Computers armed with GPUs have been keeping making new records on every benchmark data sets of the general machine learning tasks including images/video recognition and language process. The GPU is the hero of all these results for lowering the computing cost today. Although, it is impossible to predict the future, but it is considered the fast developed GPU technologies begin to maximize their benefits and no tech company wants to be lifted behind.
In 2016, I sold my iMac and used the money to buy myself a Dell Alienware Alpha R2 with GeForce GTX 960 at a proper price. I know it is not GTX1080, but hey, it is still pretty awesome to get rid of the intel iris 5000 serious. Because all the machine learning tasks are using Nvidi a’s products, such as the Tesla, Titan, and DGX-1. As a grad student, I just can’t afford these supercomputing devices, the Dell Alpha is just good enough for me.
a’s products, such as the Tesla, Titan, and DGX-1. As a grad student, I just can’t afford these supercomputing devices, the Dell Alpha is just good enough for me.
In this weekend, I ran a benchmark test of my GTX960, and I would like to share some results with all the readers. The following is my GPU Comparison Report: GeForce GTX 960. The software used in the report is Matlab 2016b with the Parallel toolbox and CUDA 8.0. The Matlab code: GPUBench;
Summary of results:
The table and chart below show the peak performance of various GPUs using the same MATLAB version. Your results (if any) are highlighted in bold in the table and on the chart. Al l other results are from pre-stored data. The peak performance shown is usually achieved when dealing with extremely large arrays. Typical performance in day-to-day use will usually be much lower. Results captured using the CPUs on the host PC (i.e. without using a GPU) are included for comparison. Since MATLAB works mostly in double precision the devices are ranked according to how well they perform double-precision calculations. Single precision results are included for completeness. For all results, higher is better.
l other results are from pre-stored data. The peak performance shown is usually achieved when dealing with extremely large arrays. Typical performance in day-to-day use will usually be much lower. Results captured using the CPUs on the host PC (i.e. without using a GPU) are included for comparison. Since MATLAB works mostly in double precision the devices are ranked according to how well they perform double-precision calculations. Single precision results are included for completeness. For all results, higher is better.

The following links are the report ofeachreport:
- gpu_bench_report_pdf;
- gpu-comparison-report_-geforce-gtx-960;
- gpu-performance-details_-geforce-gtx-960;
- gpu-performance-details_-host-pc;
- gpu-performance-details_-quadro-600;
- gpu-performance-details_-tesla-k20m;
- gpu-performance-details_-tesla-k20m;
- gpu-performance-details_-tesla-k40c;
- gpu-performance-details_-tesla-m2075;
The full HTML and PDF versions of these reports could be downloaded in the links below:
- gpu_bench_report_html( 1.82 MB);
- gpu_bench_report_pdf (3.24 MB);

According to the table, my host PC did a much better job on double data type computing, but for single data type computing, GTX960 is far beyond the host. I guess the reason for this maybe I install a 16GB RAM for my PC, while GTX960 only got 4GB memory. But it shows me that if I want to use GPU to accelerate the computing on my machine, I would better to use single data type. In many works, this does not affect the conclusion or the final results.
GPU Performance Details: GeForce GTX 960
System Configuration
Host
Name Intel(R) Core(TM) i5-6400T CPU @ 2.20GHz
Clock 2201 MHz
Cache 1024 KB
NumProcessors 4
OSType Windows
OSVersion Microsoft Windows 10 Home
GPU
Name GeForce GTX 960
Clock 1.200500e+03 MHz
NumProcessors 8
ComputeCapability 5.2
TotalMemory 4.00 GB
CUDAVersion 8
DriverVersion 6.14.13.6930 (369.30)
Results for MTimes (double and single)
These results show the performance of the GPU or host PC when calculating a matrix multiplication of two NxN real matrices. The number of operations is assumed to be 2*N^3 - N^2 This calculation is usually compute-bound, i.e. the performance depends mainly on how fast the GPU or host PC can perform floating-point operations.


Results for Backslash (double and single)
These results show the performance of the GPU or host PC when calculating the matrix left division of a NxN matrix with a Nx1 vector. The number of operations is assumed to be 2/3*N^3 + 3/2*N^2. This calculation is usually compute-bound, i.e. the performance depends mainly on how fast the GPU or host PC can perform floating-point operations.


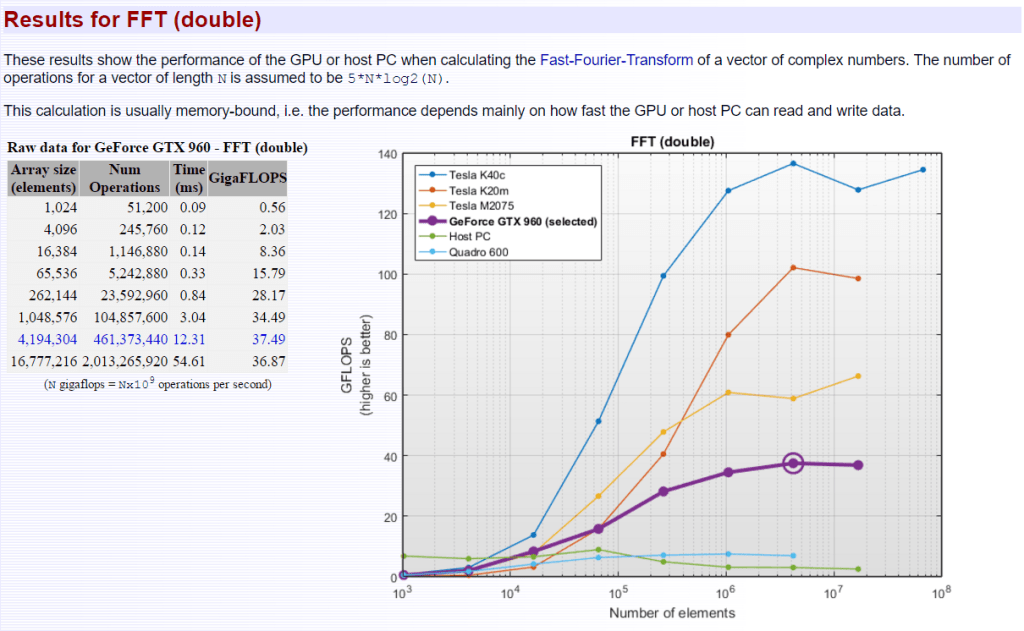
Results for FFT (double and single)
These results show the performance of the GPU or host PC when calculating the Fast-Fourier-Transform of a vector of complex numbers. The number of operations for a vector of length N is assumed to be 5Nlog2(N). This calculation is usually memory-bound, i.e. the performance depends mainly on how fast the GPU or host PC can read and write data.


-End-
