirely on direct answer generation with source attribution
- Conversational Flow: Design for multi-turn, contextual conversations rather than single queries
Comprehensive Technology & Business Comparison
| Dimension | Google AI-Enhanced Search | Perplexity AI-Native Search |
|---|---|---|
| Input | Natural language + traditional keywords | Pure natural language, conversational |
| AI Models | Gemini, LaMDA, PaLM (proprietary) | GPT, Claude, Gemini, Llama, DeepSeek (orchestrated) |
| Architecture | Hybrid (AI + traditional infrastructure) | Pure AI-first (RAG-centered) |
| Retrieval | Enhanced index + Knowledge Graph + real-time | Custom crawler + real-time retrieval |
| Core Tech | AI Overviews + traditional ranking | RAG + multi-model orchestration |
| Output | Hybrid (AI Overview + links + ads) | Direct answers with citations |
| Context | Limited conversational memory | Full multi-turn conversation memory |
| Extensions | Maps, News, Shopping, Ads integration | Document search, e-commerce, APIs |
| Business | Ad-driven + AI premium features | Subscription + API + e-commerce |
| UX | “AI answers + traditional options” | “Conversational AI assistant” |
| Products | Google Search with SGE/AI Overview | Perplexity Web/App, Comet Browser |
| Deployment | Global rollout with localization | Global expansion, English-focused |
| Data Advantage | Massive proprietary data + real-time | Real-time web data + model diversity |
| Products | Google Search, Ads | Perplexity Web/App, Comet Browser |
The Future of AI-Powered Search: A New Competitive Landscape
The integration of AI into search has fundamentally changed the competitive landscape. Rather than a battle between traditional and AI search, we now see different approaches to implementing AI-powered experiences competing for user mindshare and market position.
Implementation Strategy Battle: Integration vs. Innovation
Google’s Integration Strategy:
- Advantage: Massive user base and infrastructure to deploy AI features at scale
- Challenge: Balancing AI innovation with existing business model dependencies
- Approach: Gradual rollout of AI features while maintaining traditional search options
Perplexity’s Innovation Strategy:
- Advantage: Clean slate design optimized for AI-first experiences
- Challenge: Building user base and competing with established platforms
- Approach: Focus on superior AI experience to drive user acquisition
The Multi-Modal Future
Both platforms are moving toward comprehensive multi-modal experiences:
- Visual Search Integration: Google Lens vs. Perplexity’s image understanding capabilities
- Voice-First Interactions: Google Assistant integration vs. conversational AI interfaces
- Video and Audio Processing: Gemini’s multimodal capabilities vs. orchestrated model approaches
- Document Intelligence: Enterprise document search and analysis capabilities
Business Model Evolution Under AI
Advertising Model Transformation:
- Google must adapt its ad-centric model to AI Overviews without disrupting user experience
- Challenge of monetizing direct answers vs. traditional click-through advertising
- Need for new ad formats that work with conversational AI
Subscription and API Models:
- Perplexity’s success with subscription tiers validates alternative monetization
- Growing enterprise demand for AI-powered search APIs and integrations
- Premium features becoming differentiators (document search, advanced models, higher usage limits)
Technical Architecture Convergence
Despite different starting points, both platforms are converging on similar technical capabilities:
- Real-Time Information: Both now emphasize current, up-to-date information retrieval
- Source Attribution: Transparency and citation becoming standard expectations
- Conversational Context: Multi-turn conversation support across platforms
- Model Diversity: Google developing multiple specialized models, Perplexity orchestrating external models
The Browser and Distribution Channel Wars
Perplexity’s Chrome Acquisition Strategy:
- $34.5B all-cash bid for Chrome represents unprecedented ambition in AI search competition
- Strategic Value: Control over browser defaults, user data, and search distribution
- Market Impact: Success would fundamentally alter competitive dynamics and user acquisition costs
- Regulatory Reality: Bid likely serves as strategic positioning and leverage rather than realistic acquisition
Alternative Distribution Strategies:
- AI-native browsers (Comet) as specialized entry points
- API integrations into enterprise and developer workflows
- Mobile-first experiences capturing younger user demographics
Strategic Implications and Future Outlook
The competition between Google’s AI-enhanced approach and Perplexity’s AI-native strategy represents a fascinating case study in how established platforms and startups approach technological transformation differently.
