If you’re still comparing ChatGPT, Gemini, and Claude as three chatbots, the AI world of 2026 probably looks a bit strange to you.
Today’s real competition is no longer about “who answers more like a human” or “who memorizes more knowledge.” What OpenAI GPT-5.5, Google Gemini 3.1 Pro, and Anthropic Claude Opus 4.7 represent are three increasingly complete AI work systems: they read text, look at images, understand long documents, write code, call tools, operate browsers, and even attempt to take over parts of complex office, engineering, and research processes.
In other words, the model war has shifted from “who is smarter in the chat box” to “who can more stably help people complete real-world tasks.”
This article, based on publicly available technical reports, system cards, model documentation, and release materials from OpenAI, Google DeepMind, and Anthropic, discusses the differences between the three flagship models: how much of their architecture is actually disclosed, how their training and alignment methods differ, what applications they are respectively suited for, and why the product entry point is more important than the model name itself.
- Don’t Rush to Compare: Models and Products are Not the Same
- The Three “Vibes” are Actually Quite Different
- Architectural Details? Don’t Ask, It’s Confidential
- Training Methods: Similar Frameworks, Different Post-training Philosophies
- 1M Context is Impressive, But Don’t Deify It
- How to Choose: Don’t Ask Who is Strongest, Ask What You Want to Do
- The Real Difference is in the Product Form
- Main References
Don’t Rush to Compare: Models and Products are Not the Same
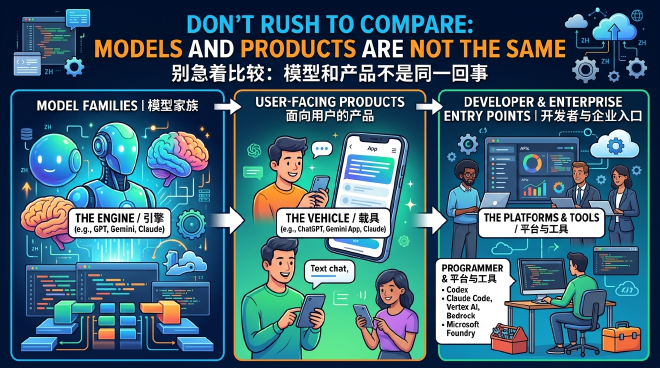
Many discussions start by getting things mixed up: Is GPT the same as ChatGPT? Is Gemini a model or an app? What is the relationship between Claude Code and Claude?
A useful way to understand this without getting confused is:
- GPT, Gemini, and Claude are model families.
- ChatGPT, Gemini App, and Claude are user-facing products.
- Codex, Claude Code, Vertex AI, Bedrock, and Microsoft Foundry are entry points for developers, enterprises, and cloud platforms.
So, if we say “GPT-5.5 is very strong,” we are strictly saying that a certain underlying model from OpenAI has strong capabilities. If we say “ChatGPT is very useful,” we are saying that a whole set of product experiences—including the model, tools, file handling, browser capabilities, UI, memory, and enterprise permissions—is useful.
This is especially important in 2026. While the model itself is crucial, what truly determines whether a user opens it every day is often the product layer: Can it connect to your documents? Can it read code repositories? Can it run tests? Can it break down and complete a complex task? Can it get a “yes” from the security team in an enterprise environment?
