

Transformer model architectures have garnered immense interest lately due to their effectiveness across a range of domains like language, vision and reinforcement learning. In the field of natural language processing for example, Transformers have become an indispensable staple in the modern deep learning stack. Recently, a dizzying number of “X-former” models have been proposed – Reformer, Linformer, Performer, Longformer, to name a few – which improve upon the original Transformer architecture, many of which make improvements around computational and memory efficiency. With the aim of helping the avid researcher navigate this flurry, this paper characterizes a large and thoughtful selection of recent efficiency-flavored “X-former” models, providing an organized and comprehensive overview of existing work and models across multiple domains.
In this paper, the authors propose a taxonomy of efficient Transformer models, characterizing them by the technical innovation and primary use case. Specifically, they review Transformer models that have applications in both language and vision domains, attempting to consolidate the literature across the spectrum. They also provide a detailed walk-through of many of these models and draw connections between them.
Paper Link: Efficient Transformers: A Survey
In the section 2, authors reviewed the background of the well-established Transformer architecture. Transformers are multi-layered architectures formed by stacking Transformer blocks on top of one another.
I really like the 2.4 section, when the authors summarised the the differences in the mode of usage of the Transformer block. Transformers can primarily be used in three ways, namely:
- Encoder-only (e.g., for classification)
- Decoder-only (e.g., for language modelling, GPT2/3)
- Encoder-decoder (e.g., for machine translation)
In section 3, they provide a high-level overview of efficient Transformer models and present a characterization of the different models in the taxonomy with respect to core techniques and primary use case. This is the core part of this paper covering 17 different papers’ technical details.
Summary of Efficient Transformer Models presented in chronological order of their first public disclosure.
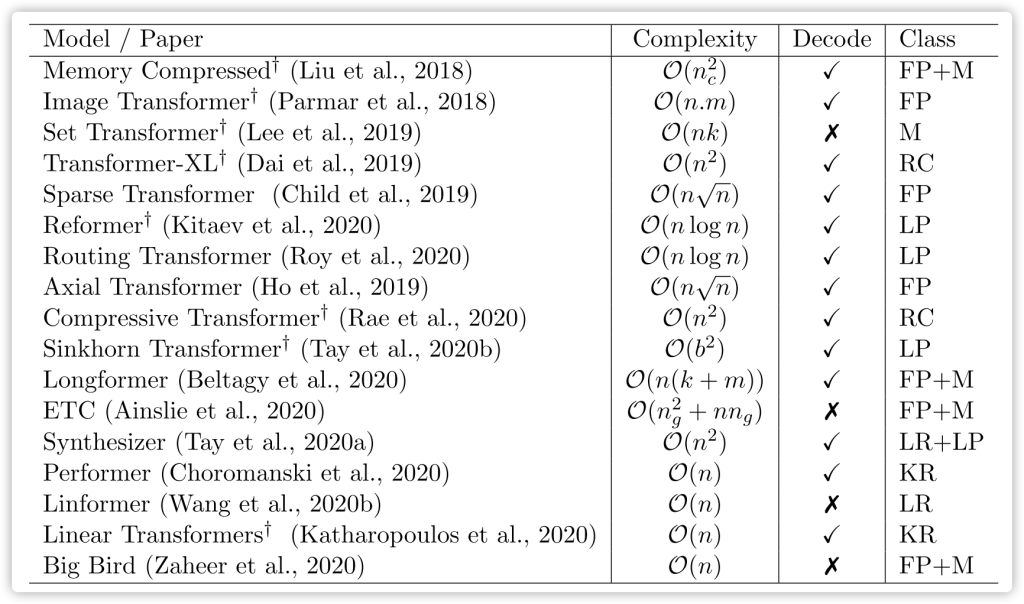
In the last section, authors address the state of research pertaining to this class of efficient models on model evaluation, design trends, and more discussion on orthogonal efficiency effort, such as Weight Sharing, Quantization / Mixed precision, Knowledge Distillation, Neural Architecture Search (NAS) and Task Adapters.
In sum, this is a really good paper summarised all the important work around the Transformer model. It is also a good reference for researcher and engineering to be inspired and try these techniques for different models in their own projects.
FYI, here is my early post The Annotated Transformer: English-to-Chinese Translator with source code on GitHub, which is an “annotated” version of the 2017 Transformer paper in the form of a line-by-line implementation to build an English-to-Chinese translator via PyTorch ML framework.
-END-
Reference:
Efficient Transformers: A Survey (https://arxiv.org/abs/2009.06732)

