
There are lots of articles and blogs explaining how AlphaGo works, such as, the DeepMind official page AlphaGo, the academic paper on Nature: Mastering the game of Go with deep neural networks and tree search [pdf], and the post for general people Google DeepMind’s AlphaGo: How it works.
Part I
In the previous competitions of AlphaGo, a lot of people might have noticed that there is a pattern of AlphaGo, which is that it rarely made “good moves”, which I mean aggressive moves like human players will do in games. It feels like AlphaGo prefers gentle moves.
But why?
Assuming that you have already known that the kernels of AlphaGo are two neural networks, the first one, ‘value networks’, is used to evaluate board positions and another one, ‘policy networks’, is used to select moves.
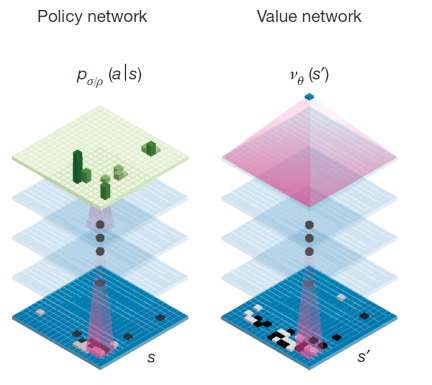
When training a neural network model, the most important step is to define a cost function that generates a numerical value as a feedback to tell the model which decision is the best.
There is an important detail in the design of AlphaGo, that the cost function or feedback function is only focusing on Wining/ Losing the game. In other words, winning 1 points and winning 10 points are the same results, AlphaGo just wants to win.
However, in practice, that simply focusing on winning the game actually means giving up a big win, that is winning the game with more points than the opponent. Because for a multivariate optimization problem (as Go ), on the marginal area, the different optimization goals are always contradictory to each other. For example, assuming we are in a middle game, in the next move there are three options:
- A. win 10 points with probability 70%;
- B. win 1 points with probability 80%;
- C. win 2 points with probability 90%.
Obvious, B is a bad move comparing to C, we just drop it directly.
However, which one is our best move between A and C? Clearly, C is an option with high winning rate but less winning points. This is the typical Pareto optimization problem. B is not a solution, or it is not close enough to the marginal area of the optimization surface. While in that area with regards to A and C, the winning rate and winning points are contradictory.
That is not to say, that pursuing winning leads to winning with fewer points. In fact, in almost every game, more winning points will lead to the same results. One move causing the winning points drop will certainly cause the winning rate drop. The worthy moves are always contradictory in the Go game, the stronger the opponents is, the larger difference of the two goals will be there.
Since AlphaGo is focusing on winning the game, so it will choose the move C with higher winning rate rather than A with winning a lot of points. Winning is all it cares.
You may wonder why our human players (at least most of the players) do not play Go in this strategy? Because it is not suitable for the human brain. AlphaGo can do this because it can perform very accurate calculations, which help it maintain advantages in every step of the game. Just like a bird flying over the surface of the sea, it may be dangerous but it saves a lot of energy. Our human could never do accurate calculations, even those math genius could not compete with computers, so we have to keep enhancing advantages in every move to enlarge the winning points, to keep ourselves in a safe zone to avoid losing the game with one mistake.
This is the reason why AlphaGo plays strong moves with a strong human opponent, and it barely makes “smart move”. In human’s point of view, sometimes it makes non-optimal moves in the local areas to pursuit winning rate of the game. In the contrary, we human see fighting and winning a local area on the Go board is a very positive action for winning the game. However, in the AlphaGo’s opinion, those movies are just increasing uncertainties of the game.
I can not help to think that what if AlphaGo is trained with a very different cost function. Let us image there is a BetaGo, its every aspect is the same with AlphaGo, except the cost function. We modify it to win the game with more points on the board (from a step function (0-1) to a linear function (-361 to 361 points).
We could guess that the BetaGo’s playing style will be more aggressive than AlphaGo, it wants more kills and more fights to get more winning points. If we make BetaGo battles against AlphaGo, I guess AlphaGo will win more games than BetaGo, but generally, BetaGo will win more points that AlphaGo.
Or let us make it more exciting, update the feedback function into the square function of the winning points or exponential function of the points, what crazy Go player model will be generated?
By reading the AlphaGo paper, the design and algorithm are understandable right now. Because DeepMind is just trying to prove that AI could beat Human on Go. What unexpected is that the current version of AlphaGo is already far ahead of our human players, so even the imaginary BetaGo, that has a low winning rate, will beat human eventually. What a pity, it is not BetaGo fighting against Sedol Lee!
Part II and III
Plan to talk about AlphaGo and AI.
Who will be the Go Master?
Do we human start to learn from the machine and evolve with it on the Go game?
Or we just created a Go Master that human will never beat it in the future?
If this happens, how many of us would still play Go if knowing we will lose in the end no matter how hard we try?
To be continued…