The Three “Vibes” are Actually Quite Different

If we summarize it in one sentence:
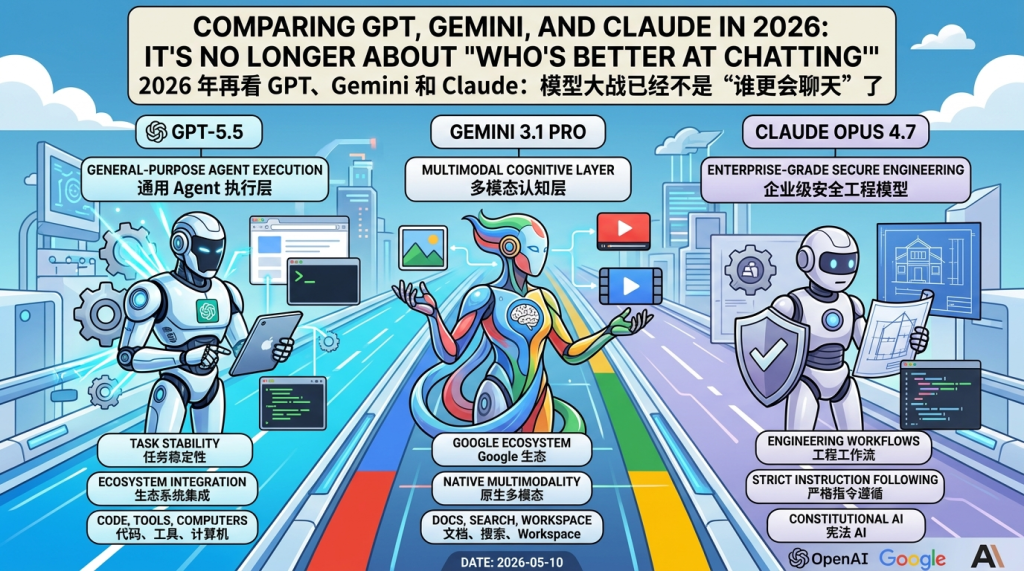
GPT-5.5 is like a general-purpose Agent execution layer, Gemini 3.1 Pro is like a multimodal cognitive layer in the Google ecosystem, and Claude Opus 4.7 is like an enterprise-grade secure engineering model.
OpenAI’s path is obvious: pushing GPT toward real work. GPT-5.5’s public materials emphasize coding, browser/tool use, computer use, knowledge work, and scientific research tasks. It’s not just about answering “why this code is wrong,” but closer to “I will read the repository, change the code, run tests, and explain the results.” ChatGPT, Codex, and APIs together form OpenAI’s main battlefield.
Google Gemini’s advantage feels more like “I have the entire Google universe.” From the start, Gemini has emphasized native multimodality: text, images, audio, and video, with long context as its core route. With Gemini 3.1 Pro, this route is combined with the Gemini App, Gemini API, Vertex AI, NotebookLM, Google Workspace, Android, and Cloud. The value is not just the model itself, but how many Google-owned work scenarios it can enter.
Anthropic Claude has a more restrained and enterprise-oriented vibe. The public narrative for Claude Opus 4.7 focuses on long-range software engineering, strict instruction following, high-resolution vision, security protection, and the Claude Code/API ecosystem. It doesn’t necessarily need a presence in every consumer-grade entry point, but it’s well-suited for scenarios where “this task is long, expensive, and sensitive—don’t mess it up.”
Architectural Details? Don’t Ask, It’s Confidential
If you care about underlying architecture, the bad news is that all three flagship models are highly secretive.
Google has disclosed relatively more in its historical technical reports among the three. Gemini 1.5 Pro explicitly stated it was a sparse Transformer based on Mixture-of-Experts (MoE). Simply put, MoE is like a team of experts: not all parameters are involved in every token’s calculation; instead, a routing mechanism calls specific “experts.” This allows for expanding the total parameter scale while controlling the actual computation activated for each inference.
However, for Gemini 3.1 Pro, Google has not laid out its entire internal structure. What it has disclosed are capabilities, input/output modalities, context windows, tool calls, and product entry points—not parameter counts, expert numbers, routing strategies, or training token counts.
OpenAI is similar. GPT-4 was publicly described as a Transformer-style model, GPT-4o as an autoregressive omni model, and GPT-5.5 has disclosed task capabilities, safety system cards, API availability, and some infrastructure co-design. But the things architecture enthusiasts are most curious about—parameter count, whether it’s MoE, training computation, data ratios, and parallel strategies—have not been fully answered officially.
Anthropic’s disclosure of the underlying structure of Claude Opus 4.7 is also limited. The company prefers to talk about capabilities, safety assessments, context windows, vision capabilities, enterprise workflows, and risk governance, rather than telling you whether it’s a dense model or a sparse expert model.
So, if someone says with great certainty that “model X must have Y parameters” or “flagship Z definitely uses a certain MoE structure,” it’s best to first ask: what is the official source?