Key Strategic Insights
- The AI Integration Challenge: Google’s transformation demonstrates that even dominant platforms must fundamentally reimagine their core products to stay competitive in the AI era
- Architecture Philosophy Matters: The choice between hybrid integration (Google) vs. AI-first design (Perplexity) creates different strengths, limitations, and user experiences
- Business Model Pressure: AI-powered search challenges traditional advertising models, forcing experimentation with subscriptions, APIs, and premium features
- User Behavior Evolution: Both platforms are driving the shift from “search and browse” to “ask and receive” interactions, fundamentally changing how users access information
The New Competitive Dynamics
Advantages of Google’s AI-Enhanced Approach:
- Massive scale and infrastructure for global AI deployment
- Existing user base to gradually transition to AI features
- Deep integration with knowledge graphs and proprietary data
- Ability to maintain traditional search alongside AI innovations
Advantages of Perplexity’s AI-Native Approach:
- Optimized user experience designed specifically for conversational AI
- Agility to implement cutting-edge AI techniques without legacy constraints
- Model-agnostic architecture leveraging best-in-class external AI models
- Clear value proposition for users seeking direct, cited answers
Looking Ahead: Industry Predictions
Near-Term (1-2 years):
- Continued convergence of features between platforms
- Google’s global rollout of AI Overviews across all markets and languages
- Perplexity’s expansion into enterprise and specialized vertical markets
- Emergence of more AI-native search platforms following Perplexity’s model
Medium-Term (3-5 years):
- AI-powered search becomes the standard expectation across all platforms
- Specialized AI search tools for professional domains (legal, medical, scientific research)
- Integration of real-time multimodal capabilities (live video analysis, augmented reality search)
- New regulatory frameworks for AI-powered information systems
Long-Term (5+ years):
- Fully conversational AI assistants replace traditional search interfaces
- Personal AI agents that understand individual context and preferences
- Integration with IoT and ambient computing for seamless information access
- Potential emergence of decentralized, blockchain-based search alternatives
Recommendations for Stakeholders
For Technology Leaders:
- Hybrid Strategy: Consider Google’s approach of enhancing existing systems with AI rather than complete rebuilds
- Model Orchestration: Investigate Perplexity’s approach of orchestrating multiple AI models for optimal results
- Real-Time Capabilities: Invest in real-time information retrieval and processing systems
- Citation Systems: Implement transparent source attribution to build user trust
For Business Strategists:
- Revenue Model Innovation: Experiment with subscription, API, and premium feature models beyond traditional advertising
- User Experience Focus: Prioritize conversational, answer-first experiences in product development
- Distribution Strategy: Evaluate the importance of browser control and default search positions
- Competitive Positioning: Decide between AI-enhancement of existing products vs. AI-native alternatives
For Investors:
- Platform Risk Assessment: Evaluate how established platforms are adapting to AI disruption
- Technology Differentiation: Assess the sustainability of competitive advantages in rapidly evolving AI landscape
- Business Model Viability: Monitor the success of alternative monetization strategies beyond advertising
- Regulatory Impact: Consider potential regulatory responses to AI-powered information systems and search market concentration
The future of search will be determined by execution quality, user adoption, and the ability to balance innovation with practical business considerations. Both Google and Perplexity have established viable but different paths forward, setting the stage for continued innovation and competition in the AI-powered search landscape.
- Monitor the browser control battle and distribution channel acquisitions
- Technology Differentiation: Assess the sustainability of competitive advantages in rapidly evolving AI landscape
- Business Model Viability: Monitor the success of alternative monetization strategies beyond advertising
- Regulatory Impact: Consider potential regulatory responses to AI-powered information systems and search market concentration
Conclusion
The evolution of search from Google’s traditional PageRank-driven approach to today’s AI-powered landscape represents one of the most significant technological shifts in internet history. Google’s recent transformation with its Search Generative Experience and Gemini integration demonstrates that even the most successful platforms must reinvent themselves to remain competitive in the AI era.
The competition between Google’s AI-enhanced strategy and Perplexity’s AI-native approach offers valuable insights into different paths for implementing AI at scale. Google’s hybrid approach leverages massive existing infrastructure while gradually transforming user experiences, while Perplexity’s clean-slate design optimizes entirely for conversational AI interactions.
As both platforms continue to evolve, the ultimate winners will be users who gain access to more intelligent, efficient, and helpful ways to access information. The future of search will likely feature elements of both approaches: the scale and comprehensiveness of Google’s enhanced platform combined with the conversational fluency and transparency of AI-native solutions.
The battle for search supremacy in the AI era has only just begun, and the innovations emerging from this competition will shape how humanity accesses and interacts with information for decades to come.
This analysis reflects the state of AI-powered search as of August 2025. The rapidly evolving nature of AI technology and competitive dynamics may significantly impact future developments. Both Google and Perplexity continue to innovate at unprecedented pace, making ongoing monitoring essential for stakeholders in this space. This analysis represents the current state of AI-powered search as of August 2025. The rapidly evolving nature of AI technology and competitive landscape may impact future developments.












