
2024-Feb-04: 1st Version
- Introduction
- Basic Prompting
- Perfect Prompt Formula for ChatBots
- RAG, CoT, ReACT, SASE, DSP …
- Summary and Conclusion
- Reference

Introduction
Prompt Engineering, also known as In-Context Prompting, refers to methods for communicating with a Large Language Model (LLM) like GPT (Generative Pre-trained Transformer) to manipulate/steer its behaviour for expected outcomes without updating, retraining or fine-tuning the model weights.
Researchers, developers, or users may engage in prompt engineering to instruct a model for specific tasks, improve the model’s performance, or adapt it to better understand and respond to particular inputs. It is an empirical science and the effect of prompt engineering methods can vary a lot among models, thus requiring heavy experimentation and heuristics.
This post only focuses on prompt engineering for autoregressive language models, so nothing with image generation or multimodality models.
Basic Prompting
Zero-shot and few-shot learning are the two most basic approaches for prompting the model, pioneered by many LLM papers and commonly used for benchmarking LLM performance. That is to say, Zero-shot and few-shot testing are scenarios used to evaluate the performance of large language models (LLMs) in handling tasks with little or no training data. Here are examples for both:
Zero-shot
Zero-shot learning simply feeds the task text to the model and asks for results.
Scenario: Text Completion (Please try the following input in ChatGPT or Google Bard)
Input:
Task: Complete the following sentence:
Input: The capital of France is ____________.
Output (ChatGPT / Bard):
Output: The capital of France is Paris.
Few-shot
Few-shot learning presents a set of high-quality demonstrations, each consisting of both input and desired output, on the target task. As the model first sees good examples, it can better understand human intention and criteria for what kinds of answers are wanted. Therefore, few-shot learning often leads to better performance than zero-shot. However, it comes at the cost of more token consumption and may hit the context length limit when the input and output text are long.
Scenario: Text Classification
Input:
Task: Classify movie reviews as positive or negative.
Examples:
Review 1: This movie was amazing! The acting was superb.
Sentiment: Positive
Review 2: I couldn't stand this film. The plot was confusing.
Sentiment: Negative
Question:
Review: I'll bet the video game is a lot more fun than the film.
Sentiment:____
Output
Sentiment: Negative
Many studies have explored the construction of in-context examples to maximize performance. They observed that the choice of prompt format, training examples, and the order of the examples can significantly impact performance, ranging from near-random guesses to near-state-of-the-art performance.
Hallucination
In the context of Large Language Models (LLMs), hallucination refers to a situation where the model generates outputs that are incorrect or not grounded in reality. A hallucination occurs when the model produces information that seems plausible or coherent but is actually not accurate or supported by the input data.
For example, in a language generation task, if a model is asked to provide information about a topic and it generates details that are not factually correct or have no basis in the training data, it can be considered as hallucination. This phenomenon is a concern in natural language processing because it can lead to the generation of misleading or false information.
Addressing hallucination in LLMs is a challenging task, and researchers are actively working on developing methods to improve the models’ accuracy and reliability. Techniques such as fine-tuning, prompt engineering, and designing more specific evaluation metrics are among the approaches used to mitigate hallucination in language models.
Perfect Prompt Formula for ChatBots
For personal daily documenting work such as text generation, there are six key components making up the perfect formula for ChatGPT and Google Bard:
Task, Context, Exemplars, Persona, Format, and Tone.
Prompt Formula for ChatBots
- The Task sentence needs to articulate the end goal and start with an action verb.
- Use three guiding questions to help structure relevant and sufficient Context.
- Exemplars can drastically improve the quality of the output by giving specific examples for the AI to reference.
- For Persona, think of who you would ideally want the AI to be in the given task situation.
- Visualizing your desired end result will let you know what format to use in your prompt.
- And you can actually use ChatGPT to generate a list of Tone keywords for you to use!

RAG, CoT, ReACT, SASE, DSP …
If you are ever curious about what the heck are those techies talking about with the above words? Please continues …
OK, so here’s the deal. We’re diving into the world of academia, talking about machine learning and large language models in the computer science and engineering domains. I’ll try to explain it in a simple way, but you can always dig deeper into these topics elsewhere.
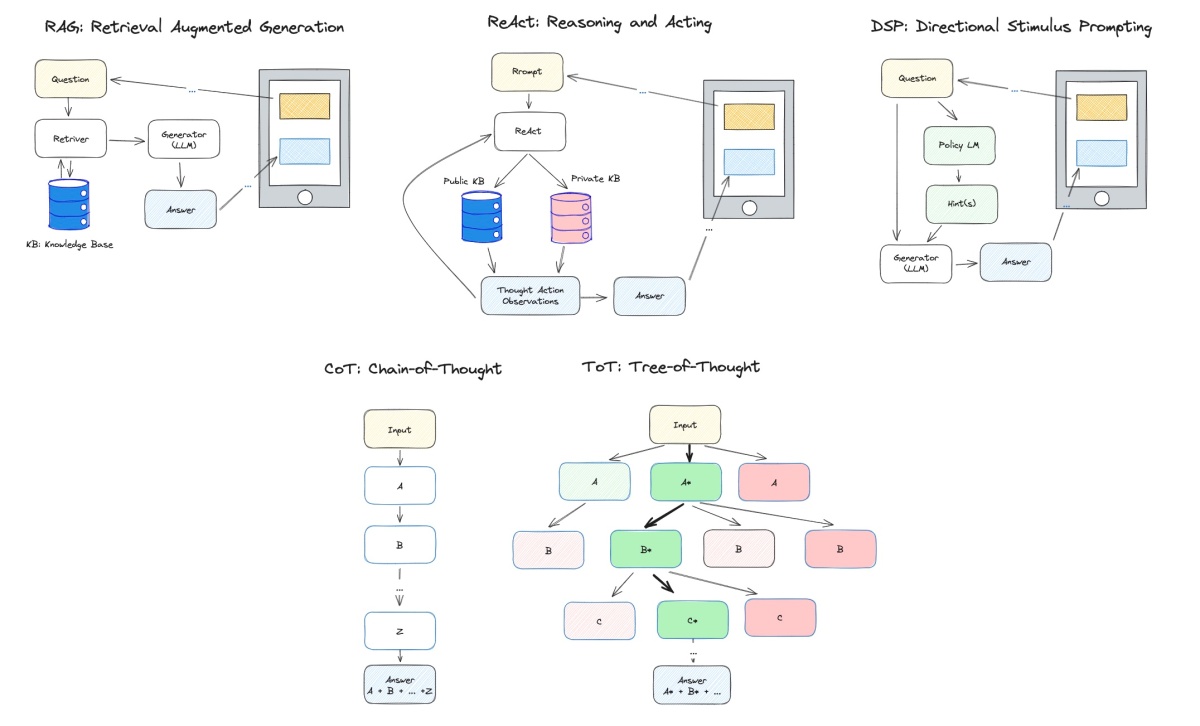
RAG: Retrieval-Augmented Generation
RAG (Retrieval-Augmented Generation): RAG typically refers to a model that combines both retrieval and generation approaches. It might use a retrieval mechanism to retrieve relevant information from a database or knowledge base and then generate a response based on that retrieved information. In real applications, the users’ input and the model’s output will be pre/post-processed to follow certain rules and obey laws and regulations.