Training Methods: Similar Frameworks, Different Post-training Philosophies
From public materials, the basic training paths of the three are not entirely incomprehensible.
The underlying framework is almost certainly the Transformer series. OpenAI’s explanation for GPT-4 is the most direct: the base model is trained to predict the next token in a document. Although GPT-4o expanded to omni forms like text, vision, and audio, it still follows the autoregressive model route. Google’s public materials don’t always use the same blunt language to describe next-token prediction, but the Gemini 1.5 report uses terms like next-token, NLL, and long-context prediction, keeping it firmly in the autoregressive Transformer family. The full training details of Claude Opus 4.7 are not public, but its narrative is also built on large-scale pre-training, post-training alignment, and long-task tool use.
The real interest lies in post-training and alignment.
OpenAI’s historical RLHF process is the most fully disclosed. The InstructGPT paper gave the classic three steps: supervised fine-tuning with human demonstrations, training a reward model, and finally optimizing model behavior with reinforcement learning methods like PPO. Public materials for GPT-4, GPT-4o, and GPT-5.5 no longer lay out all engineering details, but the system card, Preparedness Framework, and Model Spec show how they handle safety, refusal, conflicting instructions, risky topics, and product-layer behavioral norms.
Google Gemini’s public focus is more on production systems: multimodal training, long context, safety filtering, red teaming, and enterprise governance. Elements like instruction tuning, SFT, human preference data, and RLHF can be seen in the Gemini 1.5 report, but Google hasn’t detailed specific PPO, DPO, RLAIF, or preference optimization implementations.
Anthropic has the most distinct label: Constitutional AI. The core idea is not just having humans rate the model, but giving the model a set of principles to use for self-criticism and revision of its answers, then using AI feedback to form preference signals. This is the “helpful, harmless, honest” path Anthropic often mentions. For Claude Opus 4.7, the specific production training recipe remains confidential, but Anthropic discloses more about safety assessments, behavioral reliability, resistance to prompt injection, Responsible Scaling Policy, and protection in high-risk scenarios.
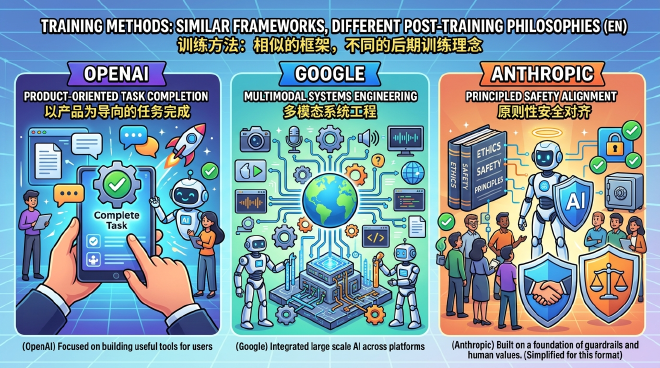
The shortest conclusion is: all three do pre-training and post-training; OpenAI is more about a product-oriented task completion route, Google is more about a multimodal systems engineering route, and Anthropic is more about a principled safety alignment route.
1M Context is Impressive, But Don’t Deify It
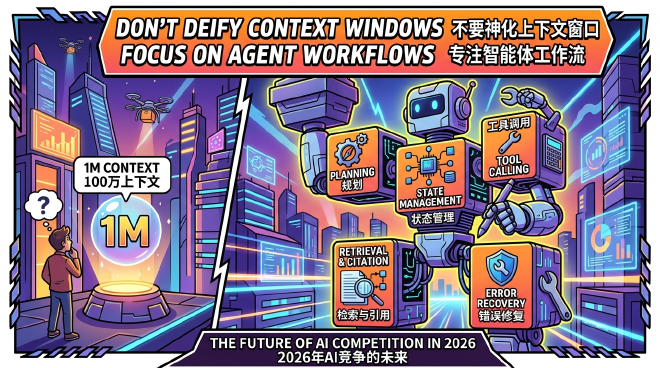
Another shared keyword for 2026 flagship models is ultra-long context.