Here is a simplified example of using a Retrieval-Augmented Generation (RAG) model for a question-answering task. In this example, we’ll use a system that retrieves relevant passages from a knowledge base and generates an answer based on that retrieved information.
Input:
User Query: What are the symptoms of COVID-19?
Knowledge Base:
1. Title: Symptoms of COVID-19
Content: COVID-19 symptoms include fever, cough, shortness of breath, fatigue, body aches, loss of taste or smell, sore throat, etc.
2. Title: Prevention measures for COVID-19
Content: To prevent the spread of COVID-19, it's important to wash hands regularly, wear masks, practice social distancing, and get vaccinated.
3. Title: COVID-19 Treatment
Content: COVID-19 treatment involves rest, hydration, and in severe cases, hospitalization may be required.
RAG Model Output:
Generated Answer:
The symptoms of COVID-19 include fever, cough, shortness of breath, fatigue, body aches, etc.
Remark: ChatGPT 3.5 will give basic results like the above. But, Google Bard will provide extra resources like CDC links and other sources it gets from the Search Engines. We could guess Google used a different framework to OpenAI.
CoT: Chain-of-Thought
Chain-of-thought (CoT) prompting (Wei et al. 2022) generates a sequence of short sentences to describe reasoning logics step by step, known as reasoning chains or rationales, to eventually lead to the final answer.
The benefit of CoT is more pronounced for complicated reasoning tasks while using large models (e.g. with more than 50B parameters). Simple tasks only benefit slightly from CoT prompting.
Tree of Thoughts (Yao et al. 2023) extends CoT by exploring multiple reasoning possibilities at each step. It first decomposes the problem into multiple thought steps and generates multiple thoughts per step, essentially creating a tree structure. The search process can be BFS or DFS while each state is evaluated by a classifier (via a prompt) or majority vote.

Self-Ask + Search Engine
Self-Ask (Press et al. 2022) is a method to repeatedly prompt the model to ask follow-up questions to construct the thought process iteratively. Follow-up questions can be answered by search engine results.

ReAct: Reasoning and Acting
ReAct (Reason + Act; Yao et al. 2023) combines iterative CoT prompting with queries to Wikipedia APIs to search for relevant entities and content and then add it back into the context.
In each trajectory consists of multiple thought-action-observation steps (i.e. dense thought), where free-form thoughts are used for various purposes.


Specifically, from the paper, the authors use a combination of thoughts that decompose questions (“I need to search x, find y, then find z”), extract information from Wikipedia observations (“x was started in 1844”, “The paragraph does not tell x”), perform commonsense (“x is not y, so z must instead be…”) or arithmetic reasoning (“1844 < 1989”), guide search reformulation (“maybe I can search/lookup x instead”), and synthesize the final answer (“…so the answer is x”).

DSP: Directional Stimulus Prompting
Directional Stimulus Prompting (DSP, Z. Li 2023), is a novel framework for guiding black-box large language models (LLMs) toward specific desired outputs. Instead of directly adjusting LLMs, this method employs a small tunable policy model to generate an auxiliary directional stimulus (hints) prompt for each input instance.


Summary and Conclusion
Prompt engineering involves carefully crafting these prompts to achieve desired results. It can include experimenting with different phrasings, structures, and strategies to elicit the desired information or responses from the model. This process is crucial because the performance of language models can be sensitive to how prompts are formulated.
I believe a lot of researchers will agree with me. Some prompt engineering papers don’t need to be 8 pages long. They could explain the important points in just a few lines and use the rest for benchmarking.
As researchers and developers delve further into the realms of prompt engineering, they continue to push the boundaries of what these sophisticated models can achieve.
To achieve this, it’s important to create a user-friendly LLM benchmarking system that many people will use. Developing better methods for creating prompts will help advance language models and improve how we use LLMs. These efforts will have a big impact on natural language processing and related fields.
Reference
- Weng, Lilian. (Mar 2023). Prompt Engineering. Lil’Log.
- IBM (Jan 2024) 4 Methods of Prompt Engineering
- Jeff Su (Aug 2023) Master the Perfect ChatGPT Prompt Formula