The Gemini 3 Pro model page mentions 1M input and 64k output; GPT-5.5 API also enters the 1M context era; and Claude Opus 4.7’s official page similarly specifies a 1M context window. It looks spectacular, as if you can finally throw an entire project, a whole book, or a pile of meeting notes into the model at once.
This is certainly useful. Long context allows models to handle large codebases, long reports, multi-file contracts, research materials, and cross-modal content. For engineering, law, consulting, research, and enterprise knowledge management, this is no small upgrade.
However, long context does not equal long reasoning quality. Being able to “stuff it in” doesn’t mean “understanding it well,” and being able to find the “needle” doesn’t mean being able to complete complex multi-step decision-making. A model can have a 1M window but still miss key constraints in ultra-long materials, confuse priorities, or start to become loose in the second half.
A more realistic view is: 1M context is an infrastructure threshold, not the final answer. What truly matters are retrieval, citation, planning, tool calling, state management, and error recovery capabilities. This is also why the competition in 2026 is shifting more toward Agent workflows rather than just context window numbers.
How to Choose: Don’t Ask Who is Strongest, Ask What You Want to Do
If you primarily write code, debug, refactor, and handle engineering automation, GPT-5.5 and Claude Opus 4.7 are top candidates. GPT-5.5’s advantage lies in its general toolchain, integration with ChatGPT/Codex/API, and product capabilities for real-world tasks. Claude Opus 4.7’s strength lies in long-range software engineering, strict instruction following, and a sense of security in enterprise scenarios.
If your tasks involve a lot of multimodality, long documents, video, audio, Google Workspace, or Google Cloud, Gemini 3.1 Pro’s path is very attractive. Its most natural stage is not an isolated chat box, but Google’s ecosystem of Docs, Search, NotebookLM, Vertex AI, and cloud workflows.
If you are doing compliance, risk control, long-task auditing, code review, or rigorous text processing in an enterprise, Claude Opus 4.7’s positioning is very clear: less flash, more stability. Its brand narrative has always revolved around safety alignment, reliability, and enterprise workflows.
If you are an individual user wanting to write, analyze data, generate files, do daily office work, and various temporary automations, ChatGPT / GPT-5.5 remains one of the most convenient general productivity entry points. Not because it is absolutely number one in every single point, but because the product layer combines many capabilities together.
The Real Difference is in the Product Form
Many people like to ask: “Whose model architecture is more advanced?”
This question is important, but public data cannot currently provide a complete answer. None of the three have disclosed enough details to replicate flagship model training. Parameter counts, training token counts, training FLOPs, optimizers, learning rate schedules, and parallel splitting strategies are basically in a black box.
What we can more reliably judge are their publicly disclosed design orientations:
- Gemini is more willing to talk about model families, multimodality, long context, and systems engineering.
- OpenAI is more willing to talk about real work, tool use, product behavioral norms, and safety system cards.
- Anthropic is more willing to talk about principled alignment, long-task reliability, enterprise security, and risk governance.
Behind this are actually three market routes.
Google wants to put Gemini into the ecosystem it already owns. OpenAI wants to turn GPT into a general Agent and productivity entry point. Anthropic wants to make Claude a trusted engineering and knowledge work partner for enterprises.
By 2026, AI models are no longer like the early days, where they just needed to seem smart in a chat box. The real competition is who can stably deliver capabilities into complex scenarios: reading a bunch of materials, understanding context, calling tools, writing code, modifying files, checking results, respecting boundaries, and getting the job done.
This is why the comparison of GPT-5.5, Gemini 3.1 Pro, and Claude Opus 4.7 doesn’t end with a simple ranking.
It’s more like three answers:
- For general Agents and productivity workflows, look at GPT-5.5 / ChatGPT / Codex.
- For multimodality, long context, and the Google ecosystem, look at Gemini 3.1 Pro.
- For long-range engineering, safety alignment, and enterprise reliability, look at Claude Opus 4.7.
Stop asking “who is better at chatting.” The questions for 2026 are: who is more capable of doing the work, who is better suited for your workflow, and who can get the job done without overcomplicating things.



Leave a comment